Ransac-Algorithmus – Wikipedia Wikipedia
Ransac ( Anglais couru dom sur mère c insensible , L’allemand, par exemple, “l’accord avec un échantillon aléatoire”) est un algorithme de rééchantillonnage pour estimer un modèle dans une série de valeurs mesurées avec des valeurs aberrantes et des erreurs brutes. En raison de sa robustesse envers les valeurs aberrantes, il est principalement utilisé dans la zone informatique de la vision de l’ordinateur. Ici, Ransac prend en charge – en calculant une quantité de données ajustées au SO Ensembles de consensus – Procédure de compensation telle que la méthode des plus petits carrés, qui échouent généralement avec un plus grand nombre de valeurs aberrantes.
Ransac a été officiellement présenté en 1981 par Martin A. Fischler et Robert C. Bolles dans les communications de l’ACM. Une présentation interne à l’International SRI, sur lequel les deux auteurs ont travaillé, [d’abord] [2] déjà eu lieu en mars 1980. [3] Une alternative à Ransac sont les M-estimateurs. Par rapport à d’autres estimations, telles que l’estimateur maximal du likelihood, ceux-ci sont plus robustes.
Ransac est basé sur des sous-échantillonnage aléatoire répété [4] .
À la suite d’une mesure, il existe souvent des points de données qui représentent des valeurs physiques telles que la pression, la distance ou la température, les tailles économiques ou similaires. Une courbe de modèle, qui est aussi précise que possible, doit être placée dans ces points. Il y a plus de points de données que nécessaire pour déterminer les paramètres; Le modèle est donc dépassé. Les valeurs mesurées peuvent contenir des valeurs aberrantes, c’est-à-dire des valeurs qui ne s’intègrent pas dans la série attendue de mesures. Étant donné que les mesures ont été principalement effectuées manuellement jusqu’à ce que le développement de la technologie numérique, le contrôle par le chirurgien a fait que la proportion de valeurs aberrantes était principalement faible. Les salgorithmes de compensation utilisés à l’époque, tels que la méthode des plus petits carrés, sont bien adaptés à l’évaluation de ces enregistrements de données avec peu de valeurs aberrantes: avec leur aide, le modèle est d’abord déterminé avec l’intégralité des points de données puis essaie de détecter les valeurs aberrantes.


Avec le développement de la technologie numérique du début des années 80, les bases ont changé. En raison des nouvelles possibilités, les méthodes de mesure automatiques ont été de plus en plus utilisées, en particulier dans la zone de l’ordinateur. En conséquence, il existe souvent un grand nombre de valeurs, qui contient généralement de nombreuses valeurs aberrantes. Les procédures traditionnelles supposent une distribution normale des erreurs et ne fournissent parfois pas de résultat raisonnable si les points de données contiennent de nombreuses valeurs aberrantes. Ceci est illustré dans la représentation opposée. Une ligne droite (le modèle) doit être adaptée aux points (valeurs mesurées). La valeur aberrante individuelle en dessous des 20 points de données peut, d’une part, être exclue au moyen de procédures traditionnelles avant de déterminer celle. D’un autre côté, en raison de son emplacement, il influence la pérézation droite de manière disproportionnée (effet de levier si appelé).
L’algorithme Ransac suit une nouvelle approche itérative. Au lieu de compenser toutes les valeurs mesurées ensemble, seulement autant de valeurs sélectionnées au hasard sont utilisées, comme nécessaire pour calculer les paramètres du modèle (en cas de ligne droite qui serait de deux points). Il est initialement supposé que les valeurs sélectionnées ne sont pas des valeurs aberrantes. Cette hypothèse est vérifiée en calculant d’abord le modèle à partir des valeurs sélectionnées au hasard, puis en déterminant la distance de toutes les valeurs mesurées (c’est-à-dire non seulement la sélectionnée à l’origine) à ce modèle. Si la distance d’une valeur mesurée au modèle est inférieure à un seuil précédemment défini, cette valeur mesurée par rapport au modèle calculé n’est pas une erreur brute. Il les soutiens Donc ça. Plus les valeurs sont mesurées prennent en charge le modèle, plus les valeurs sélectionnées par hasard ne contenaient pas de valeurs aberrantes pour le calcul du modèle. Ces trois étapes – sélection aléatoire des valeurs mesurées, calcul des paramètres du modèle et détermination du support – sont répétés plusieurs fois indépendamment. Dans chaque itération, il est enregistré, les valeurs mesurées prennent en charge le modèle respectif. Ce montant sera Ensemble de consensus appelé. Du plus grand Ensemble de consensus , Idéalement ne contient plus de valeurs aberrantes, la solution est finalement déterminée avec l’une des procédures de compensation traditionnelles.
Comme mentionné, de nombreuses valeurs aberrantes se produisent en particulier dans le cas des mesures automatiques. Ceux-ci sont souvent effectués dans la zone informatique, de sorte que Ransac est particulièrement répandu ici. Certaines applications sont présentées ci-dessous.


Dans le traitement d’image, Ransac est utilisé pour déterminer les points homologues entre deux images de caméra. Les homologues sont les deux pixels qui créent un seul point d’objet dans les deux images. L’attribution des points d’homologue est appelée problème de correspondance. Le résultat d’une analyse automatique contient généralement un plus grand nombre d’échecs. Les procédures d’utilisation de Ransac qui se sont installées sur le résultat de l’analyse de correspondance pour exclure la défaillance. Un exemple de cette procédure est la création d’une image panoramique de divers plans individuels plus petits (couture). [5] Un autre est le calcul de la géométrie épipolaire. Il s’agit d’un modèle de géométrie qui représente les relations géométriques entre différentes images de caméra du même objet. Ici, Ransac sert à déterminer la matrice fondamentale, qui décrit la relation géométrique entre les images.
Chez Darpa Grand Challenge, une compétition pour les véhicules terrestres autonomes, Ransac a été utilisé pour déterminer le niveau de la route et reconstruire le mouvement du véhicule. [6]
L’algorithme est également utilisé pour adapter les corps géométriques tels que les cylindres ou similaires en quantités de points à trois dimensions bruyantes ou pour segmenter automatiquement les nuages ponctuels. Tous les points qui n’appartiennent pas au même segment sont considérés comme des valeurs aberrantes. Selon une estimation du corps le plus dominant dans le nuage de points, tous les points appartenant à ce corps sont supprimés afin de pouvoir déterminer plus de corps à l’étape suivante. Ce processus est répété jusqu’à ce que tous les corps aient été trouvés au montant du point. [7]
La condition préalable pour Ransac est qu’il y a plus de points de données que nécessaire pour déterminer les paramètres du modèle. L’algorithme se compose des étapes suivantes:
- Sélectionnez autant de points dans les points de données si nécessaire pour calculer les paramètres du modèle. Cela est prévu que ce montant soit exempt de valeurs aberrantes.
- Déterminez les paramètres du modèle avec les points sélectionnés.
- Déterminez le sous-ensemble des valeurs mesurées, la distance à la courbe du modèle qui est inférieure à une certaine limite (ce sous-ensemble sera Ensemble de consensus appelé). S’il contient un certain nombre minimum de valeurs, un bon modèle a probablement été trouvé et le Ensemble de consensus sera sauvé.
- Répétez les étapes 1 à 3 plusieurs fois.
Après avoir effectué plusieurs itérations, le sous-ensemble qui contient la plupart des points est choisi (car un a été trouvé). Les paramètres du modèle ne sont calculés qu’avec l’une des procédures de compensation habituelles avec ce sous-ensemble. Une variante alternative de l’algorithme termine prématurément les itérations si le modèle prend en charge suffisamment de points à l’étape 3. Cette variante est appelée pré -Counterparers – c’est-à-dire la rupture prématurément – ransac. Avec cette procédure, il doit être connu à l’avance de la taille du contenu aberrant, afin qu’il puisse être évalué si des valeurs mesurées suffisantes soutiennent le modèle.
L’algorithme dépend principalement de trois paramètres:
- La distance maximale d’un point de données du modèle auquel un point n’est pas considéré comme une erreur brute;
- le nombre d’itérations et
- La taille minimale du Ensembles de consensus , c’est-à-dire le nombre minimum de points cohérents avec le modèle.
Distance maximale d’un point de données du modèle [ Modifier | Modifier le texte source ]]
Ce paramètre est fondamental pour le succès de l’algorithme. Contrairement aux deux autres paramètres, il doit être déterminé (une revue du Ensemble de consensus n’a pas besoin d’être effectué et le nombre d’itérations peut être sélectionné presque comme souhaité). Si la valeur est trop grande ou trop petite, l’algorithme peut échouer. Ceci est illustré dans les trois images suivantes. Une étape d’itération est montrée. Les deux points sélectionnés au hasard avec lesquels le modèle vert a été calculé sont colorés en bleu. Les barrières d’erreur sont affichées sous forme de lignes noires. Il doit y avoir un point dans ces lignes pour soutenir le modèle droit. Si la distance est choisie trop grande, trop de valeurs aberrantes ne sont pas reconnues, de sorte qu’un mauvais modèle peut avoir le même nombre de valeurs aberrantes qu’un vrai modèle (Fig. 1A et 1B). S’il est réglé trop bas, il peut se produire qu’un modèle qui a été calculé à partir d’une quantité de valeurs sans hors-la-loi soit pris en charge par trop peu d’autres valeurs qui ne sont pas des valeurs aberrantes (figure 2).
- Problèmes si la barrière d’erreur est trop grande ou trop petite
-

1A. La bonne solution, deux points sont des valeurs aberrantes.
-
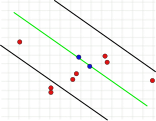
1b. Deuxièmement, une mauvaise solution avec le même nombre de valeurs aberrantes que 1A.
-
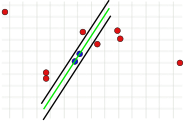
2. Barrière d’erreur trop petite.



Malgré ces problèmes, cette valeur doit généralement être déterminée empiriquement. Ce n’est que si l’écart type des valeurs mesuré est connu que la limite d’erreur peut être calculée en utilisant les lois de la distribution de probabilité.
Nombre d’itérations [ Modifier | Modifier le texte source ]]
Le nombre de répétitions peut être déterminé de telle manière qu’avec une certaine probabilité
p {displaystyle p}Au moins une fois, un sous-ensemble gratuit est sélectionné à partir des points de données. Est
s {DisplayStyle S}

Le nombre de points de données nécessaires pour calculer un modèle, et
ϵ {displaystyle epsilon}

La part relative des valeurs aberrantes dans les données est la probabilité que
n {displaystyle n}

Les répétitions ne sont pas sélectionnées au moins une valeur aberrante à chaque fois


- p = d’abord – (1−(1−ϵ)s)n{displayStyle p = 1-left (1-left (1-epsilon à droite) ^ {s} droit) ^ {n}} ,


Et pour que la probabilité qu’au moins une valeur aberrante soit sélectionnée à chaque fois, au plus
d’abord – p {displayStyle 1-P}Devra
n {displaystyle n}

peut être choisi suffisamment grand. Devenez plus précisément au moins
- n = log(1−p)log(1−(1−ϵ)s){displayStyle n = {frac {log Left (1-pright)} {log gauche (1-left (1-epsilon à droite) ^ {s} droit)}}}


Répétitions nécessaires. Le nombre ne dépend donc que de la proportion de valeurs aberrantes, du nombre de paramètres de la fonction du modèle et de la probabilité donnée du dessin au moins un sous-ensemble sans valeur aberrante. Il est indépendant du nombre total de valeurs mesurées.
Dans le tableau ci-dessous, le nombre nécessaire de répétitions dépend du contenu aberrant et du nombre de points nécessaires pour déterminer les paramètres du modèle. La probabilité de sélectionner au moins un sous-ensemble sans aperçu de tous les points de données est définie à 99%.
| Exemple | nombre de points requis |
Aberrant | ||||||
|---|---|---|---|---|---|---|---|---|
| dix % | 20% | 30% | 40% | 50% | 60% | 70% | ||
| Droit | 2 | 3 | 5 | 7 | 11 | 17 | 27 | 49 |
| niveau | 3 | 4 | 7 | 11 | 19 | 35 | 70 | 169 |
| Fondamentalmatrix | 8 | 9 | 26 | 78 | 272 | 1177 | 7025 | 70188 |


Taille de l’ensemble de consensus [ Modifier | Modifier le texte source ]]
Dans la variante générale de l’algorithme, cette valeur ne doit pas nécessairement être connue, car s’il n’y a pas de contrôle de plausibilité, le plus grand Ensemble de consensus peut être utilisé dans le cours plus approfondi. Cependant, ses connaissances sont nécessaires à la variante prématurée. Avec cela la taille minimale du Ensemble de consensus principalement déterminé analytiquement ou expérimentalement. Une bonne approximation est la quantité totale des valeurs mesurées, moins la proportion de valeurs aberrantes
ϵ {displaystyle epsilon}qui est suspecté dans les données. Pour
n {displaystyle n}Les points de données sont les mêmes que la taille minimale
( d’abord – ϵ ) ⋅ n {displayStyle (1-epsilon) cdot n}. Par exemple, avec 12 points de données et 20% de valeurs aberrantes, la taille minimale est d’environ 10.


La proportion de valeurs aberrantes dans la quantité totale des points de données est souvent inconnue. Il n’est donc pas possible, le nombre d’itérations requis et la taille minimale de une Ensemble de consensus déterminer. Dans ce cas, l’algorithme est initialisé avec la pire hypothèse d’une part aberrante de 50%, par exemple, et le nombre d’itérations et la taille de la Ensemble de consensus calculé en conséquence. Après chaque itération, les deux valeurs sont ajustées lorsqu’une quantité cohérente plus grande a été trouvée. Par exemple, l’algorithme est lancé avec un ripper de 50% et contient le calculé Ensemble de consensus Mais 80% de tous les points de données se traduisent par une valeur améliorée pour la part de la valeur aberrante de 20%. Le nombre d’itérations et la taille nécessaire du Ensemble de consensus sont ensuite calculés à nouveau.
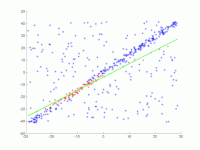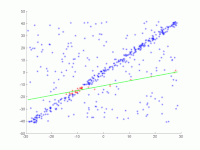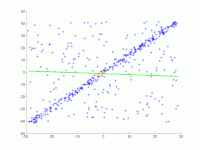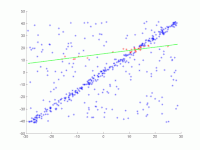
On doit être ajusté dans de nombreux points au niveau. Les points sont affichés dans la première image. Dans la deuxième image, le résultat de divers passages est dessiné. Les points rouges les soutiennent. Les points qui sont supérieurs à la barrière d’erreur sont colorés en bleu. La troisième image montre la solution trouvée après 1000 étapes d’itération.
- Ransac pour adapter un droit à des points de données
-
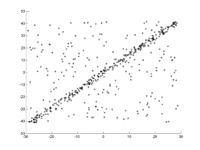
-
2. Animation de plusieurs itérations.
-
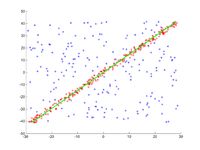
3e résultat après 1000 itérations.

Il y a quelques extensions de Ransac, dont deux sont présentées ici.
Lo-ransac [ Modifier | Modifier le texte source ]]


Il a été démontré dans des expériences que surtout plus d’étapes d’itération que le nombre théoriquement suffisant sont nécessaires: si un modèle est calculé avec une quantité de points sans valeur aberrante, toutes les autres valeurs qui ne sont pas aberrantes ne doivent pas prendre en charge ce modèle. Le problème est illustré dans l’illustration adjacente. Bien qu’ils aient été calculés par deux valeurs sans erreur (points noirs), certains autres points manifestement corrects sont classés en haut à droite de l’image en tant que valeurs aberrantes (étoiles bleues).
Pour cette raison, l’algorithme d’origine de Lo-Ransac (Ransac optimisé local) est élargi à l’étape 3. Premièrement, comme d’habitude, le sous-ensemble des points qui ne sont pas des valeurs aberrantes sont déterminés. Selon cela, le modèle est à nouveau déterminé en utilisant ce montant et à l’aide de tout processus de compensation tel que la méthode des plus petits carrés. Enfin, le sous-ensemble est calculé, la distance à ce modèle optimisé est plus petite que la barrière d’erreur. Seul ce sous-ensemble amélioré sera Ensemble de consensus enregistré. [8]
MSAC [ Modifier | Modifier le texte source ]]
À Ransac, le modèle est sélectionné, qui est soutenu par la plupart des valeurs mesurées. Cela correspond à la minimisation d’une somme
C {DisplayStyle C}, dans lequel toutes les valeurs sans erreur sont reçues avec 0 et toutes les valeurs aberrantes avec une valeur constante:


- C = ∑ ip ( Erreur ) avec p = { 0,wenn Fehler<Fehlerschrankekonstantwenn Fehler≥Fehlerschranke{displayStyle c = sum _ {i} p ({text {error}}) quad {text {with}} quad p = left {{begin {array}} 0, & {text {if Error}}


Le modèle calculé peut être très imprécis si la barrière d’erreur a été réglée trop élevée – plus elle est élevée, plus les solutions ont les mêmes valeurs pour
C {DisplayStyle C}. Dans les cas extrêmes, toutes les erreurs des valeurs mesurées sont plus petites que la barrière d’erreur, de sorte que
C {DisplayStyle C}est toujours 0. Cela signifie qu’aucune valeur aberrante ne peut être reconnue et Ransac offre une mauvaise estimation.
MSAC ( M -Stimateur sur mère C Onensus) est une expansion de Ransac qui utilise une fonction cible à minimiser:
- C = ∑ ip ( Erreur ) avec p = { Fehler,wenn Fehler<Fehlerschrankekonstanter Wert groesser als Fehlerschranke,wenn Fehler≥Fehlerschranke{displaystyle c = sum _ {i} p ({text {error}}) quad {text {with}} quad p = left {{{array}} {text {error,}} & {text {if error}}


Avec cette fonction, les valeurs aberrantes continuent de recevoir une certaine “punition” plus grande que la barrière d’erreur. Les valeurs inférieures à la barrière d’erreur vont directement dans la somme avec l’erreur au lieu de 0. Cela élimine le problème mentionné, car mieux il correspond au modèle, moins le point contribue à la somme. [9]
- ↑ Robert C. Bolles: Page d’accueil à SRI . ( en ligne [Consulté le 11 mars 2008]).
- ↑ Martin A. Fischler: Page d’accueil à SRI . ( en ligne [Consulté le 11 mars 2008]).
- ↑ Martin A. Fischler et Robert C. Bolles: Exemple de consensus aléatoire: un paradigme pour l’ajustement du modèle avec des applications à l’analyse d’image et à la cartographie automatisée . Mars 1980 ( en ligne [PDF; 301 kb ; Consulté le 13 septembre 2007]).
- ↑ Cantzler, H. “Consensus d’échantillon aléatoire (RANSAC).” Institut de perception, d’action et de comportement, Division des informations, Université d’Édimbourg (1981). http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.106.3035&rep=rep1&type=pdf
- ↑ Jour Ewering: Suivi basé sur un modèle à l’aide de corrélations de lignes et de points . Septembre 2006 ( en ligne [PDF; 9.5 Mb ; Consulté le 2 août 2007]).
- ↑ Martin A. Fischler et Robert C. Bolles: Ransac: une perspective historique . 6. juin 2006 ( en ligne [Ppt; 2.8 Mb ; consulté le 11 mars 2008]).
- ↑ Prières chrétiennes und wolfgang en premier: Détermination directe des cylindres à partir de points 3D sans utiliser de norme de surface . 2006 ( Uni-Bonn.de [PDF; Consulté le 25 août 2016]).
- ↑ Ondřej Chum, Jiři Matas et Štěpàn Amélioration de Ransac par optimisation du modèle généralisé . 2004 (en ligne [PDF; consulté le 7 août 2007]).
- ↑ P.H.S. Torr et A. Zisserman: MLESAC: un nouvel estimateur robuste avec une application à l’estimation de la géométrie de l’image . 1996 ( en ligne [PDF; 855 kb ; Consulté le 7 août 2007]).
- Martin A. Fischler et Robert C. Bolles: Exemple de consensus aléatoire: un paradigme pour l’ajustement du modèle avec des applications à l’analyse d’image et à la cartographie automatisée. (PDF; 1,2 Mo) (n’est plus disponible en ligne.) 1981, archivé à partir de Original suis 5. avril 2019 ; Récupéré le 14 octobre 2019 .
- Divers auteurs: 25 ans de Ransac, atelier en collaboration avec CVPR 2006. 2006, Consulté le 11 mars 2008 .
- Peter Kovesi: RANSAC – s’adapte robuste à un modèle aux données avec l’algorithme RANSAC (implémentation MATLAB). 2007, Consulté le 11 mars 2008 .
- Volker Rodehorst: Reconstruction 3D photogrammétrique dans la courte portée par étalonnage automobile avec géométrie projective . WVB Science Verlag Berlin, 2004, ISBN 978-3-936846-83-6 (University Script, Zugl. Dissertation, Tu Berlin 2004).
- Richard Hartley, Andrew Zisserman: Géométrie à vue multiple dans la vision informatique . 2e édition. Cambridge University Press, Cambridge, UK 2004, ISBN 978-0-521-54051-3 (anglais).
- Tilo Bigs: Ajustement des données et incertitude (une introduction pratique aux moindres carrés pondérés et au-delà) . 2e édition édition. Springer Vieweg, 2016, ISBN 978-3-658-11455-8 (anglais).

Recent Comments