Distribution binomiale – Wikipedia
| Distribution binomiale | |
Distribution de probabilité  |
|
Fonction de distribution 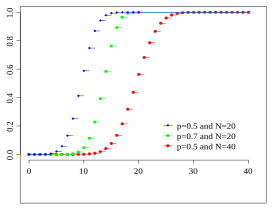 |
|
| Paramètre | , |
|---|---|
| transporteur | |
| Fonction de probabilité | |
| Fonction de distribution | |
| Valeur d’attente | |
| Médian | je. A. Pas de formule fermée, voir ci-dessous |
| Modus | ou |
| Variance | |
| Courbé | |
| Courbure | |
| Entropie | |
| Fonction de génération de moment | |
| Fonction caractéristique | |

![pin [0,1]](https://wikimedia.org/api/rest_v1/media/math/render/svg/33c3a52aa7b2d00227e85c641cca67e85583c43c)













Le Distribution binomiale (aussi: Distribution binominale ) est l’une des distributions de probabilité discrètes les plus importantes.
Il décrit le nombre de succès dans une série d’expériences similaires et indépendantes, chacune ayant exactement deux résultats possibles (“succès” ou “échec”). Ces séries de tests sont également appelées processus de Bernoulli.
Est
La probabilité de succès un Tentative et
 La probabilité de succès un Tentative et
La probabilité de succès un Tentative et Le nombre d’expériences, alors fait référence à
 Le nombre d’expériences, alors fait référence à
Le nombre d’expériences, alors fait référence à (aussi
 (aussi
(aussi ,
 ,
, [d’abord] ou
 [d’abord] ou
[d’abord] ou [2] ) la probabilité de exactement
 [2] ) la probabilité de exactement
[2] ) la probabilité de exactement Pour réussir (voir la définition de la section).
 Pour réussir (voir la définition de la section).
Pour réussir (voir la définition de la section). La distribution binomiale et l’expérience de Bernoulli peuvent être illustrées à l’aide du conseil d’administration de Galton. Il s’agit d’un appareil mécanique dans lequel vous jetez des balles. Ceux-ci tombent alors accidentellement dans l’un des nombreux sujets, avec la division de la distribution binomiale. Selon la construction, il existe différents paramètres
et
possible.
Bien que la distribution binomiale ait été connue bien avant, le terme a été utilisé pour la première fois en 1911 dans un livre de George Udny Yule. [3]
Fonction de probabilité, fonction de distribution (cumulée), propriétés [ Modifier | Modifier le texte source ]]
La distribution discrète de la probabilité avec la fonction de probabilité

signifie que Distribution binomiale Aux paramètres
(Nombre d’expériences) et
(le Succès ou Probabilité ).
![{displaystyle pin left[0,1right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/403c14a696bad2adffdf3b4b91494c89fb043180) (le Succès ou Probabilité ).
(le Succès ou Probabilité ). Un avis: Avec cette formule, la convention est
appliqué (voir zéro zéro élevé).
 appliqué (voir zéro zéro élevé).
appliqué (voir zéro zéro élevé). La formule ci-dessus peut être comprise comme suit: nous avons besoin d’un total de
Essayer exactement
Succès de la probabilité
et donc ont exactement
 et donc ont exactement
et donc ont exactement Échecs de la probabilité
 Échecs de la probabilité
Échecs de la probabilité . Cependant, tout le monde peut
 . Cependant, tout le monde peut
. Cependant, tout le monde peut Succès dans chacun des
Des expériences apparaissent pour que nous soyons toujours avec le nombre
le
 le
le -Ément Sous-coseaux d’un
-Ément Multipliez beaucoup. Parce qu’il y a autant d’options de tout le monde
Essaie le
pour sélectionner réussi.
La probabilité de succès
Probabilité par défaut complémentaire
est souvent avec
 est souvent avec
est souvent avec abrégé.
 abrégé.
abrégé. Si nécessaire pour une distribution de probabilité, les probabilités pour toutes les valeurs possibles doivent
Pour ajouter 1. Cela résulte du taux d’enseignement binomien comme suit:

Un après
Taille aléatoire distribuée
 Taille aléatoire distribuée
Taille aléatoire distribuée Cela signifie en conséquence binomial distribué Avec les paramètres
 Cela signifie en conséquence binomial distribué Avec les paramètres
Cela signifie en conséquence binomial distribué Avec les paramètres et
ainsi que la fonction de distribution
- ,

par lequel
La fonction d’arrondi mentionnée.
 La fonction d’arrondi mentionnée.
La fonction d’arrondi mentionnée. D’autres orthographes courantes de la distribution binomiale cumulée sont
,
 ,
, [4] et
 [4] et
[4] et . [5]
 . [5]
. [5] La dérivation comme une probabilité de Laplace [ Modifier | Modifier le texte source ]]
Schéma expérimental: contient une urne
Les balles sont d’eux
 Les balles sont d’eux
Les balles sont d’eux noir et
 noir et
noir et blanc.
La probabilite
 blanc.
blanc.Tirer une balle noire est ainsi
.
Il y en aura un aléatoire après l’autre
 .
.Balles retirées, leur couleur déterminée et recouverte à nouveau.
Nous calculons le nombre d’options dans lesquelles
Trouver des boules noires, et à partir de celle-ci Probabilité de Laplace (“Nombre d’options pour l’événement, divisé par le nombre total d’options (également)”).
Avec chacun des
Il y a des tirages
Opportunités, donc dans l’ensemble
Possibilités pour la sélection des balles. Si précisément
 Possibilités pour la sélection des balles. Si précisément
Possibilités pour la sélection des balles. Si précisément ce
Les balles sont noires, doivent être précises
le
Tirez une balle noire. Il y a pour chaque balle noire
Opportunités, et pour chaque balle blanche
Possibilités.
Le
Les boules noires peuvent toujours être sur
Façons possibles sur le
Les tirages sont distribués, donc il y a

Cas qui exactement
Les balles noires ont été sélectionnées. La probabilite
, sous
 , sous
, sous Boules exactement
Donc trouver les Noirs est

Cube de jeu [ Modifier | Modifier le texte source ]]
La probabilité de rouler un 6 avec un cube de jeu normal est
. La probabilite
 . La probabilite
. La probabilite que ce n’est pas le cas est
. Supposons que vous rouliez 10 fois (
 . Supposons que vous rouliez 10 fois (
. Supposons que vous rouliez 10 fois ( ), alors la probabilité qu’un 6 ne soit jamais roulé,
 ), alors la probabilité qu’un 6 ne soit jamais roulé,
), alors la probabilité qu’un 6 ne soit jamais roulé, . La probabilité qu’un 6 soit roulé exactement deux fois
 . La probabilité qu’un 6 soit roulé exactement deux fois
. La probabilité qu’un 6 soit roulé exactement deux fois . En général, la probabilité
 . En général, la probabilité
. En général, la probabilité -Sument un nombre roul
, à travers la distribution binomiale
 , à travers la distribution binomiale
, à travers la distribution binomiale décrit.
 décrit.
décrit. Souvent, le processus décrit par la distribution binomiale est également illustré par un modèle d’urne si appelé. Dans une urne, z. B. 6 balles, 1 d’entre eux blancs, les autres noirs. Maintenant, atteignez l’urne 10 fois, sortez une balle, notez leur couleur et couvrez à nouveau le ballon. Dans une interprétation spéciale de ce processus, tirer une balle blanche est comme événement positif Avec la probabilité
compris, tirant une balle non blanche comme événement négatif . Les probabilités sont tout aussi distribuées que dans l’exemple avec le cube de jeu.
tissu de monnaie [ Modifier | Modifier le texte source ]]
Une pièce est lancée 7 fois. Lorsque la variable aléatoire discrète
Le nombre de portées comptes, avec laquelle le “nombre” est lancé
La distribution binomiale

Les valeurs et leurs probabilités peuvent être résumées dans le tableau suivant:
La valeur des attentes est
- .

La variance est donc donnée par

Avec l’ensemble de décalage, vous obtenez également la même valeur pour la variance:
- .

Il en résulte l’écart type:
- .

symétrie [ Modifier | Modifier le texte source ]]
- La distribution binomiale est dans les cas spéciaux , et symétrique et autrement asymétrique.
- La distribution binomiale a la propriété




Valeur d’attente [ Modifier | Modifier le texte source ]]
La distribution binomiale a la valeur d’attente
.
Preuve
La valeur des attentes
Calculer directement à partir de la définition
 Calculer directement à partir de la définition
Calculer directement à partir de la définition Et le taux d’enseignement binomique aussi
 Et le taux d’enseignement binomique aussi
Et le taux d’enseignement binomique aussi 
Alternativement, vous pouvez en utiliser un
-Révacte aléatoire distribué
Comme une somme de
Bernoulli indépendant distribué des variables aléatoires
avec
 avec
avec peut être écrit. Suit ensuite avec la linéarité de la valeur des attentes
 peut être écrit. Suit ensuite avec la linéarité de la valeur des attentes
peut être écrit. Suit ensuite avec la linéarité de la valeur des attentes 
Alternativement, vous pouvez également fournir la preuve suivante à l’aide du taux d’enseignement binomien: si vous différenciez l’équation

Les deux côtés après
, remis
 , remis
, remis - ,

aussi
- .

Avec
et
 et
et suit le résultat souhaité.
 suit le résultat souhaité.
suit le résultat souhaité. Variance [ Modifier | Modifier le texte source ]]
La distribution binomiale a la variance
avec
 avec
avec .
 .
. Preuve
C’est
un
-Révance aléatoire distribuée. La variance est déterminée directement à partir du taux de décalage
 -Révance aléatoire distribuée. La variance est déterminée directement à partir du taux de décalage
-Révance aléatoire distribuée. La variance est déterminée directement à partir du taux de décalage pour
 pour
pour 
Ou alternativement à partir de l’équation de Benaymé, appliquée à la variance des variables aléatoires indépendantes si l’on prend en compte les processus individuels identiques
la distribution de Bernoulli avec
se rencontrer aussi
 se rencontrer aussi
se rencontrer aussi 
La deuxième égalité s’applique parce que les expériences individuelles sont indépendantes, de sorte que les variables individuelles sont incorporées.
Coefficient de variation [ Modifier | Modifier le texte source ]]
Le coefficient de variation est obtenu à partir de la valeur d’attente et de la variance

Courbé [ Modifier | Modifier le texte source ]]
Le tordu se pose

Courbure [ Modifier | Modifier le texte source ]]
La courbure peut également être affichée fermée comme

Aussi l’excès

Modus [ Modifier | Modifier le texte source ]]
Le mode, c’est-à-dire la valeur avec la probabilité maximale, est pour
même
 même
même et pour
 et pour
et pour même
. Chutes
est un nombre naturel
 est un nombre naturel
est un nombre naturel Aussi un mode. Si la valeur des attentes est un nombre naturel, la valeur d’attente est égale au mode.
 Aussi un mode. Si la valeur des attentes est un nombre naturel, la valeur d’attente est égale au mode.
Aussi un mode. Si la valeur des attentes est un nombre naturel, la valeur d’attente est égale au mode. Preuve
Être sans restriction
. Nous regardons le quotient
 . Nous regardons le quotient
. Nous regardons le quotient - .

S’applique maintenant

et
 et
et , chutes
 , chutes
, chutes


Le quotient a-t-il la valeur 1, i. H.
 Le quotient a-t-il la valeur 1, i. H.
Le quotient a-t-il la valeur 1, i. H. .
 .
. Médian [ Modifier | Modifier le texte source ]]
Il n’est pas possible de spécifier une formule générale pour la médiane de la distribution binomiale. Par conséquent, différents cas doivent être pris en compte qui fournissent une médiane appropriée:
- Est Un nombre naturel, alors la valeur des attentes, la médiane et le mode sont d’accord et sont les mêmes . [6] [7]
- Une médiane Est dans l’intervalle . [8] Décrire ici La fonction d’arrondi et La fonction d’arrondi.
- Une médiane Je ne peux pas trop différer de la valeur des attentes: . [9]
- La médiane est claire et a raison avec rond d’accord si l’un ou l’autre ou ou (sauf quand et est juste). [8] [9]
- Est et Bizarre, tout est aussi à l’intervalle Une médiane de la distribution binomiale avec les paramètres et . Est et droit, aussi La médiane claire.













Cumulateur [ Modifier | Modifier le texte source ]]
Analogue à la distribution de Bernoulli, la fonction générateurs de cumulator est
- .

Aussi les premiers cumulateurs
Et l’équation de la récursivité s’applique
 Et l’équation de la récursivité s’applique
Et l’équation de la récursivité s’applique 
Fonction caractéristique [ Modifier | Modifier le texte source ]]
La fonction caractéristique a la forme

Fonction de génération de probabilité [ Modifier | Modifier le texte source ]]
Pour la fonction de génération de probabilité que vous obtenez

Fonction de génération de moment [ Modifier | Modifier le texte source ]]
La fonction générateurs de moment de la distribution binomiale est

Somme de tailles aléatoires distribuées binomiales [ Modifier | Modifier le texte source ]]
Pour la somme
Deux tailles aléatoires distribuées binomiales indépendantes
 Deux tailles aléatoires distribuées binomiales indépendantes
Deux tailles aléatoires distribuées binomiales indépendantes et
Avec les paramètres
 Avec les paramètres
Avec les paramètres ,
 ,
, et
,
 ,
, Si vous obtenez les probabilités individuelles en utilisant l’identité de Vanderondeschen
![{displaystyle {begin{aligned}operatorname {P} (Z=k)&=sum _{i=0}^{k}left[{binom {n_{1}}{i}}p^{i}(1-p)^{n_{1}-i}right]left[{binom {n_{2}}{k-i}}p^{k-i}(1-p)^{n_{2}-k+i}right]\&={binom {n_{1}+n_{2}}{k}}p^{k}(1-p)^{n_{1}+n_{2}-k}qquad (k=0,1,dotsc ,n_{1}+n_{2}),end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/94d620c42183da7a282177dd40b3b98088ed0b2a)
Encore une fois une taille aléatoire distribuée binomiale, mais avec les paramètres
et
 et
et . S’applique donc au pliage

La distribution binomiale est donc reproductive pour
ou forme un groupe pliant.
Si la somme
est connu, chacune des variables aléatoires suit
et
Dans cette condition d’une distribution hypergéométrique. Pour ce faire, la probabilité conditionnelle est calculée:

Cela représente une distribution hypergéométrique.
En général: si le
Variables aléatoires
sont stochastiques indépendantes et les distributions binomiales
assez, alors la somme est aussi
 assez, alors la somme est aussi
assez, alors la somme est aussi Binomial distribué, mais avec les paramètres
 Binomial distribué, mais avec les paramètres
Binomial distribué, mais avec les paramètres et
 et
et . Ajoute des variables aléatoires distribuées binomiales
avec
 avec
avec , alors vous obtenez une distribution binomiale généralisée.
 , alors vous obtenez une distribution binomiale généralisée.
, alors vous obtenez une distribution binomiale généralisée. Relation avec la distribution de Bernoulli [ Modifier | Modifier le texte source ]]
Un cas particulier de distribution binomiale pour
est la distribution de Bernoulli. La somme des tailles aléatoires indépendantes et identiques à bernoulli est donc suffisante pour la distribution binomiale.
 est la distribution de Bernoulli. La somme des tailles aléatoires indépendantes et identiques à bernoulli est donc suffisante pour la distribution binomiale.
est la distribution de Bernoulli. La somme des tailles aléatoires indépendantes et identiques à bernoulli est donc suffisante pour la distribution binomiale. Relation avec la distribution binomiale généralisée [ Modifier | Modifier le texte source ]]
La distribution binomiale est un cas particulier de distribution binomiale généralisée avec
pour tous
 pour tous
pour tous .
Il est plus précis pour la valeur des attentes fixes et l’ordre fixe de la distribution binomiale généralisée avec une entropie maximale. [dix]
 .
.Transition vers la distribution normale [ Modifier | Modifier le texte source ]]
Selon la phrase de Moivre-Laplace, la distribution binomiale converge dans l’affaire limite
Contre une distribution normale, d. Autrement dit, la distribution normale peut être utilisée comme une approximation utile de la distribution binomiale si la taille de l’échantillon est suffisamment grande et que la proportion de la recherche n’est pas trop petite. Avec le conseil d’administration de Galton, vous pouvez comprendre expérimentalement l’approche de la distribution normale.
 Contre une distribution normale, d. Autrement dit, la distribution normale peut être utilisée comme une approximation utile de la distribution binomiale si la taille de l’échantillon est suffisamment grande et que la proportion de la recherche n’est pas trop petite. Avec le conseil d’administration de Galton, vous pouvez comprendre expérimentalement l’approche de la distribution normale.
Contre une distribution normale, d. Autrement dit, la distribution normale peut être utilisée comme une approximation utile de la distribution binomiale si la taille de l’échantillon est suffisamment grande et que la proportion de la recherche n’est pas trop petite. Avec le conseil d’administration de Galton, vous pouvez comprendre expérimentalement l’approche de la distribution normale. Ça s’applique
et
 et
et En insérant dans la fonction de distribution
 En insérant dans la fonction de distribution
En insérant dans la fonction de distribution La distribution normale standard suit
 La distribution normale standard suit
La distribution normale standard suit 
Quant à voir, le résultat n’est rien de plus que la valeur fonctionnelle de la distribution normale pour
,
 ,
, ainsi que
 ainsi que
ainsi que (lequel est également vivant comme la zone du
 (lequel est également vivant comme la zone du
(lequel est également vivant comme la zone du -Te rayures de l’histogramme du Standardisé Distribution binomiale avec
Comme sa largeur et
 Comme sa largeur et
Comme sa largeur et comme sa hauteur). [11] L’approche de la distribution binomiale à la distribution normale est utilisée dans la proximité normale des singes afin de déterminer rapidement la probabilité de nombreux niveaux de distribution binomiale, surtout s’il n’y a plus de valeurs de tableau (plus) pour eux.
 comme sa hauteur). [11] L’approche de la distribution binomiale à la distribution normale est utilisée dans la proximité normale des singes afin de déterminer rapidement la probabilité de nombreux niveaux de distribution binomiale, surtout s’il n’y a plus de valeurs de tableau (plus) pour eux.
comme sa hauteur). [11] L’approche de la distribution binomiale à la distribution normale est utilisée dans la proximité normale des singes afin de déterminer rapidement la probabilité de nombreux niveaux de distribution binomiale, surtout s’il n’y a plus de valeurs de tableau (plus) pour eux. Transition vers la distribution de Poisson [ Modifier | Modifier le texte source ]]
Une distribution binomiale asymétrique, dont la valeur des attentes
pour
et
 et
et Contre une constante
 Contre une constante
Contre une constante Converged, vous pouvez aborder la distribution de Poisson. La valeur
 Converged, vous pouvez aborder la distribution de Poisson. La valeur
Converged, vous pouvez aborder la distribution de Poisson. La valeur est alors la valeur des attentes pour toutes les distributions binomiales considérées dans la formation de valeur limite ainsi que pour la distribution de Poisson résultante. Ce rapprochement est également appelé approximation de Poisson, la valeur frontalière de Poisonsonsch ou la loi des événements rares.

Une règle de base dit que cette approximation est utilisable si
et
 et
et .
 .
. La distribution de Poisson est donc la distribution aux frontières de la distribution binomiale pour les grands
et peu
, Il s’agit d’une convergence dans la distribution.
Relation avec la distribution géométrique [ Modifier | Modifier le texte source ]]
Le nombre d’échecs jusqu’à la première occurrence du succès est décrit par la distribution géométrique.
Relation avec la distribution binomiale négative [ Modifier | Modifier le texte source ]]
La distribution binomiale négative, en revanche, décrit la distribution de probabilité du nombre de tentatives nécessaires pour atteindre un nombre donné de succès dans un processus de Bernoulli.
Relation avec la distribution hypergéométrique [ Modifier | Modifier le texte source ]]
Dans le cas de la distribution binomiale, les échantillons sélectionnés sont retournés au volume de sélection, afin qu’ils puissent être sélectionnés à nouveau à une date ultérieure. En revanche, les échantillons ne sont pas retournés dans la population, la distribution hypergéométrique est utilisée. Les deux distributions vont dans une large mesure
la population et une petite étendue
Les échantillons ont fusionné. En règle générale, pour
Même si les échantillons ne sont pas suivis, la distribution binomiale peut être utilisée à la place de la distribution hypergéométrique mathématiquement plus exigeante, car les deux dans ce cas ne fournissent que des résultats légèrement différents.
 Même si les échantillons ne sont pas suivis, la distribution binomiale peut être utilisée à la place de la distribution hypergéométrique mathématiquement plus exigeante, car les deux dans ce cas ne fournissent que des résultats légèrement différents.
Même si les échantillons ne sont pas suivis, la distribution binomiale peut être utilisée à la place de la distribution hypergéométrique mathématiquement plus exigeante, car les deux dans ce cas ne fournissent que des résultats légèrement différents. Relation avec la distribution multinomiale [ Modifier | Modifier le texte source ]]
La distribution binomiale est un cas particulier de distribution multinomiale.
Relation avec la distribution Rademacher [ Modifier | Modifier le texte source ]]
Est
Binôme distribué au paramètre
et
, ainsi peut
Comme une somme à l’échelle de
Variables aléatoires distribuées par Rademacher
représenter:
 représenter:
représenter: 
Cela est particulièrement évident dans la marche aléatoire symétrique
utilisé.
 utilisé.
utilisé. Relation avec la distribution de Panjer [ Modifier | Modifier le texte source ]]
La distribution binomiale est un cas particulier de la distribution de Panjer, qui combine la distribution de la distribution binomiale, de la distribution binomiale négative et de la distribution de Poisson dans une classe de distribution.
Relation avec la distribution bêta [ Modifier | Modifier le texte source ]]
Pour de nombreuses applications, il est nécessaire de distribuer la fonction de distribution

à calculer spécifiquement (par exemple dans les tests statistiques ou pour les intervalles de confiance).
La relation suivante à la distribution bêta aide ici:

C’est pour des paramètres positifs entier
et
:
 :
: 
À l’équation

Pour prouver, on peut procéder comme suit:
- Le côté gauche et droit vote pour correspondre (les deux côtés sont 1).
- Les dérivations après vote pour le côté gauche et droit de l’équation, car ils sont tous les deux les mêmes . Pour la dérivation du côté droit, voir la règle Leibniz pour l’intégrale des paramètres.

Relation avec la distribution binomiale bêta [ Modifier | Modifier le texte source ]]
Une distribution binomiale, son paramètre
Est distribué par bêta, est appelé une distribution binomiale bêta. C’est une distribution mixte.
Relation avec la distribution de pólya [ Modifier | Modifier le texte source ]]
La distribution binomiale est un cas particulier de la distribution Pólya (choisissez
).
 ).
). Distribution binomiale symétrique ( p = 1/2) [ Modifier | Modifier le texte source ]]
-

p = 0,5 et n = 4, 16, 64
-

-

Mise à l’échelle avec écart-type
Ce cas se produit au
-Fachen Talent de monnaie avec une monnaie équitable (probabilité de têtes égale au nombre, c’est-à-dire seulement 1/2). La première figure montre la distribution binomiale pour
Et pour différentes valeurs de
En tant que fonction de
. Ces distributions binomiales sont symétriques du miroir autour de la valeur
:
 :
: 


Ceci est illustré dans la deuxième figure.
La largeur de la distribution devient proportionnelle à l’écart type
. La valeur de la fonction à
 . La valeur de la fonction à
. La valeur de la fonction à , c’est-à-dire le maximum de la courbe, tombe proportionnellement
.
 .
. En conséquence, on peut être des distributions binomiales avec différents
Échelle les uns sur les autres par l’abscisse
à travers
 à travers
à travers actions et l’ordonnée avec
multiplié (troisième figure ci-dessus).
Le graphique adjacent montre les distributions binomiales redimensionnées, maintenant pour d’autres valeurs de
Et dans une miséricorde qui facilite la facilité de réalisation de toutes les valeurs fonctionnelles avec l’augmentation
converge contre une courbe commune. En utilisant la formule Stirling sur les coefficients binomiaux, vous pouvez voir que cette courbe (tirée en noir sur l’image) est une courbe de cloche Gaußsche:
- .

C’est la densité de probabilité de la distribution normale standard
. Dans la limite centrale, cette constatation est si généralisée que les conséquences d’autres distributions de probabilité discrètes convergent contre la distribution normale.
 . Dans la limite centrale, cette constatation est si généralisée que les conséquences d’autres distributions de probabilité discrètes convergent contre la distribution normale.
. Dans la limite centrale, cette constatation est si généralisée que les conséquences d’autres distributions de probabilité discrètes convergent contre la distribution normale. Le deuxième graphique adjacent montre les mêmes données dans une application semi-logarithmique. Ceci est recommandé si vous souhaitez vérifier s’il existe des événements rares qui s’écartent de plusieurs écarts-types par rapport à la valeur des attentes, une distribution binomiale ou normale.
Tirer des balles [ Modifier | Modifier le texte source ]]
Il y a 80 balles dans un récipient, dont 16 jaunes. Une balle est retirée 5 fois puis couverte à nouveau. En raison du revêtement, la probabilité de tirer une boule jaune est également grande pour tous les retraits, à savoir 16/80 = 1/5. La valeur
indique que précisément
 indique que précisément
indique que précisément Les balles retirées sont jaunes. Par exemple, nous nous attendons
:
 :
: 
Dans environ 5% des cas, exactement 3 boules jaunes sont tirées.
| B (k | 0,2; 5) | |
| k | Probabilité en% |
| 0 | 32 768 |
| d’abord | 40.96 |
| 2 | 20.48 |
| 3 | 5.12 |
| 4 | 0,64 |
| 5 | 0,032 |
| ∑ | 100 |
| Valeur adulte | d’abord |
| Variance | 0.8 |
Nombre de personnes avec un anniversaire le week-end [ Modifier | Modifier le texte source ]]
La probabilité qu’une personne ait son anniversaire cette année est (par souci de simplicité) 2/7. 10 personnes restent dans une pièce. La valeur
donne (dans le modèle simplifié) la probabilité qui
 donne (dans le modèle simplifié) la probabilité qui
donne (dans le modèle simplifié) la probabilité qui Les personnes présentes cette année ont un anniversaire un week-end.
| B (k | 2/7; 10) | |
| k | Probabilité en% (arrondi) |
| 0 | 3.46 |
| d’abord | 13.83 |
| 2 | 24.89 |
| 3 | 26.55 |
| 4 | 18.59 |
| 5 | 8.92 |
| 6 | 2.97 |
| 7 | 0,6797 |
| 8 | 0.1020 |
| 9 | 0,009063 |
| dix | 0.0003625 |
| ∑ | 100 |
| Valeur adulte | 2.86 |
| Variance | 2.04 |
Ensemble dans l’année ensemble [ Modifier | Modifier le texte source ]]
253 personnes se sont réunies. La valeur
indique que exactement
 indique que exactement
indique que exactement La personne présente un jour choisi au hasard a son anniversaire (sans considérer l’année).
| B (k | 1/365; 253) | |
| k | Probabilité en% (arrondi) |
| 0 | 49,95 |
| d’abord | 34,72 |
| 2 | 12.02 |
| 3 | 2.76 |
| 4 | 0,47 |
La probabilité que “quelqu’un” de ces 253 personnes, c’est-à-dire H. Une ou plusieurs personnes qui ont un anniversaire ce jour-là est donc
.
 .
. Dans 252 personnes, la probabilité est
. Cela signifie que le seuil du nombre de personnes, à partir de laquelle la probabilité qu’au moins une de ces personnes ait un jour choisi au hasard de son anniversaire, soit supérieur à 50% est de 253 personnes (voir aussi le paradoxe de l’anniversaire).
 . Cela signifie que le seuil du nombre de personnes, à partir de laquelle la probabilité qu’au moins une de ces personnes ait un jour choisi au hasard de son anniversaire, soit supérieur à 50% est de 253 personnes (voir aussi le paradoxe de l’anniversaire).
. Cela signifie que le seuil du nombre de personnes, à partir de laquelle la probabilité qu’au moins une de ces personnes ait un jour choisi au hasard de son anniversaire, soit supérieur à 50% est de 253 personnes (voir aussi le paradoxe de l’anniversaire). Le calcul direct de la distribution binomiale peut être difficile en raison des grandes facultés. Une approximation de la distribution de Poisson est autorisée ici (
). Avec le paramètre
 ). Avec le paramètre
). Avec le paramètre Les valeurs suivantes surviennent: [douzième]
 Les valeurs suivantes surviennent: [douzième]
Les valeurs suivantes surviennent: [douzième] | P 253/365 (k) | |
| k | Probabilité en% (arrondi) |
| 0 | 50 |
| d’abord | 34.66 |
| 2 | 12.01 |
| 3 | 2.78 |
| 4 | 0,48 |
Intervalle de confiance pour une probabilité [ Modifier | Modifier le texte source ]]
Dans une enquête d’opinion
Personnes
Les gens à choisir la fête A. Déterminez un intervalle de confiance à 95% pour la proportion inconnue d’électeurs qui choisissent le parti A dans l’électorat global.
Une solution au problème sans L’enregistrement à la distribution normale peut être trouvé dans l’intervalle de confiance de l’article pour la probabilité de succès de la distribution binomiale.
Modèle d’utilisation [ Modifier | Modifier le texte source ]]
En utilisant la formule suivante, la probabilité peut être calculée que
depuis
Les gens une activité en moyenne
Minutes par heure Prises, exécutez en même temps.

Erreurs statistiques de la fréquence des classes dans les histogrammes [ Modifier | Modifier le texte source ]]
L’affichage de la mesure indépendante entraîne un histogramme conduit au regroupement des valeurs mesurées dans les classes.
La probabilité de
Entrées en classe
 Entrées en classe
Entrées en classe est donné par la distribution binomiale
 est donné par la distribution binomiale
est donné par la distribution binomiale - avec et .



Valeur d’attente et variance du
Sont alors
- et .


Cela réside l’erreur statistique du nombre d’entrées en classe
à
- .

Avec un grand nombre de classes,
petit et petit
 petit et petit
petit et petit .
 .
. Par exemple, la précision statistique des simulations de Monte Carlo peut être déterminée.
Les nombres aléatoires pour la distribution binomiale sont généralement générés en utilisant la méthode d’inversion.
Alternativement, vous pouvez également utiliser que la somme des variables aléatoires distribuées de Bernoulli est binomiale. Vous créez ceci
Bernoulli a distribué des nombres aléatoires et les ajoute; Le résultat est un nombre aléatoire distribué binomial.
Appeler la fonction de probabilité de la distribution binomiale dans les ordinateurs de poche et les logiciels mathématiques se produit généralement certains de certains , pdfbin ou Binomialpdf ( Fonction de densité de probabilité binomiale ). La fonction de distribution accumulée est avec cdfbin ou Binomialcdf ( Fonction de distribution cumulative binomiale ) abrégé. [13]
- ↑ Peter Kissel: MAC08 Stochastics (partie 2). Darmstadt Study Community 2014, p. 12.
- ↑ Bigalke, Köhler: Mathématiques 13.2 Cours de base et avancé. Cornelsen, Berlin 2000, p. 130.
- ↑ George Udny Yule: Une introduction à la théorie des statistiques. Griffin, Londres 1911, S. 287.
- ↑ Peter Kissel: MAC08 Stochastics. Partie 2e groupe d’étude Darmstadt 2014, p. 23.
- ↑ Bigalke, / Köhler: Mathématiques 13.2 Cours de base et avancé. Cornelsen, Berlin 2000, p. 144 ff.
- ↑ P. Neumann: Sur la médiane de la distribution binomiale et de Poisson . Dans: Magazine scientifique de l’Université technique de Dresde . 19e année, 1966, S. 29–33 .
- ↑ Seigneur, Nick. (Juillet 2010). “Moyenne binomiale Lorsque la moyenne est un entier”, The Mathematical Gazette 94, 331–332.
- ↑ un b R. Kaas, J.M. Buhrman: Moyenne, médiane et mode dans les distributions binomiales . Dans: Statistiques neerlandiques . 34e année, Non. d’abord , 1980, S. 13–18 , est ce que je: 10.1111 / j.1467-9574.1980.tb00681.x .
- ↑ un b K. Hamza: La plus petite limite supérieure uniforme sur la distance entre la moyenne et la médiane des distributions binomiales et de Poisson . Dans: Statistiques et lettres de probabilité . 23e année, 1995, S. 21-25 , est ce que je: 10.1016 / 0167-7152 (94) 00090-in .
- ↑ Peter Harremoës: Distributions binomiales et de Poisson comme distributions d’entropie maximales . Dans: Transactions IEEE sur la théorie de l’information . 47e année. IEEE Information Theory Society, 2001, S. 2039-2041 , est ce que je: 101109/18 930936 .
- ↑ M. Brokate, N. Henze, F. Hettlich, A. Meister, G. Schranz-Kirchener, Th. Sonar: Connaissance de base des mathématiques: analyse plus élevée, numérique et stochastes. Springer-Verlag, 2015, p. 890.
- ↑ Dans le cas spécifique, vous devez pour la distribution binomiale calculer et pour la distribution de Poisson . Les deux sont faciles avec la calculatrice. Dans le cas d’une facture avec du papier et du crayon, la série exponentielle 8 ou 9 est requise pour la valeur de la distribution de Poisson, tandis que pour la distribution binomiale au moyen de plusieurs carrés, vous arrivez à 256. puissance puis partagez à travers la troisième puissance.
- ↑ Aide en ligne SCILAB – Statistiques. Consulté le 13 janvier 2022 .


Recent Comments