Bayesche Netz – Wikipedia
UN Réseau de Bayesch ou Réseau de Bayes (Nommé d’après Thomas Bayes) est un graphique azyclique dirigé (DAG), dans lequel les nœuds décrivent des variables aléatoires et les bords dus aux variables. Chaque nœud du réseau se voit attribuer une distribution de probabilité conditionnelle de la variable aléatoire représentée par elle, compte tenu des variables aléatoires sur les nœuds parents. Ils sont décrits par des tableaux de probabilité. Cette distribution peut être arbitraire, mais elle est souvent utilisée pour travailler avec des distributions discrètes ou normales. Les parents d’un nœud V sont les nœuds qui mènent à V.
Un réseau bavarois sert à représenter la distribution de probabilité commune de toutes les variables impliquées dans l’utilisation de l’indépendance conditionnelle connue aussi compacte que possible. La dépendance conditionnelle (UN) sur le sous-ensemble des variables est combinée avec les connaissances A-priori.
Sont X d’abord , …, X n Certaines des variables aléatoires (qui sont terminées en ajoutant des variables parentales), leur distribution commune est calculée comme

Y a-t-il
Une orthographe symbolique pour la distribution de probabilité commune des variables aléatoires
 Une orthographe symbolique pour la distribution de probabilité commune des variables aléatoires
Une orthographe symbolique pour la distribution de probabilité commune des variables aléatoires .
Si un nœud n’a pas de parents, la distribution associée de la probabilité est une distribution inconditionnelle.
 .
.Comme dans l’exemple ci-dessous, on vous intéresse souvent à une probabilité marginale qui peut être effectuée par marginalisation sur toutes les réalisations possibles
Dans la salle d’État
 Dans la salle d’État
Dans la salle d’État La variable aléatoire
 La variable aléatoire
La variable aléatoire reçoit:
 reçoit:
reçoit: 
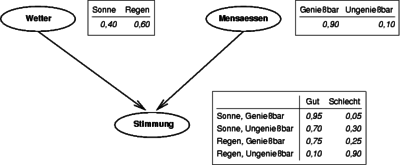



Dans l’exemple, les trois variables aléatoires se forment
= Temps,
 = Temps,
= Temps, = Cafétéria et
 = Cafétéria et
= Cafétéria et = Humeur les nœuds d’un réseau bavarois. En plus des nœuds pour les variables aléatoires
 = Humeur les nœuds d’un réseau bavarois. En plus des nœuds pour les variables aléatoires
= Humeur les nœuds d’un réseau bavarois. En plus des nœuds pour les variables aléatoires et
reçoivent leurs distributions de probabilité inconditionnelles. En plus du nœud pour la variable aléatoire
Sont quatre distributions de probabilité conditionnelles pour une variable aléatoire
, compte tenu des quatre combinaisons possibles de
et
, indiqué.
Les deux variables aléatoires
et
Sont les parents de
Et n’ont pas de parents. Les deux flèches (bords) sont interprétées de manière causale.
La distribution commune de la probabilité est calculée en raison de l’indépendance stochastique de M et W comme suit:

Par conséquent, avec l’aide de la loi de la probabilité totale, suit la distribution marginale

Avec les distributions de probabilité spécifiées, la distribution de bord de
déterminer. Par exemple, s’applique

Toutes les probabilités requises peuvent être trouvées dans les trois tables.
Peut aussi être terminé

pour
,
 ,
, et
 et
et La distribution commune de la probabilité de
 La distribution commune de la probabilité de
La distribution commune de la probabilité de ,
et
déterminer. Le premier signe d’égalité résulte de la définition d’une probabilité conditionnelle et le deuxième signe d’égalité utilise l’indépendance stochastique des variables aléatoires
et
. Z. B. doré
- .

De même, sept autres probabilités pour toutes les autres combinaisons de valeurs de variables aléatoires peuvent être
,
et
calculer.
La distribution commune de la probabilité de
et
vous obtenez de la distribution de probabilité commune de
,
et
quand

pour
et
.
S’il est connu que l’humeur est bonne, la probabilité de temps ensoleillé peut être attiré:

où toutes les probabilités requises de la distribution de probabilité commune de
et
résultat.
Provient de certaines des variables, à propos ET d’abord , …, ET m , la valeur connue, d. H. Si des preuves sont disponibles, à l’aide de divers algorithmes, la distribution de probabilité conditionnelle de X d’abord , …, X n Avec donné ET d’abord , …, ET m sont calculés et donc opérés.
Le problème d’inférence, à la fois exactement et approximatif, dans les réseaux de Bayes, est NP-Shw. Des procédures approximatives sont disponibles dans des réseaux plus grands. Les procédures exactes sont un peu plus précises qu’approximativement, mais cela ne joue souvent qu’un rôle insignifiant dans la pratique, car les réseaux bayésiens sont utilisés pour prendre des décisions où les probabilités exactes ne sont pas nécessaires.
Il convient de noter que, dans le cas des implémentations logicielles, précisément seulement deux fois des numéros de virgules coulissants précis sont utilisés. Cela limite la précision de ces calculs.
Inférence exacte [ Modifier | Modifier le texte source ]]
Pour l’inférence exacte à Bayesche Netzen, entre autres. ce qui suit
Algorithmes:
Approximative Inferenz [ Modifier | Modifier le texte source ]]
Types d’inférence [ Modifier | Modifier le texte source ]]
- Diagnostic: des effets aux causes
- Causal: des causes aux effets
- Intercausal: entre les causes d’un effet commun
- Mixte: combinaison de la précédente
Si un réseau bavarois doit être généré automatiquement à partir des données disponibles, qui décrit les données ainsi que possible, deux problèmes possibles surviennent: soit la structure du graphique du réseau est déjà donnée et vous n’avez plus à prendre soin de la détermination de l’indépendance conditionnelle, mais uniquement pour calculer la distribution conditionnelle sur le nœud du réseau, ou vous devez également apprendre une structure d’un réseau adapté en plus des paramètres.
Paramètre d’apprentissage [ Modifier | Modifier le texte source ]]
Si vous n’assumez pas un modèle de probabilité complet (bayésien), vous choisissez généralement
comme méthode d’estimation. En cas de modèle de probabilité complet (Bayesche), l’estimation du point est
à. Les maxima locaux de la probabilité ou du Postériorifusten en cas de données complètes et de variables entièrement observées peuvent généralement être utilisées avec des algorithmes d’optimisation communs tels que
être trouvé. Pour que le cas des observations manquantes soit considérée comme la règle), la puissante et la répartition sont généralement
utilisé.
Apprentissage structurel [ Modifier | Modifier le texte source ]]
L’apprentissage structurel peut avec l’algorithme K2 (approximativement, en utilisant une fonction cible appropriée) ou l’algorithme PC.
Pour déterminer l’indépendance conditionnelle de deux quantités de variables, un tiers de ces quantités est suffisant pour examiner la structure du graphique du réseau. On peut montrer que le concept (théorique graphique) de la séparation D coïncide avec le concept d’indépendance conditionnelle.
Les moustiquaires Bayesch sont utilisés comme une forme de systèmes d’experts probabilistes, par lesquels les domaines d’application se trouvent en bioinformatique, analyse des échantillons, médecine et sciences de l’ingénierie. Dans la tradition de l’intelligence artificielle, l’accent est mis sur Bayescher Netze sur l’utilisation de leurs structures graphiques pour permettre des conclusions abducteurs et déductives qui seraient inspectives dans une probabilité non liée. Ceci est réalisé par les différents algorithmes d’inférence.
L’idée de base des réseaux de Bayescher, à savoir la factorisation graphique d’un modèle de probabilité, est également utilisée dans d’autres traditions, telles que dans les statistiques bayésiennes et dans la tradition des modèles graphiques So appelés à des fins de modélisation des données. Les domaines d’application sont principalement l’épidémiologie, la médecine et les sciences sociales.
- Enrique Castillo, Jose Manuel Gutierrez, Ali S. Hadi: Systèmes experts et modèles de réseau probabiliste . Springs-Publinging, New York 1997, ISBN 0-387-94858-9.
- Finn V. Jensen: Réseaux bayésiens et graphiques de décision . Spring Pleans, New York, New Hork 2001, ISBN 0-387-9525259-4.
- Richard E. Napolitan: Apprendre les réseaux bayésiens . Prentice Hall, 2003, ISBN 0-13-012534-2.
- Judea Pearl: Raisonnement probabiliste dans les systèmes intelligents: réseaux d’inférence plausible . Morgan Kauffmann Publishers, San Francisco 1988, ISBN 0-934613-73-7
- Judea Pearl: Causalité . Cambridge University Press, Cambridge 2000, ISBN 0-521-77362-8.
- Stuart Russell, Peter Norvig: Intelligence artificielle – une approche moderne . Pearson Education Allemagne, Allemagne 2004, ISBN 3-8273-7089-2.
Recent Comments