Protocole de contrôle de la transmission – Wikipedia
Le Protocole de contrôle de la transmission ( TCP , Engl. Pour “Protocole de contrôle de transmission”) est un protocole de réseau qui définit la façon dont les données doivent être échangées entre les composants du réseau. Presque tous les systèmes d’exploitation actuels des ordinateurs modernes maîtrisent TCP et les utilisent pour l’échange de données avec d’autres ordinateurs. Le protocole est un diagramme fiable, orienté vers la connexion, [d’abord] Protocole de transport dans les réseaux informatiques. Il fait partie de la famille du protocole Internet, la base d’Internet.
TCP a été développé par Robert E. Kahn et Vinton G. Cerf. Son travail de recherche qui a commencé en 1973 a duré plusieurs années. La première normalisation du TCP n’a donc été effectuée qu’en 1981 RFC 793 . Après cela, il y avait de nombreuses extensions qui sont encore spécifiées dans les nouveaux RFC, un certain nombre de documents techniques et organisationnels sur Internet. RFC 9293 Bundles la version originale et toutes ses extensions en un seul document.
Contrairement à la charnière UDP ( Anglais Protocole de datagramme utilisateur ) établit TCP entre deux points d’extrémité d’une connexion réseau (sockets). Les données peuvent être transmises sur cette connexion dans les deux sens. Dans la plupart des cas, TCP s’appuie sur l’IP (Protocole Internet), c’est pourquoi il y a souvent (et souvent pas entièrement correct) du “protocole TCP / IP”. Dans les piles de protocole telles que le modèle OSI, TCP et IP ne sont pas situés sur la même couche. TCP est une implémentation de la couche de transport.
En raison de ses nombreuses propriétés positives (les pertes de données sont reconnues et automatiquement corrigées, la transmission des données est possible dans les deux sens, la surcharge du réseau est évité, etc.) Le TCP est un protocole très répandu pour la transmission des données. Par exemple, TCP a été utilisé depuis longtemps comme protocole de transport presque exclusif pour le www, le courrier électronique et de nombreux autres services de réseau populaires. Dans le www, TCP obtient la concurrence de la Protocole de transport cryptée, qui a été standardisée en 2021.
En principe, TCP est une connexion de bout en bout à Vollduplex, qui permet la transmission des informations aux deux directions, analogues à un appel téléphonique. Cette connexion peut également être considérée comme deux composés semi -duplex dans lesquels les informations peuvent s’écouler dans les deux directions (mais pas en même temps). Les données dans la direction opposée peuvent contenir des informations de contrôle supplémentaires. La gestion de cette connexion et la transmission de données sont repris par le logiciel TCP. Le logiciel TCP est généralement situé dans la pile de protocole réseau du système d’exploitation. Les programmes d’application utilisent une interface, principalement des sockets qui (différents du système d’exploitation) sont utilisés, par exemple, dans Microsoft Windows dans les bibliothèques de programmes (“winsock.dll” ou “wsock32.dll”) à faire. Linux et de nombreux autres systèmes d’exploitation Unixoid contiennent une couche de base dans le noyau du système d’exploitation. Les appels système sont accessibles sur la couche de socket. Les applications que TCP utilisent souvent sont des navigateurs Web et des serveurs Web, par exemple.
Chaque connexion TCP est clairement identifiée par deux points d’extrémité. Un point final est un couple ordonné composé d’une adresse IP et d’un port. Un tel couple forme une interface logicielle bidirectionnelle et est également appelé socket. Une connexion TCP est ainsi identifiée par quatre valeurs (un quadruple):
(Ordinateur local, port local, ordinateur distant, port distant)
Cela dépend de l’ensemble du quadruple. Par exemple, deux processus différents sur le même ordinateur peuvent utiliser le même port local et même communiquer avec le même ordinateur du côté opposé, à condition que les processus impliqués utilisent différents ports à l’autre. Dans un tel cas, ce serait deux connexions différentes, dont le quadruble ne diffère que par l’une des quatre valeurs: le port du côté opposé.
Connexion 1: (ordinateur local, port x, ordinateur distant, port y) Connexion 2: (ordinateur local, port x, ordinateur distant, port z)
Par exemple, un processus de serveur crée une base ( prise , lier ) au port 80, marquez-le pour les connexions entrantes ( écouter ) et appelle la prochaine connexion à venir à partir du système d’exploitation ( accepter ). Cette exigence bloque initialement le processus du serveur car il n’y a toujours pas de connexion. Si la première demande de connexion est ensuite reçue par un client, elle est acceptée par le système d’exploitation afin que la connexion soit établie. À partir de maintenant, cette connexion est identifiée par le quadruple décrit ci-dessus.
Enfin, le processus du serveur est réveillé et une poignée pour cette connexion est présentée. Habituellement, le processus du serveur démarre alors un processus enfant auquel il délégue le traitement de la connexion. Il établit ensuite son travail avec un autre Accepter -requette pour le système d’exploitation.
Cela permet à un serveur Web d’accepter plusieurs connexions à partir de différents ordinateurs. Plusieurs écouter Il n’est pas possible sur le même port. Habituellement, le programme côté client ne détermine pas le port lui-même, mais peut le faire attribuer par le système d’exploitation.
Les ports sont des numéros 16 bits (numéros de port) et varient de 0 à 65535. Les ports de 0 à 1023 sont réservés [2] et sont décernés par l’IANA, par ex. B. Le port 80 est réservé au HTTP utilisé dans le www. L’utilisation des ports prédéfinis n’est pas de liaison. Par exemple, chaque administrateur peut exécuter un serveur FTP (généralement le port 21) sur n’importe quel autre port.

Un serveur qui offre son service crée un point final (socket) avec le numéro de port et son adresse IP. Ce sera passif ouvert [3] ou aussi comme écouter [4] désigné.
Si un client veut établir une connexion, cela crée sa propre prise à partir de son adresse informatique et du sien, toujours le numéro de port libre. Une connexion peut ensuite être établie à l’aide d’un port et à l’adresse du serveur connu. Une connexion TCP est clairement identifiée par les 4 valeurs suivantes:
- Quell-IP-Adresse
- Casse-caisse
- Adresse Target-IP
- Port cible
Pendant la phase de transfert de données ( Open actif ) sont les rôles du client et du serveur (du point de vue du TCP) complètement symétriques. En particulier, chacun des deux ordinateurs participants peut initier une réduction de connexion.
Connexions demi-clos [ Modifier | Modifier le texte source ]]
La connexion peut être réduite en deux types: des deux côtés ou progressive. Dans cette dernière variante, on parle d’une connexion à demi-clos (à ne pas confondre avec les connexions de demi-ouvre-open, voir ci-dessous). Il permet au côté opposé de transmettre des données après la séparation à un seul facteur.
Les connexions à demi-clos sont un héritage du système d’exploitation UNIX, dans la zone dont TCP a été créé. Selon le principe Tout est un fichier (dt. „ Tout est un fichier «) UNIX prend en charge une interaction complètement analogique entre deux processus dans les connexions TCP: pour un programme, il devrait tout simplement être non pertinent, qu’il se lise à partir d’une connexion TCP ou d’un fichier. Un programme UNIX se lit généralement jusqu’à la fin de l’entrée par défaut, puis écrit le résultat du traitement dans l’édition standard. Les flux de données standard sont connectés aux fichiers avant d’exécuter le programme.
Les canaux de va-et-vient d’une connexion TCP sont connectés à la valeur par défaut et à la sortie et sont donc logiquement représentés comme un fichier. Une connexion fermée est traduite par le processus de lecture en tant que fin de fichier atteint. Le schéma de traitement UNIX typique mentionné nécessite que la connexion soit toujours disponible pour l’écriture après la lecture de la fin du fichier, ce qui entraîne la nécessité de connexions demi-clôturées. [5]
Connexions à moitié ouvertes [ Modifier | Modifier le texte source ]]
Une connexion est à moitié ouverte lorsqu’un côté s’écrase sans que le côté restant ne ressente cela. Cela a l’effet indésirable que les ressources du système d’exploitation ne sont pas publiées. Des connexions à moitié ouvertes peuvent survenir car des connexions TCP existent du côté du protocole jusqu’à ce qu’elles soient décomposées. Les précautions correspondantes sont souvent prises par le côté de l’application.
Connexion [ Modifier | Modifier le texte source ]]
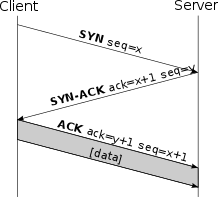
Le client qui souhaite établir une connexion envoie le serveur Son -Package (de Anglais synchroniser ) avec un numéro de séquence X . Les numéros de séquence sont importants pour assurer une transmission complète dans l’ordre correct et sans doublons. C’est donc un package dont Syn-bit est défini dans la tête du package (voir l’en-tête TCP). Le numéro de séquence de démarrage (également appelé numéro de séquence (ISN)) est n’importe quel nombre, dont la génération dépend de l’implémentation TCP respective. Cependant, il devrait être aussi aléatoire que possible d’éviter les risques de sécurité. [6]
Le serveur (voir Sketch) reçoit le package. Si le port est fermé, il répond avec un TCP RST pour signaler qu’aucune connexion ne peut être établie. Si le port est ouvert, il confirme la préservation du premier package SYN et accepte la connexion en renvoyant un package SYN / ACK (ACK depuis Engl. reconnaissance ,Confirmation’). L’indicateur ACK réglé dans l’en-tête TCP marque ces packages que le numéro de séquence x + 1 du synthèse dans l’en-tête. De plus, il envoie son numéro de séquence de démarrage en retour et , qui est également arbitraire et indépendant du numéro de séquence de démarrage du client.
Le client confirme récemment la préservation du package SYN / ACK en envoyant son propre package ACK avec le numéro de séquence x + 1 . Ce processus est également appelé “Forward RemercedgeMe”. Pour des raisons de sécurité, le client envoie la valeur et + 1 (Le numéro de séquence du serveur + 1) dans le segment ACK. La connexion est établie. Dans l’exemple suivant, le processus est montré abstrait:
| d’abord. | SynSent | → | → | Synchronié | |
| 2 | Syn / ACK | ← | ← | SYN / ACK-SENT | |
| 3 et 3 | Ack | → | → | ÉTABLI |
Une fois configuré, la connexion pour les deux partenaires de communication est égale, vous ne pouvez pas voir une connexion existante au niveau TCP qui est le serveur et qui est le client. Par conséquent, une distinction entre ces deux rôles n’est plus importante dans la nouvelle considération.
Connexion [ Modifier | Modifier le texte source ]]
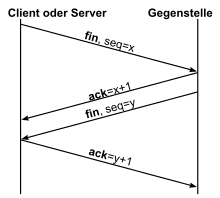
La connexion réglementée est similaire. Au lieu des synBits, le bit fin vient (d’Engl. finir «Ende», «conclusion») à utiliser, ce qui montre qu’aucune donnée ne proviendra plus de l’émetteur. La réception du colis est à nouveau confirmée par l’ACK. Le destinataire du package FIN lui envoie récemment un package FIN, qui lui est également confirmé.
De plus, une procédure raccourcie est possible, dans laquelle Fin et ACK sont hébergés dans le même paquet, tout comme lors de la création d’une connexion. Le durée de vie maximale du segment (MSL) est le temps maximum qu’un segment peut passer dans le réseau avant qu’il ne soit rejeté. Après avoir envoyé le dernier champ, le client passe à un état d’attente de deux MSL ( État d’attente ), dans lequel tous les segments tardifs sont jetés. Cela garantit qu’aucun segment tardif ne peut être mal interprété dans le cadre d’une nouvelle connexion qui utilise au hasard le même port. De plus, une terminaison de connexion correcte est assurée. Aller ak et + 1 Lost, la minuterie s’enfuit et le segment Last_ack est à nouveau transféré.
Bouffeur [ Modifier | Modifier le texte source ]]
Deux tampons sont utilisés lors de l’envoi de données via le TCP. L’application transmet les données à transmettre au TCP du côté émetteur et ce tampon les données afin d’envoyer plusieurs petites transmissions plus efficacement sous la forme d’un seul grand. Une fois les données ensuite transmises au destinataire, elles se retrouvent dans le tampon de la peau du receveur. Cela poursuit des objectifs similaires. Si plusieurs packages individuels ont été reçus par le TCP, il est préférable de les transmettre à l’application.
Manuel à trois voies [ Modifier | Modifier le texte source ]]
À la fois dans la structure de connexion et la réduction de la connexion, les réponses au premier package SYN ou FIN sont généralement résumées en un seul package (syn / ack ou fin / ack) – théoriquement, l’envoi de deux packages séparés serait également imaginable. Étant donné que seuls trois paquets doivent être envoyés dans ce cas, on parle souvent du soi-disant bilan à trois.
Cependant, le résumé du package FIN et du package ACK est problématique, car l’envoi d’un package FIN n’a le sens “aucune autre données ne suit”. Cependant, l’émetteur du package FIN peut continuer à recevoir des données; On parle d’une connexion à moitié clos (la direction de la réception est toujours ouverte pendant la fermeture de la direction de transmission). Ce serait z. B. concevable, le début d’une demande HTTP ( Http-request ) Soumettez directement dans le package SYN, des données supplémentaires dès que la connexion a été établie et dans le dernier package de demande HTTP pour fermer la (direction de transmission de la) connexion avec FIN. En pratique, cependant, cette procédure n’est pas appliquée. Si le navigateur fermait la connexion immédiatement de cette manière, le serveur peut également fermer la connexion au lieu de la demande de réponse complètement.
Général [ Modifier | Modifier le texte source ]]
Le segment TCP se compose toujours de deux parties: l’en-tête et la charge utile ( Anglais charge utile ). La charge utile contient les données à transmettre, qui à leur tour peuvent correspondre à des informations de protocole sur la couche d’application, telles que HTTP ou FTP. L’en-tête contient des données requises pour la communication et les informations de format de fichier. La structure schématique de l’en-tête TCP est visible sur la figure 5. Étant donné que le champ d’option n’est généralement pas utilisé, un en-tête typique a une taille de 20 octets. Les valeurs sont données dans l’ordre des octets Big-endian.
Explication [ Modifier | Modifier le texte source ]]

- Port source (Quellport) (2 octets)
- Donner la Numéro de port du côté de l’émetteur.
- Le port de destination (Zielport) (2 octets)
- Donner la Numéro de port du côté récepteur.
- Numéro de séquence (4 octets)
- Numéro de séquence des premières données oket ( Octet ) ce package TCP ou le Numéro de séquence d’initialisation Si le Syn-Flag est défini. Après la transmission des données, il sert à trier les segments TCP, car ils peuvent arriver au destinataire dans un ordre différent.
- Numéro de reconnaissance (Numéro de qualité) (4 octets)
- Elle donne le Numéro de séquence Sur ce, l’expéditeur de ce segment TCP attend ensuite. Il n’est valable que si l’indicateur ACK est défini.
- Décalage des données (4 bits)
- En-têtes Long des TCP dans des blocs 32 bits sans données utilisateur ( Charge utile ). Cela montre l’adresse de départ des données utilisateur.
- Réservé (4 bits)
- Le Réservé -Feld est réservé aux utilisations futures. Tous les bits doivent être nuls.
- Flags de contrôle (8 bits)
- Sont des variables à deux valeurs avec les conditions possibles ensemble et insatisfait Cela est nécessaire pour identifier certaines conditions pour la communication et le traitement ultérieur des données. Les drapeaux de l’en-tête TCP et les actions à effectuer sont décrits ci-dessous.
- CWR et ECE
- sont deux drapeaux requis pour la notification de conesion explicite (ECN). Avec un ensemble ECE-BIT (ECN-Echo), le destinataire informe l’émetteur que le réseau est surchargé et que le taux d’émetteur doit être réduit. Si le diffuseur l’a fait, il raconte au destinataire en définissant le bit CWR ( Fenêtre de congestion réduite ) avec.
- Urger
- Est le drapeau urgent (Urgent = urgent) Ensemble, les données sont immédiatement traitées par l’application en fonction de l’en-tête. L’application interrompt le traitement des données du segment TCP actuel et lit tous les octets après l’en-tête de l’octet sur lequel le Pointeur urgent -Pede montre. Cette procédure est loin d’être un logiciel Terrup. Cet drapeau peut être utilisé, par exemple, pour annuler une application sur le destinataire. La procédure est utilisée très rarement, les exemples sont le traitement préféré de Ctrl-C (démolition) en cas de connexion terminale via Rlogin ou Telnet.
- En règle générale, ce drapeau n’est pas évalué.
- Ack
- Le Reconnaissance -Flag a en relation avec le Reconnaissance Numérotez la tâche de confirmer la réception des segments TCP lors du transfert de données. Le Reconnaissance Le numéro n’est valide que si l’indicateur est défini.
- Psh
- RFC 1122 et RFC 793 Spécifiez que Pousser -FLAG de telle manière que lorsque le drapeau est défini, le tampon sortant et le tampon entrant est ignoré. Étant donné que vous n’envoyez pas de flux de données chez TCP, mais que vous avez un flux de données, le PSH-FLAG aide à traiter l’électricité plus efficacement, car l’application de réception peut être réveillée plus spécifiquement et n’a pas encore à découvrir avec chaque segment de données qui n’a pas encore été reçu.
- Ceci est utile si, par exemple, vous souhaitez envoyer une commande au destinataire lors d’une session Cloak. Si cette commande n’était pas stockée temporairement dans le tampon, elle serait (fortement) traitée.
- Selon l’implémentation TCP dans le comportement, l’indicateur PSH peut s’écarter de la déclaration ci-dessus.
- Premier
- Le Réinitialiser -FLAG est utilisé lorsqu’une connexion doit être annulée. Cela se produit, par exemple, en cas de problèmes techniques ou pour le licenciement des composés indésirables (tels que les ports non ouverts, contrairement à l’UDP, aucun package ICMP avec “port inaccessible” n’est envoyé ici).
- Son
- Les packages avec Syn-Flag set initier une connexion. Le serveur répond généralement avec SYN + ACK lorsqu’il est prêt à accepter la connexion, sinon avec RST. Sert la synchronisation de Numéros de séquence Dans la structure de connexion (d’où la désignation SY).
- FIN
- Ce dernier drapeau ( finir ) sert à libérer la connexion et indiquer qu’aucune donnée ne vient plus de l’émetteur. L’interruption et les syn-flag ont des numéros de séquence afin qu’ils soient traités dans l’ordre correct.
- (Recevoir) fenêtre (2 octets)
- Est le nombre d’osstrates de données (après multiplication avec le facteur d’échelle de la fenêtre ( Octets ), à commencer par ça Remerciementsfeld Indexé Data-Ortet que l’émetteur de ce package TCP est disposé à recevoir.
- Vérification (2 octets)
- Le Sommet sert à détecter les erreurs de transmission et est calculée via l’en-tête TCP, les données et un en-tête pseudo. Cet en-tête se compose de l’IP cible, de l’IP source, de la détection du protocole TCP (0x0006) et de la longueur de l’en-tête TCP, y compris les données utilisateur (en octets).
- Pointeur urgent (2 octets)
- Avec le numéro de séquence, cette valeur donne la position des premiers octets après les données d’origine dans le flux de données. Les données d’origine commencent immédiatement après l’en-tête. La valeur n’est valide que si l’indicateur URG est défini.
- Options (0–40 octet)
- Le champ d’option est différent en taille et contient des informations supplémentaires. Les options doivent être un multiple de 32 bits de long. Si vous ne l’êtes pas, il doit être rempli de bits zéro ( Rembourrage ). Ce champ permet de négocier des données de connexion qui ne sont pas incluses dans l’en-tête TCP, telles que la taille maximale du champ de données utilisateur.

Taille du segment TCP / IP [ Modifier | Modifier le texte source ]]
Un segment TCP a généralement une taille maximale de 1500 octets. Cependant, un segment TCP doit s’intégrer dans la couche de transmission sous-jacente, le protocole Internet (IP); Voir également l’unité de transmission maximale (MTU).
Les packages IP sont théoriquement spécifiés jusqu’à 65 535 octets (64 kib), mais sont principalement transmis via Ethernet, et avec Ethernet la taille des données utilisateur (couche 3) (si l’on provient de Cadres jumbo Abandonné) à 64 (incluant éventuellement un rembourrage) jusqu’à 1500 octets. Le protocole TCP et IP définit un en-tête de la taille de 20 octets. Dans un package TCP / IP, 1460 octets (= 1500 octets Ethernet- [Données utilisateur] -20 octets Données d’en-tête TCP-20 Données d’en-tête IP) Restez dans un package TCP / IP. Étant donné que la plupart des connexions Internet utilisent DSL, le protocole point à point (PPP) entre l’IP et Ethernet y est également utilisé, qui utilise 8 autres octets pour le cadre PPP. Les données de l’utilisateur sont donc réduites à un total de 1500 – 20 – 8 = 1452 octets MSS (taille maximale du segment). Cela correspond à un taux de données d’utilité maximum de 96,8%.
Division des données d’application aux segments TCP / IP [ Modifier | Modifier le texte source ]]
Le destinataire et l’émetteur s’accordent sur la taille du MSS avant l’échange de données via le champ d’option. L’application qui souhaite envoyer des données, comme un serveur Web, prend, par exemple, un bloc de données de 7 kilobytes dans le tampon.
Afin d’envoyer 7 kilobytes de données avec un champ de données d’utilisation de 1460 octets, le logiciel TCP divise les données sur plusieurs packages, ajoute un en-tête TCP et envoie les segments TCP. Ce processus est appelé segmentation. Le bloc de données dans le tampon est divisé en cinq segments (voir Fig. 6). Chaque segment reçoit un en-tête TCP du logiciel TCP. Les segments TCP sont envoyés l’un après l’autre. Ceux-ci n’arrivent pas nécessairement au destinataire dans le même ordre dans lequel ils ont été envoyés, car chaque segment TCP peut emprunter un chemin différent sur Internet. Chaque segment est numéroté afin que le logiciel TCP puisse trier à nouveau les segments chez le destinataire. Le numéro de séquence est utilisé lors de l’attribution des segments du destinataire.
Le logiciel TCP du destinataire confirme les segments TCP qui sont parfaitement arrivés (c’est-à-dire avec la joue correcte). Sinon, les packages seront demandés.
Exemple de transfert de données TCP / IP [ Modifier | Modifier le texte source ]]
L’émetteur envoie son premier segment TCP avec un numéro de séquence Seq = 1 (varié) et une longueur de données utilisateur de 1460 octets au destinataire. Le destinataire le confirme avec un en-tête TCP sans données avec ACK = 1461 et appelle ainsi le deuxième segment TCP du numéro 1461 octet. Cela l’envoie ensuite au destinataire avec un segment TCP et SEQ = 1461. Cela le confirme à nouveau avec un champ = 2921 et ainsi de suite. Le destinataire n’a pas besoin de confirmer chaque segment TCP s’il est cohérent. S’il reçoit les segments TCP 1 à 5, il n’a qu’à confirmer le dernier segment TCP. Par exemple, le segment TCP 3 est manquant car il a été perdu, il ne peut que confirmer les 1 et 2, 4 et 5, cependant, pas encore. Étant donné que le diffuseur ne reçoit aucune confirmation pour le 3, sa minuterie fonctionne et il envoie le 3. Si le 3 arrive chez le destinataire, il confirme les cinq segments TCP si les deux côtés prennent en charge le sac d’option TCP (ACK sélectif). Le diffuseur lance un temporisateur de retransmission pour chaque segment TCP qu’il envoie lors du voyage.
Minuterie de retransmission [ Modifier | Modifier le texte source ]]
Pour déterminer quand un package a été perdu dans le réseau, l’émetteur utilise un délai d’attente auquel le côté opposé doit être arrivé. Un délai trop bas fait répéter correctement les parcelles qui ont été correctement disposées; Un délai trop élevé signifie que le package à répéter est envoyé inutilement en retard si les pertes sont répétées.
En raison des différents termes des packages IP sous-jacents, seule une dynamique à la connexion des minuteries adaptées est logique. Les détails sont dans RFC 6298 [7] déterminé comme suit:
- Le délai d’attente (RTO = délai d’expiration de retransmission) est calculé à partir de deux variables d’état réalisées par l’émetteur:
- Initialement, on estime que RTO = 1S (afin de créer une compatibilité avec l’ancienne version du document est également possible.
- Après avoir mesuré le RTT du premier package, il est défini:
- SRTT: = RTT
- Rttvar: = 0,5 * RTT
- RTO: = RTT + 4 * RTTVAR (devrait être 4 * Rtttvar plus petit que la précision de mesure de la minuterie, il est ajouté à la place.)
- À chaque mesure supplémentaire du RTT ‘, les valeurs sont mises à jour (RTTVAR doit être calculé avant SRTT):
- Rttvar: = (1-β) * rttvar + β * | srtt-rtt ‘| (La variance est également lissée avec un facteur de β; puisque la variance spécifie une déviation moyenne (ce qui est toujours positif), la quantité d’écart par rapport à RTT estimé et réel est utilisée ici, et non la différence simple. Il est recommandé de choisir β = 1/4.)
- Srtt: = (1-α) * srtt + α * rtt ‘(ce n’est pas simplement le nouveau RTT’, mais il est lissé avec un facteur α. Il est recommandé de choisir α = 1/8.)
- RTO: = SRTT + 4 * RTTVAR (devrait être 4 * RTTVAR plus petit que la précision de mesure du temporisateur, il est ajouté à la place. Pour le RTO, une valeur minimale de 1 s s’applique – quel que soit le calcul; une valeur maximale peut également être attribuée si cela est au moins 60 s.)
En choisissant 2 puissances (4 ou 1/2, 1/4 etc.) comme facteurs, les calculs de l’implémentation peuvent être réalisés par de simples opérations de décalage.
L’algorithme de Karn de Phil Karn doit être utilisé pour mesurer le RTT; d. Autrement dit, seuls les packages sont utilisés pour la mesure, dont la confirmation arrive sans que le package soit renvoyé entre les deux. La raison en est que si la transmission était à nouveau, il ne serait pas clair lequel des packages répétés a été réellement confirmé, de sorte qu’une déclaration concernant le RTT n’est pas possible.
Si un package n’a pas été confirmé dans le temps mort, le RTO est doublé (sauf s’il a atteint la barrière supérieure en option). Dans ce cas (également facultatif), les valeurs trouvées pour SRTT et RTTVAR peuvent être réinitialisées à leur valeur initiale, car ils pourraient éventuellement perturber le recalcul du RTO.
Connexion du contrôle de la rivière et du contrôle des embouteillages [ Modifier | Modifier le texte source ]]
Dans les deux sections suivantes, les concepts TCP pour le contrôle de la rivière et le contrôle des embouteillages (ou le contrôle des surcharges) sont expliqués. Qui va Fenêtre coulissante et le Fenêtre de congestion introduit. L’émetteur sélectionne le minimum dans les deux fenêtres comme taille de fenêtre de diffusion réelle. Afin d’assurer une transmission fiable des données par le biais de répétitions de transmission, ainsi Arq-protokolle (Demande de répétition automatique anglaise, demande de répétition automatique allemande) Utilisé.
Contrôle de la rivière [ Modifier | Modifier le texte source ]]

Étant donné que l’application lit les données du tampon, le niveau de remplissage du tampon change constamment. Il est donc nécessaire de contrôler le flux de données en conséquence. Cela arrive avec ça Fenêtre coulissante Et sa taille.
Comme le montre la figure 8, nous élargissons le tampon de l’émetteur à 10 segments. Sur la figure 8a, les segments 1 à 5 viennent d’être transférés. La transmission est comparable à la figure 7. Bien que le tampon du destinataire de la figure 7 soit plein à la fin, il appelle les données suivantes du BYTE 7301 avec ACK = 7301. En conséquence, le prochain segment TCP ne peut plus être traité par le destinataire. Cependant, les exceptions sont des segments TCP avec un indicateur URG défini. Avec le champ de fenêtre, il peut dire au diffuseur qu’il ne devrait plus envoyer de données. Cela se produit en entrant la valeur zéro dans le champ de fenêtre (fenêtre zéro). La valeur de zéro correspond à l’espace libre dans le tampon. L’application du destinataire lit désormais les segments 1 à 5 à partir du tampon, avec lequel un espace de stockage de 7 300 octets est gratuit. Il peut donc demander les segments restants 6 à 10 avec un en-tête TCP qui contient les valeurs SEQ = 1, ACK = 7301 et Window = 7300. L’émetteur sait maintenant qu’il peut envoyer un maximum de cinq segments TCP au destinataire et déplace la fenêtre de cinq segments vers la droite (voir Fig. 8b). Les segments 6-10 sont maintenant tous ensemble comme Éclatement envoyé. Si tous les segments TCP arrivent au destinataire, il les reconnaît avec seq = 1 et ack = 14601 et demande les données suivantes.
- Syndrome de fenêtre idiote
- Le destinataire envoie un Fenêtre zéro à l’émetteur parce que son tampon est plein. Cependant, l’application du destinataire ne lit que deux octets du tampon. Le destinataire envoie un en-tête TCP avec Window = 2 (mise à jour de la fenêtre) vers l’émetteur et en même temps appelle les deux octets. L’émetteur est conforme à la demande et envoie les deux octets au destinataire dans un package de 42 octets (avec en-tête IP et en-tête TCP). Avec cela, le tampon du récepteur est à nouveau plein et il en envoie un autre Fenêtre zéro À l’émetteur. Par exemple, l’application lit maintenant une centaine d’octets du tampon. Le destinataire envoie un en-tête TCP à l’émetteur avec une petite valeur de fenêtre. Ce jeu continue et gaspille la bande passante car seuls de très petits packages sont envoyés. La solution de Clark est que le destinataire Fenêtre zéro envoie et pendant si longtemps avec ça Mise à jour de la fenêtre Devrait attendre que l’application ait lu au moins la taille maximale du segment (taille maximale du segment, dans nos exemples précédents 1460 octets) du tampon ou le tampon est à moitié leader – selon ce qui se produit en premier (Dave Clark, 1982). L’émetteur peut également envoyer des packages trop petits et gaspiller ainsi la bande passante. Ceci est éliminé avec l’algorithme Nagle. C’est pourquoi il se complète par la solution de Clark.
Contrôle de surcharge / contrôle des embouteillages (contrôle de la congestion) [ Modifier | Modifier le texte source ]]
Sur Internet, dans lequel de nombreux réseaux sont connectés à différentes propriétés, la perte de données de packages individuels est tout à fait normale. Si une connexion est fortement chargée, de plus en plus de packages sont rejetés, ce qui doit être répété en conséquence. En raison de la répétition, le fardeau augmente, sans mesures appropriées, il existe une congestion des données.
Le taux de perte est constamment observé par un réseau IP. Selon le taux de perte, le transmetteur est influencé par des algorithmes appropriés: généralement une connexion TCP / IP est lentement démarrée (démarrage lent) et le transmetteur augmente progressivement jusqu’à ce que la perte de données se produise. Une perte de données réduit le taux d’émetteur, sans perte, elle est augmentée. Dans l’ensemble, le débit de données aborde d’abord le maximum respectif disponible et y reste ensuite approximativement. Une surcharge est évitée.
Algorithme pour le contrôle de la surcharge [ Modifier | Modifier le texte source ]]
Si les packages sont perdus dans une certaine taille de fenêtre, cela peut être déterminé si l’émetteur ne reçoit aucune confirmation (ACK) dans un certain délai (délai d’attente). Il faut supposer que le package a été rejeté par un routeur sur Internet en raison d’une charge réseau trop élevée. Cela signifie que le tampon d’un routeur est plein; Il s’agit d’un embouteillage sur le net, pour ainsi dire. Afin de dissoudre les embouteillages, tous les émetteurs impliqués doivent réduire leur charge de réseau. Pour ce faire, dans le RFC 2581 Quatre algorithmes définis: démarrage lent , Évitement de la congestion , RetRansmit rapide et récupération rapide , par lequel démarrage lent et Évitement de la congestion peut être utilisé ensemble. Les deux algorithmes RetRansmit rapide et récupération rapide sont également utilisés ensemble et sont une expansion des algorithmes démarrage lent et Évitement de la congestion .
Démarrage lent et évitement de la congestion [ Modifier | Modifier le texte source ]]
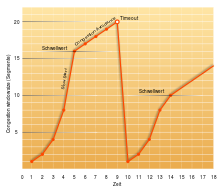
Au début d’une transmission de données, l’algorithme de démarrage lent sert à déterminer fenêtre de congestion (Littéralement: fenêtre de surcharge) pour éviter une éventuelle situation de surcharge. Vous souhaitez éviter les embouteillages, et comme l’utilisation actuelle du réseau n’est pas connue, de petites quantités de données commencent. L’algorithme commence par une petite fenêtre à partir d’un MSS (taille maximale du segment), dans lequel les packages de données sont transmis de l’émetteur au receveur.
Le destinataire renvoie désormais une confirmation (ACK) à l’émetteur. La taille du fenêtre de congestion augmenté par un MSS. Étant donné qu’un ACK est envoyé pour chaque colis envoyé à une transmission réussie, cela conduit à un doublement de la congrégation Windows dans un délai aller-retour. Dans cette phase, il y a une croissance exponentielle. Par exemple, si la fenêtre permet d’envoyer deux packages, l’émetteur reçoit également deux acks et augmente donc la fenêtre de 2 à 4. Cette croissance exponentielle se poursuivra jusqu’à ce que le SO Seuil de démarrage lent est accompli. seuil ,Seuil’). La phase de la croissance exponentielle est également Phase de démarrage lent appelé.
Après cela, la congrégation de fenêtre n’est augmentée que par un segment si tous les packages ont été transférés avec succès de la fenêtre. Donc, il ne croît que par un segment par temps aller-retour, donc seulement linéairement. Cette phase est comme Phase d’évitement de la congestion désigné. La croissance se termine lorsque la fenêtre de réception définie par le receveur a été atteinte (voir le contrôle de la rivière).
S’il y a un délai d’expiration, il va fenêtre de congestion réinitialiser avec 1 et le seuil de démarrage lent Est sur la moitié de la taille du vol (la taille du vol est le nombre de colis qui ont été envoyés, mais n’ont pas encore été reconnus) [8] réduit. La phase de croissance exponentielle est raccourcie, de sorte que la fenêtre se développe lentement avec des pertes de paquets fréquents.
Retransmit rapide et récupération rapide [ Modifier | Modifier le texte source ]]
Retransmit rapide et Récupération rapide (“Fast Relaxation”) sont utilisés pour réagir plus rapidement à la situation des embouteillages après une perte de package. Un destinataire informe l’émetteur lorsque les packages arrivent hors ligne et donc il y a une perte de package entre les deux. À cette fin, le destinataire confirme le dernier package correct l’un pour l’autre un package entrant hors de la ligne. On parle de Dup-à-arc ( Remerciements en double ), c’est-à-dire plusieurs messages consécutifs, qui sont le même segment de données. Le diffuseur remarque les confirmations dupliquées, et après le troisième double, il envoie à nouveau le package perdu avant l’expiration du minuteur. Parce qu’il n’a pas à attendre l’expiration de la minuterie, le principe signifie RetRansmit rapide . Les Sacs DUP sont également prouvés qu’une perte de colis a eu lieu, mais les paquets suivants sont arrivés. Par conséquent, la fenêtre de transmission n’est divisée par moitié qu’après l’erreur et ne recommencez pas avec le démarrage lent comme avec le délai d’attente. De plus, la fenêtre de transmission peut être augmentée par le nombre de sacs DUP, car chacun représente un autre package qui a atteint le destinataire, bien que hors ligne. Étant donné que les performances de transmission complètes sont atteintes plus rapidement après l’erreur, le principe est appelé Récupération rapide .
ACKS sélectifs (sac) [ Modifier | Modifier le texte source ]]
ACKS sélectifs sont utilisés pour retourner encore plus d’informations de contrôle via le flux de données du receveur vers l’émetteur. Après une perte de colis, un en-tête supplémentaire est inséré par le destinataire dans le champ Option TCP, à partir de laquelle la station peut voir exactement quels packages sont déjà arrivés et qui manque (contrairement aux ACK cumulative standard de TCP, voir ci-dessus). Les packages ne sont toujours considérés que si le destinataire a transmis un ACK pour les packages à l’expéditeur.
TCP-Tahoe und TCP-RENO [ Modifier | Modifier le texte source ]]
Les variantes de contrôle TCP Tahoe et Reno nommées d’après les emplacements au Nevada sont deux procédures différentes, telles que TCP sur un événement de surcharge sous la forme de Délais d’expiration ou Dup-à-arc réagi.
Le TCP Taoe, qui n’est plus utilisé, réduit dès qu’il y a un délai d’expiration, la fenêtre de la congrégation pour la prochaine unité de transmission à 1. Ensuite, le processus de démarrage TCP-SLOW (avec un seuil réduit, voir ci-dessous), jusqu’à ce qu’un nouvel temps mort ou du DuP-Sach ait lieu ou la valeur de seuil ( Seuil ) peut être atteint pour la transition vers la phase de conoocation-option. Ce seuil a été fixé sur la moitié de la taille de la fenêtre de congrégation actuelle après que l’événement de surcharge s’est produit. D’une part, l’inconvénient de cette procédure est qu’une perte de package n’est déterminée que par un délai d’expiration, donc parfois dure assez longtemps, et d’autre part, la forte réduction des fenêtres conge sur 1.
Le développement ultérieur de Tahoe est TCP-Reno. Une distinction est faite entre les événements de temps mort et DuP-Sachs qui se produisent: alors que TCP-Reno fait tout autant que TCP TAOE se produit lorsqu’un délai d’expiration se produit, il utilise une variante différente pour déterminer les fenêtres de congrégation suivantes lors de trois doublons. L’idée de base est que la perte d’un segment sur le chemin du destinataire peut non seulement être reconnue par un délai d’expiration, mais aussi par le fait que le destinataire avant renvoyé au segment perdu (chaque fois qu’il reçoit un autre segment après “l’écart”). Par conséquent, la congesation de fenêtre suivante est définie pour la moitié de la valeur de la congrégation de Window au moment de l’événement de surcharge; Ensuite, la phase d’évitement est à nouveau convertie. Comme mentionné ci-dessus dans l’article, ce comportement est Récupération rapide décrit.
Contrôle de surcharge comme domaine de recherche [ Modifier | Modifier le texte source ]]
La conception exacte du contrôle de la surcharge TCP était et est un domaine de recherche extrêmement actif avec de nombreuses publications scientifiques. Aujourd’hui encore, de nombreux scientifiques du monde entier travaillent sur des améliorations du contrôle des surcharges du TCP ou essaient de les adapter à certaines circonstances externes. Dans ce contexte, les conditions spéciales des différentes techniques de transmission sans fil doivent être mentionnées en particulier, ce qui entraîne souvent des retards de terme élevés ou fortement fluctuants ou des pertes de package trop élevées. Par défaut, TCP suppose que la route de transmission est occupée en tout lieu (congestion des données). C’est généralement le cas avec les réseaux liés à un fil, car il y a rarement des packages là-bas sur la ligne sont perdus, mais ont presque toujours été rejetés par un routeur surchargé. La bonne réaction à une telle «congestion des données» est donc la réduction du transmetteur. Dans le cas des réseaux sans fil, cependant, cette hypothèse ne s’applique plus. En raison du milieu de transmission beaucoup plus peu fiable, les pertes de paquets se produisent souvent sans que l’un des routeurs ne soit surchargé. Dans ce scénario, cependant, la réduction du transmetteur n’a pas de sens. Au contraire, une augmentation du transmetteur, par exemple par plusieurs expéditeurs de packages, pourrait augmenter la fiabilité de la connexion.
Ces changements ou extensions de contrôle des surcharges sont souvent basés sur des fondations mathématiques ou réglementaires complexes. Le projet d’améliorations correspondantes est tout sauf facile, car il est généralement nécessaire que les connexions TCP avec des mécanismes de contrôle des surcharges plus anciens ne soient pas considérablement désavantagés par les nouvelles méthodes si, par exemple, plusieurs connexions TCP avec la bande passante de la bande passante sur un support partagé. Pour toutes ces raisons, le contrôle de la surcharge TCP utilisé dans la réalité est également beaucoup plus compliqué que décrit ci-dessus dans l’article.
En raison des nombreuses recherches sur le contrôle de la surcharge TCP, divers mécanismes de contrôle des surcharges ont prévalu au fil du temps comme quasi-stands. TCP Reno, TCP Tahoo et TCP Vegas valent particulièrement la peine d’être mentionnés ici. Dans les systèmes d’exploitation modernes, TCP Cubic est utilisé comme algorithme de surplomb standard.
Dans ce qui suit, certaines approches plus récentes ou plus expérimentales doivent être à peu près décrites. Une approche est, par exemple, RCF (rétroaction de la conésion du routeur). Le routeur le long du chemin est envoyé des informations plus étendues aux canaux ou destinataires TCP afin qu’ils puissent mieux coordonner leur contrôle de surcharge de bout en bout. En conséquence, des augmentations de débit considérables sont prouvées. Des exemples de cela peuvent être trouvés dans la littérature sous les mots clés XCP ( protocole de contrôle explicite ), Ewa ( Adaptation à la fenêtre explicite ), S’élargir à ( Ewa flou ), Fxcp ( XCP flou ) et etc. ( TCP amélioré ) (Au milieu de -2004). De plus, c’est Notification de congestion explicite (ECN) Implémentation d’un RFC. Pour le dire simplement, ces procédures forment un contrôle de surcharge en fonction de l’ATM.
D’autres approches poursuivent la séparation logique de la boucle de contrôle d’une connexion TCP en deux boucles de contrôle ou plus aux endroits décisifs sur Internet (par exemple avec le soi-disant TCP divisé). Il existe également la méthode de regroupement logique de plusieurs connexions TCP dans une station TCP afin que ces composés puissent remplacer leurs informations sur la condition actuelle du réseau et réagir plus rapidement. Voici la procédure EFCM en particulier ( Gestion de la congestion des flux d’ensemble ) appeler. Toutes ces procédures peuvent être sous le terme Partage d’informations réseau être résumé.
L’en-tête pseudo est une compilation des parties d’en-tête d’un segment TCP et des parties de l’en-tête du package IP d’encapssuling. Il s’agit d’un modèle sur lequel le calcul de la somme du test TCP ( Anglais somme de contrôle ) Décrivez clairement.
Si IP est utilisé avec TCP, il est souhaitable d’inclure l’en-tête du package IP dans la sécurisation de TCP. Cela garantit la fiabilité de sa transmission. C’est pourquoi vous formez l’en-tête pseudo IP. Il se compose d’adresse de l’expéditeur IP et du récepteur, un octet zéro-octet qui indique le protocole auquel les données utilisateur du package IP incluent et la longueur du segment TCP avec l’en-tête TCP. Étant donné que dans le cas de l’en-tête pseudo, il s’agit toujours de packages IP qui transportent les segments TCP, cet octet est défini sur la valeur 6. L’en-tête pseudo est placé devant l’en-tête TCP pour calculer la somme de contrôle. Calculez ensuite la joue. La somme est stockée dans le champ “Tamis” et le fragment est envoyé. Aucun en-tête pseudo n’est jamais envoyé.
| Décalage de bit | Bits 0–3 | 4–7 | 8-15 | 16–31 | ||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Adresse du remplacement IP | |||||||||||||||||||||||||||||||
| 32 | Adresse du récepteur IP | |||||||||||||||||||||||||||||||
| soixante-quatre | 00000000 | 6 (= TCP) | TCP | |||||||||||||||||||||||||||||
| 96 | Quellport | Zielport | ||||||||||||||||||||||||||||||
| 128 | Numéro de séquence | |||||||||||||||||||||||||||||||
| 160 | Numéro ACK | |||||||||||||||||||||||||||||||
| 192 | Datenoffset | Réservé | Drapeaux | Fenêtre | ||||||||||||||||||||||||||||
| 224 | Sommet | Pointeur urgent | ||||||||||||||||||||||||||||||
| 256 | Options (en option) | |||||||||||||||||||||||||||||||
| 256/288 + | Données | |||||||||||||||||||||||||||||||
Le calcul du montant du test pour IPv4 est en RFC 793 Sont définis:
La somme d’essai est le complément 16 bits du complément total de tous les mots 16 bits dans l’en-tête et les données utiles du protocole sous-jacent. Si un segment contient des octets de nombre impair, un octet de rembourrage est attaché. Le rembourrage n’est pas transféré. Pendant le calcul de la somme de contrôle, le champ de somme d’essai lui-même est rempli de zéros.
En écart par rapport à cela, IPv6 voit l’en-tête pseudo selon RFC 2460 comme suit:
” Tout transport ou autre protocole de couche supérieure qui inclut les adresses de l’en-tête IP dans son calcul de somme de contrôle doit être modifiée pour une utilisation sur IPv6, pour inclure les adresses IPv6 128 bits au lieu d’adresses IPv4 32 bits. ”
| Décalage de bit | 0–7 | 8-15 | 16-23 | 24–31 | ||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Cette demande | |||||||||||||||||||||||||||||||
| 32 | ||||||||||||||||||||||||||||||||
| soixante-quatre | ||||||||||||||||||||||||||||||||
| 96 | ||||||||||||||||||||||||||||||||
| 128 | Adresse cible | |||||||||||||||||||||||||||||||
| 160 | ||||||||||||||||||||||||||||||||
| 192 | ||||||||||||||||||||||||||||||||
| 224 | ||||||||||||||||||||||||||||||||
| 256 | TCP | |||||||||||||||||||||||||||||||
| 288 | Zéro | En-tête suivant | ||||||||||||||||||||||||||||||
| 320 | Quellport | Zielport | ||||||||||||||||||||||||||||||
| 352 | Numéro de séquence | |||||||||||||||||||||||||||||||
| 384 | Numéro ACK | |||||||||||||||||||||||||||||||
| 416 | Datenoffset | Réservé | Drapeaux | Fenêtre | ||||||||||||||||||||||||||||
| 448 | Sommet | Pointeur urgent | ||||||||||||||||||||||||||||||
| 480 | Options (en option) | |||||||||||||||||||||||||||||||
| 480/512 + | Données | |||||||||||||||||||||||||||||||
Le destinataire crée également l’en-tête pseudo, puis effectue le même calcul sans définir le champ de somme de contrôle sur zéro. Cela devrait rendre le résultat FFFF (hexadécimal). Si ce n’est pas le cas, le segment TCP est rejeté sans message. En conséquence, le temporisateur RTT est à court de l’expéditeur et le segment TCP est à nouveau envoyé.
La raison de cette procédure compliquée est que les parties de l’en-tête IP changent dans le réseau IP pendant le routage. Le champ TTL est décrémenté de celui avec chaque IP-HOP. Si le champ TTL était incorporé dans le calcul de la somme d’essai, IP détruirait le transport du transport par TCP. Par conséquent, seule une partie de l’en-tête IP est incluse dans le calcul de la somme d’essai. D’une part, la quantité de test est sensible à des erreurs incroyables en raison de sa longueur de seulement 16 bits et en raison de la simple régulation de calcul. De meilleures procédures telles que CRC-32 étaient considérées comme trop coûteuses au moment de la définition.
Contrairement à la connexion avec la connexion, TCP implémente un flux de données bidirectionnel, orienté octet et fiable entre deux points de terminaison. Le protocole sous-jacent (IP) est orienté vers le package, par lequel les packages de données peuvent être perdus, peuvent arriver dans le mauvais ordre et peuvent même être reçus deux fois. TCP a été développé pour faire face à l’incertitude des couches en dessous. Il vérifie donc l’intégrité des données au moyen de la somme d’essai dans la tête du package et assure l’ordre par numéros de séquence. L’émetteur répète l’envoi de packages en cas de confirmation dans un certain délai (délai d’attente). Les données des packages sont fusionnées dans un flux de données dans un tampon dans un tampon dans le bon ordre et les packages doubles sont rejetés.
Bien sûr, le transfert de données peut être perturbé, retardé ou complètement interrompu à tout moment après “établir une connexion”. Le système de transmission se heurte ensuite à un délai d’attente. La «structure de connexion» réalisée à l’avance ne fournit donc aucune garantie d’une transmission sécurisée en permanence ultérieure.
La longueur respective du tampon, jusqu’à laquelle il n’y a pas d’espace dans le flux de données, est confirmé ( vitre ). Cela permet de profiter de la largeur du ruban du réseau, même sur de grandes itinéraires. En cas de connexion à l’étranger ou par satellite, l’arrivée du premier signal ACK prend parfois plusieurs 100 millisecondes pour des raisons techniques, pendant ce temps, plusieurs centaines de colis peuvent être envoyés. L’émetteur peut remplir le tampon receveur avant l’arrivée de la première confirmation. Tous les packages du tampon peuvent être confirmés ensemble. Les confirmations peuvent être insérées en plus des données dans l’en-tête TCP du flux de données opposé ( insouciant ) Si le destinataire dispose également de données pour l’émetteur.
- Douglas Comer: Internetworking avec TCP / IP. Principes, protocoles et architectures. Prentice Hall, 2000, ISBN 0-13-018380-6.
- Craig Hunt: Administration du réseau TCP / IP. O’Reilly, Bejing 2003, ISBN 3-89721-179-3.
- Richard Stevens: TCP / IP illustré. Volume 1. Les protocoles . Addison-Wesley, Boston 1994, 2004. ISBN 0-201-63346-9.
- Richard Stevens: TCP / IP illustré. 2ieme volume. La mise en oeuvre . Addison-Wesley, Boston 1994, ISBN 0-201-63354-X.
- Andrew S. Tanenbaum: Réseaux informatiques. 4e édition. Pearson Studium, Munich 2003, ISBN 978-3-8273-7046-4, p. 580 ff.
- James F. Kurose, Keith W. Ross: Réseaux informatiques. Une approche descendante en mettant l’accent sur Internet. Bafög Edition. Pearson Studies, Munich 2004, ISBN 3-8273-7150-3.
- Michael Tischer, Bruno Jennrich: Internet en interne. Technologie et programmation. Data-Becker, Düsseldorf 1997, ISBN 3-8158-1160-0.
RFC
- RFC 793 (Protocole de contrôle de la transmission)
- RFC 1071 (Calculez la somme du test pour IP, UDP et TCP)
- RFC 1122 (Fixation d’erreurs à TCP)
- RFC 1323 (Extensions à TCP)
- RFC 2018 (Sack TCP – Options de reconnaissance sélective)
- RFC 3168 (Notification de congestion explicite)
- RFC 5482 (Option TCP Timeout utilisateur)
- RFC 5681 (Contrôle de surcharge TCP de la conésion TCP)
- RFC 7414 (Aperçu des RFC TCP)
Autre
- ↑ Ne pas confondre avec emballer . La tâche de TCP n’est pas de transférer des packages, mais les octets d’un flux de données. La médiation du package est fournie par le protocole Internet (IP). Par conséquent, IP est médié par le package, mais le package TCP.
- ↑ Numéros de port. Internet Assigned Numbers Authority (IANA), 18. Juni 2010, Consulté le 7 août 2014 (Anglais).
- ↑ RFC 793. Internet Engineering Task Force (IETF), 1981. «Une demande ouverte passive signifie que le processus souhaite accepter les demandes de connexion entrantes plutôt que de tenter d’initier une connexion.»
- ↑ RFC 793. Internet Engineering Task Force (IETF), 1981. «Brièvement les significations des États sont: écouter – représente l’attente d’une demande de connexion à tout TCP et port distant.»
- ↑ W. Richard Stevens: TCP / IP Illustrated, vol. 1: les protocoles. Addison-Wesley, Kapitel 18.
- ↑ Steven M. Bellovin: RFC 1948 – Défendre contre les attaques du numéro de séquence . Internet Engineering Task Force (IETF), 1996
- ↑ RFC 6298 – Calcul de la minuterie de retransmission de TCP
- ↑ Stevens, W. Richard, Allman, Mark, Paxson, Vern: Contrôle de la congestion TCP. Consulté le 9 février 2017 (Anglais).
Recent Comments