Kana – Wikipedia wiki
Systèmes d’écriture syllabique japonaise
Le terme pas du tout ( Pseudonyme , Prononciation japonaise: [pas du tout] ) Peut se référer à un certain nombre de syllabaires utilisés pour écrire des unités phonologiques japonaises, Morae. Ces syllabes incluent (1) le kana d’origine, ou Parlant ( Vrai nom , littéralement «vrai kana») , [2] qui étaient des caractères chinois (kanji) utilisés phonétiquement pour transcrire le japonais, le système Magana le plus important étant Man’yōgana ( Dile permanent ) ; Les deux descendants de Man’yōgana, (2) Hiragana ( plat provisoire nom ) , [3] et (3) katakana ( pièce provisoire nom ) . Il y a aussi Hentaigana ( Kana intrait , Littéralement ‘variant kanna’) , qui sont des variantes historiques du Hiragana, désormais standard. Dans l’utilisation actuelle, le «kana» peut simplement signifier Hiragana et katakana .
Katakana, avec quelques ajouts, sont également utilisés pour écrire Ainu. Un certain nombre de systèmes existent pour écrire les langues Ryūkyūan, en particulier Okinawan, à Hiragana. Les kana taïwanais ont été utilisés dans Hokkien taïwanais comme gloss (texte rubis ou Furigana ) Pour les caractères chinois à Taïwan alors qu’il était sous domination japonaise.
Chaque caractère kana (syllabogramme) correspond à une syllabe son ou entière dans la langue japonaise, contrairement au script régulier de Kanji, qui correspond à un sens (logogramme). En dehors des cinq voyelles, c’est toujours CV (début de consonne avec noyau de voyelle), comme le , pour , etc., ou v (voyelle), comme un , je , etc., à la seule exception du graphème C pour les codas nasaux habituellement romanisés comme n . La structure a conduit certains chercheurs à étiqueter le système Morag , au lieu de syllabique , car il nécessite la combinaison de deux syllabogrammes pour représenter une syllabe CVC avec coda (c’est-à-dire CV n , CV m , CV de ), une syllabe CVV avec un noyau complexe (c’est-à-dire des voyelles multiples ou expressivement longues), ou une syllabe CCV avec un début complexe (c’est-à-dire une glisse, C et V, C Dans DANS).
Le nombre limité de phonèmes en japonais, ainsi que la structure des syllabes relativement rigides, font du système Kana une représentation très précise du japonais parlé.
Étymologie [ modifier ]]
‘Kana’ est un composé de idiome ( provisoire , ’emprunté; assumé; FAUX’) et n / A ( nom , ‘nom’) , qui s’est finalement effondré dans même et finalement «kana». [2]
Aujourd’hui, il est généralement supposé que «kana» était considéré comme «faux» kanji en raison de leur nature purement phonétique, par opposition à où ( vrai nom ) qui étaient «vrais» Kanji utilisés pour leur signification. Pourtant à l’origine, où et pas du tout étaient des termes purement calligraphiques avec où se référant aux caractères chinois écrits dans le script régulier ( kaisho ) et pas du tout se référant à ceux écrits dans le cursif ( sōsho ) style (voir Hiragana ). Ce n’est qu’au XVIIIe siècle que le début du pays kokugaku Le mouvement qui voulait s’éloigner du monde universitaire sinocentrique a commencé à réanalyser le script d’un point de vue phonologique. [4] Dans les siècles suivants, contrairement à la vision sinocentrique traditionnelle, pas du tout a commencé à être considéré comme un système d’écriture japonais national distinct des caractères chinois, qui est la vision dominante aujourd’hui.
Bien que le terme «kana» soit maintenant couramment compris comme Hiragana et Katakana, il a en fait une application plus large comme indiqué ci-dessous: [2]
- Pas du tout ( Pseudonyme , faux nom) ou pas du tout ( Caractère temporaire , faux caractère) : un syllabaire.
- Parlant ( Vrai nom , Vue Joseph’s) ou Otokogana ( Homme de l’homme , Kana pour hommes) : Kanji phonétique utilisé comme personnages syllabaires, historiquement utilisés par les hommes (qui étaient plus éduqués).
- Man’yōgana ( Dile permanent , kana utilisée dans le Man’yōshū ) : Le système le plus important de Magana.
- Sōgana ( 草仮名, Kana bâclée) : cursive man’yōgana.
- Hiragana (平仮名, flat kana), onnagana (女仮名, women’s kana), onnamoji (女文字, women’s script), onnade (女手, women’s hands)ou irohagana (伊呂波仮名): un syllabaire dérivé de sōgana simplifiés, historiquement utilisés par les femmes (qui étaient moins éduquées), historiquement triés Irohacommande.
- Hentaigana (変体仮名, variant kana) or itaigana (異体仮名): obsolete variants of hiragana.
- Hiragana (平仮名, flat kana), onnagana (女仮名, women’s kana), onnamoji (女文字, women’s script), onnade (女手, women’s hands)ou irohagana (伊呂波仮名): un syllabaire dérivé de sōgana simplifiés, historiquement utilisés par les femmes (qui étaient moins éduquées), historiquement triés Irohacommande.
- Katakana ( 片仮名, kana fragmentée) ou gojūongana ( 五十音仮名, cinquante-sept kana) : Un syllabaire dérivé en utilisant des morceaux de personnages à Man’yōgana, historiquement triés gojoon commande.
- Yamatogana ( 大和仮名, Kana de Yamato) : Hiragana et Katakana, par opposition à Kanji.
- Sōgana ( 草仮名, Kana bâclée) : cursive man’yōgana.
- Ogo ( Pseudonyme sonore , Soun Noly) : Magana pour transcrire des mots japonais, en utilisant, des lectures strictes ou lâches et dérivées de Chinois ( On’yomi ). Par exemple, yama ( Montagne , montagne) serait orthographié comme À la fin , avec deux magana avec on’yomi pour de et et ; de même, jalon ( personnes , humain) Orthographié comme Biden Force Salut et pour .
- Coopérative ( Nom enrigué , appris kana) : magana pour transcrire des mots japonais, en utilisant des mots natifs attribués à Kanji (“lectures” natives ou kun’yomi ). Par exemple, Yamato ( Grande paix ) serait orthographié comme Ruines , avec trois magana avec kun’yomi pour de , et et pour ; de même, natsukashi ( Nostalgique , évoquant la nostalgie) Orthographié comme xia ji pour natsu et os .
- Man’yōgana ( Dile permanent , kana utilisée dans le Man’yōshū ) : Le système le plus important de Magana.
- Parlant ( Vrai nom , Vue Joseph’s) ou Otokogana ( Homme de l’homme , Kana pour hommes) : Kanji phonétique utilisé comme personnages syllabaires, historiquement utilisés par les hommes (qui étaient plus éduqués).
- Où ( vrai nom , vrai nom) , où ( Véritable mot , vrai caractère) , Islanders ( Caractère masculin , Script pour hommes) ou Otokode ( Homme , les mains des hommes) : Kanji a utilisé pour les significations, historiquement utilisées par les hommes (qui étaient plus éduqués).
- Berger ( Pseudonyme , Mana et katakana) : Script mixte comprenant uniquement Kanji et Katakana.
Hiragana et Katakana [ modifier ]]
Le tableau suivant se lit, dans l’ordre de gojūon, comme un , je , dans , C’est , O (en bas de la première colonne), puis le , pour , pour , le , ce (Down Deuxième colonne), et ainsi de suite. n apparaît seul à la fin. Les astérisques marquent des combinaisons inutilisées.
- Il n’y a actuellement pas de kana pour vous , faire ou wu , comme les syllabes correspondantes ne se produisent pas nativement en japonais moderne.
- Le [pâle] ( vous ) Le son aurait existé dans le japonais pré-classique, principalement avant l’avènement de Kana, et peut être représenté par le man’yōgana kanji 江. [5] [6] Il y avait un Hiragana archaïque (
 ) [7] dérivé du man’yōgana vous Kanji ei, [5] qui est codé dans Unicode au point de code U + 1B001 (?) [8] [9] Mais il n’est pas largement pris en charge. On pense que C’est et vous d’abord fusionné à vous avant de revenir à C’est Pendant la période Edo. [6] Comme l’ont démontré des sources européennes de l’époque du XVIIe siècle, la syllabe nous (ゑ ・ ヱ) est également devenu prononcé comme [pâle] ( vous ). [dix] Si nécessaire, l’orthographe moderne permet [JE] ( vous ) Pour être écrit comme (ye), [ citation requise ]] Mais cette utilisation est limitée et non standard.
) [7] dérivé du man’yōgana vous Kanji ei, [5] qui est codé dans Unicode au point de code U + 1B001 (?) [8] [9] Mais il n’est pas largement pris en charge. On pense que C’est et vous d’abord fusionné à vous avant de revenir à C’est Pendant la période Edo. [6] Comme l’ont démontré des sources européennes de l’époque du XVIIe siècle, la syllabe nous (ゑ ・ ヱ) est également devenu prononcé comme [pâle] ( vous ). [dix] Si nécessaire, l’orthographe moderne permet [JE] ( vous ) Pour être écrit comme (ye), [ citation requise ]] Mais cette utilisation est limitée et non standard. - Le katakana moderne C’est , エ, dérive du man’yōgana 江, initialement prononcé vous ; [7] une “lettre katakana archaïque e” (
 ) dérivé du man’yōgana 衣 ( C’est ) [7] est codé dans Unicode au point de code U + 1B000 (?) [8] En raison de son utilisation à cette fin dans les travaux savants sur le japonais classique. [11]
) dérivé du man’yōgana 衣 ( C’est ) [7] est codé dans Unicode au point de code U + 1B000 (?) [8] En raison de son utilisation à cette fin dans les travaux savants sur le japonais classique. [11] - Certaines tables de gojūon publiées au cours du 19e siècle répertorient des katakana supplémentaires dans le vous (
 ), wu (
), wu ( 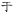 ) et faire (
) et faire (  ) positions. [douzième] Ceux-ci ne sont pas actuellement utilisés et les deux derniers sons n’ont jamais existé en japonais. [6] [13] Ils ont été ajoutés à Unicode dans la version 14.0 en 2021. [14] Ces sources indiquent également
) positions. [douzième] Ceux-ci ne sont pas actuellement utilisés et les deux derniers sons n’ont jamais existé en japonais. [6] [13] Ils ont été ajoutés à Unicode dans la version 14.0 en 2021. [14] Ces sources indiquent également 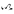 (Unicode U + 1B006,?) Dans le Hiragana faire positionner, et dans le vous position. [douzième]
(Unicode U + 1B006,?) Dans le Hiragana faire positionner, et dans le vous position. [douzième]
- Le [pâle] ( vous ) Le son aurait existé dans le japonais pré-classique, principalement avant l’avènement de Kana, et peut être représenté par le man’yōgana kanji 江. [5] [6] Il y avait un Hiragana archaïque (
- Bien que supprimé de l’orthographe standard avec le Gendai Kanazukii réformes, Wi et nous Voir toujours une utilisation stylistique, comme dans le whisky pour whisky Et yabis ou ebisu pour Jami ebisu, et yebisu, une marque nommée d’après Ebisu. Hiragana Wi et nous sont conservés dans certains scripts d’Okinawan, tandis que Katakana Wi et nous sont conservés dans la langue Ainu.
- où n’est préservé que comme la particule accusative, ne se produit normalement qu’à Hiragana.
- et , de , ce , hu , Wi , nous et où sont généralement romanisés respectivement comme il , dépenser , tsu , était , je , C’est et O Au lieu de cela, selon la prononciation contemporaine.
Diacritique [ modifier ]]
Les syllabes commençant par les consonnes vocales [g], [z], [d] et [b] sont orthographiées avec Kana à partir des colonnes non vocales correspondantes ( k , s , t et H ) et la marque de voix, Dakuten . Les syllabes commençant par [P] sont orthographiées avec Kana du H colonne et la marque à demi-voleur, Handakuten .
- Notez que les か ゚ ゚, ら ら ゚ ゚ et les entrées restantes dans les deux colonnes les plus à droite, bien qu’elles existent, ne sont pas utilisées dans l’orthographe japonaise standard.
- jour , De , et du sont souvent transcrits en anglais comme du , du , et pour Au lieu de cela, respectivement, selon la prononciation contemporaine.
- Habituellement, [VA], [VI], [VU], [VE], [VO] sont représentés respectivement par, par exemple, dans des mots de prêt tels que violon ( Baiorine “Violon”), mais (les moins habituellement) La distinction peut être préservée en utilisant [w-] avec des marques exprimées ou en utilisant [wu] et un kana volontaire, comme dans ヴァ (ヷ), ヴィ (〄 ). (ヹ ヹ ヹ ヹ), et ヴォ (ダ). Notez que ヴ n’avait pas de formulaire Hiragana codé par le JIS (ゔ) jusqu’à ce que JIS X 0213, ce qui signifie que de nombreuses saveurs JIS (y compris la version Windows et HTML5) ne peuvent que les réparateurs Unicode en tant que Unicode les deux.
Digraphes [ modifier ]]
Les syllabes commençant par des consonnes palatalisées sont orthographiées avec l’un des sept kana consonantes du je rangée suivie de petits de , yu ou ils . Ces digraphes sont appelés yōon.
- Il n’y a pas de digraphes pour le semi-vogue et et Dans Colonnes.
- Les digraphes sont généralement transcrits avec trois lettres, laissant de côté le je : C et V. Par exemple, Kya est transcrit comme appartenir pour le distinguer des deux kana き や, kiya .
- et + et * et de + et * sont souvent transcrits sh * et ch * au lieu de et * et entreprise* . Par exemple, est transcrit comme boire .
- Dans les japonais antérieurs, les digraphs pourraient également être formés avec Dans -Kana. Bien que obsolète en japonais moderne, les digraphs ense (/ kʷa /) et trates /). De plus, le kana え peut être utilisé à Ochawan pour former le digraphe の, qui représente le / kʷe / son.
- Notez que les entrées き゚ゃ, き゚ゅ et restantes dans la colonne la plus à droite, bien qu’elles existent, ne sont pas utilisées dans l’orthographe japonaise standard.
- aller , essentiel , et jyo sont souvent transcrits en anglais comme et , Bien , et parce que Au lieu de cela, respectivement, selon la prononciation contemporaine.
Utilisation moderne [ modifier ]]
La différence d’utilisation entre Hiragana et Katakana est stylistique. Habituellement, Hiragana est le syllabary par défaut et Katakana est utilisé dans certains cas spéciaux. Hiragana est utilisée pour écrire des mots japonais indigènes sans représentation kanji (ou dont le kanji est considéré comme obscur ou difficile), ainsi que des éléments grammaticaux tels que les particules et les inflexions (Okurigana). Aujourd’hui, Katakana est le plus souvent utilisé pour écrire des mots d’origine étrangère qui n’ont pas de représentations kanji, ainsi que des noms personnels et de lieux étrangers. Katakana est également utilisée pour représenter les onomatopées et les interjections, l’accent, les termes techniques et scientifiques, les transcriptions des lectures sino-japonaises de Kanji et une image de marque d’entreprise.
Kana peut être écrit sous une petite forme ci-dessus ou à côté de Kanji moins connue afin de montrer la prononciation; C’est ce qu’on appelle Furiganana. Furiganana est le plus utilisé dans les livres pour enfants ou apprenants. La littérature pour les jeunes enfants qui ne connaissent pas encore le kanji peut en s’y passer complètement et utiliser à la place Hiragana combinée à des espaces.
Les systèmes ne prenant en charge qu’un ensemble limité de caractères, tels que le code Wabun pour les télégrammes de code Morse et les encodages de caractères numériques à un octet tels que JIS X 0201 ou EBCDIK, se dispensent également avec Kanji, en utilisant uniquement Katakana. Ce n’est pas nécessaire dans les systèmes prenant en charge les encodages de double octet ou de largeur variable tels que Shift JIS, EUC-JP, UTF-8 ou UTF-16.
Histoire [ modifier ]]

Le vieux japonais a été entièrement écrit en Kanji, et un ensemble de kanji appelé Man’yōgana ont d’abord été utilisés pour représenter les valeurs phonétiques des particules grammaticales et des morphèmes. Comme il n’y avait pas de méthode cohérente de représentation du son, un phonème pouvait être représenté par plusieurs kanji, et même ces prononciations de Kana différaient si elles devaient être lues comme coopérative ( Nom enrigué , “Signification sur”) ou ogo ( Pseudonyme sonore , “Soudun twɔ”) , rendre le déchiffrement problématique. Le man’yōshū , une anthologie de poésie assemblée quelque temps après 759 et l’éponyme de Man’yōgana , illustre ce phénomène, où jusqu’à près de vingt kanji ont été utilisés pour la mora le . La cohérence du kana utilisée dépendait donc du style de l’écrivain. Hiragana s’est développée comme un script distinct de cursif Man’yōgana , tandis que Katakana s’est développé à partir de parties abrégées du script régulier Man’yōgana En tant que système de brise pour ajouter des lectures ou des explications aux sutras bouddhistes. Ces deux systèmes ont été simplifiés pour faciliter l’écriture. Les formes de nombreux Hiragana ressemblaient au script cursif chinois, tout comme ceux de nombreux katakana le coréen potins , suggérant que les Japonais ont suivi le modèle continental de leurs voisins. [15]
Kana aurait été inventé par le prêtre bouddhiste Kūkai au IXe siècle. Kūkai a certainement ramené le scénario de Siddhaṃ de l’Inde à son retour de Chine en 806; [ citation requise ]] Son intérêt pour les aspects sacrés de la parole et de l’écriture l’a conduit à la conclusion que les Japonais seraient mieux représentés par un alphabet phonétique que par le Kanji qui avait été utilisé jusqu’à ce point. L’arrangement moderne de Kana reflète celui de Siddhaṃ, mais le traditionnel Iroha L’arrangement suit un poème qui utilise chaque kana une fois.
Cependant, Hiragana et Katakana n’ont pas rapidement supplanté Man’yōgana . Ce n’est qu’en 1900 que l’actuel ensemble de Kana a été codifié. Toutes les autres formes de Hiragana et de Katakana se sont développées avant la codification de 1900 appelée Hentaigana ( Kana intrait , “Variant Kana”) . Règles pour leur utilisation conformément aux réformes de l’orthographe de 1946, le Gendai Kana-Zukai ( Kana moderne , “Utilisation actuelle des kana”) , qui a aboli le kana pour Wi (ゐ ・ ヰ), nous (ゑ ・ ヱ), et et et où (を ・ ・) (sauf que le dernier était réservé comme particule accusative). [15]
| un | je | dans | C’est | O | =: ≠ | |
|---|---|---|---|---|---|---|
| – | ≠ | ≠ | = | ≠ | = | 2: 3 |
| k | = | = | = | ≠ | = | 4: 1 |
| s | ≠ | = | ≠ | = | = | 3: 2 |
| t | ≠ | ≠ | = | = | = | 3: 2 |
| n | = | = | = | = | = | 5: 0 |
| H | ≠ | = | = | = | = | 4: 1 |
| m | = | ≠ | ≠ | = | = | 3: 2 |
| et | = | = | = | 3: 0 | ||
| r | = | = | ≠ | = | = | 4: 1 |
| Dans | = | ≠ | = | ≠ | 2: 2 | |
| n | ≠ | 0: 1 | ||||
| =: ≠ | 6: 4 | 5: 4 | 6: 4 | 7: 2 | 9: 1 | 33:15 |
Collation [ modifier ]]
Les kana sont à la base de la collation en japonais. Ils sont pris dans l’ordre donné par le gojoon (Ai Ueo … wow), bien que l’ordre iroha (Iroha Nihoho … Sesusu (n)) soit utilisé pour l’énumération. tsu et diacritiques. Comme le japonais n’utilise pas d’espaces de mots (sauf comme outil pour les enfants), il ne peut y avoir de collation mot par mot; Toute collation est kana-by-kana.
En Unicode [ modifier ]]
La gamme Hiragana dans Unicode est U + 3040 … U + 309F, et la gamme Katakana est U + 30A0 … U + 30FF. Les personnages obsolètes et rares ( Wi et nous ) ont également leurs points de code appropriés.
| Hiragana [d’abord] [2] Graphique officiel du code du consortium Unicode (PDF) |
||||||||||||||||
| 0 | d’abord | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | UN | B | C | D | ET | F | |
| U + 304x | ah | un | ぃ | estomac | ぅ | cormoran | ぇ | image | MM | Oh | moustique | mais | arbre | Geste | neuf | |
| U + 305x | ingrédient | cheveux | faible | enfant | Gibier | différence | siège | décès | personnage | vinaigre | chiffre | hauteur | Pour | ancêtre | Pour | rizière |
| U + 306x | est | sang | écriture | Au-delà | Dédié | Pour | main | et | et | degré | Nommé | Sur | Lanterne | Hé | de | dents |
| U + 307x | palé | Sacrifice | feu | Beauté | ぴ | dette | Battement | Plaque | Pet | Être | Sort | Ho | Se brouiller | ぽ | diable | fruit |
| U + 308x | rien | œil | et | Tater | ou | Pour | eau chaude | ょ | monde | et d’autres | la loi de la nature | Être | Vanité | réacteur | ゎ | cercle |
| U + 309x | ゐ | ゑ | de | Ouais | Persistant | Persistant | Persistant | ゙ | ゚ | ゛ | ゜ | ゝ | ゞ | Depuis | ||
Remarques
|
||||||||||||||||
| Katakana [d’abord] Graphique officiel du code du consortium Unicode (PDF) |
||||||||||||||||
| 0 | d’abord | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | UN | B | C | D | ET | F | |
| U + 30ax | ゠ | AA | ah | Pour | estomac | ゥ | lièvre | E | ouvrier | ォ | O | pouvoir | Mame | arbre | Galvan | neuf |
| U + 30bx | GU | Enfant | Gagner | unité | Aller | SA | Le | Sacrifice | Ji | vinaigre | Pour | Séquence | Être | Sobre | Fermeture éclair | rizière |
| U + 30cx | Da | sang | Picotements | ッ | tsu | ヅ | bronzer | Acte | porte | De | légume | N | Nouilles | Ne | de | C |
| U + 30dx | Bar | Paddy | Enfer | Être | Pigeon | centre | Sarrasin | P | F | Au-delà | Saigner | Ha | Bêle | Pote | pose | Mi |
| U + 30ex | Folie | Moi | Mame | Toi | Toi | lionceau | Yu | ョ | Toi | UN | Ri | Dans | Lésion | B | ヮ | Ouah |
| U + 30fx | ヰ | ヱ | ヲ | Hmm | Ve | Avertir | Écart | Persistant | Persistant | Persistant | Persistant | ・ | ー | ヽ | ヾ | Persistant |
Remarques
|
||||||||||||||||
Les caractères U + 3095 et U + 3096 sont Hiragana Small le et petit le , respectivement. U + 30F5 et U + 30F6 sont leurs équivalents Katakana. Les caractères U + 3099 et U + 309A combinent Dakuten et Handakuten, qui correspondent aux caractères d’espacement U + 309B et U + 309C. U + 309D est la marque d’itération Hiragana, utilisée pour répéter un Hiragana précédent. U + 309E est la marque d’itération Hiragana exprimée, qui représente le Hiragana précédent mais avec la consonne exprimée ( k devient g , H devient b , etc.). U + 30FD et U + 30FE sont les marques d’itération de Katakana. U + 309f est une ligature de il (より) parfois utilisé dans l’écriture verticale. U + 30ff est une ligature de koto (コト), également trouvé dans l’écriture verticale.
De plus, il existe des équivalents de demi-largeur au Katakana Fullwidth standard. Ceux-ci sont codés dans le bloc Halfwidth et FullWidth Forms (U + FF00 – U + FFEF), en commençant par U + FF65 et en se terminant à U + FF9F (caractères U + FF61 – U + FF64 sont des marques de ponctuation de demi-large):
| Sous-ensemble de Katakana de Halfwidth et Fullwidth Forms [d’abord] Graphique officiel du code du consortium Unicode (PDF) |
||||||||||||||||
| 0 | d’abord | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | UN | B | C | D | ET | F | |
| … | (U + FF00 – U + FF64 omis) | |||||||||||||||
| U + ff6x | ・ | ヲ | ァ | ィ | ゥ | ェ | ォ | Appliquer | Pour | Couor | ッ | |||||
| U + ff7x | | ア | je | ウ | Couru | オ | カ | キ | Ku | ケ | コ | SA | Sashimi | Sacrifice | セ | Maverge |
| U + ff8x | Lanterne | チ チ | ツ | テ | Pour | ナ | ニ | ヌ | N / A | ノ | Haha | ヒ | Conflit | ヘ | Hohn | マ |
| U + ff9x | ミ | Exploiter | Tailleur | モ | Pour | ユ ユ | ヨ | Lanterne | リ | ル | レ | ロ | je | Lanterne | ゙ | ゚ |
| … | (U + FFA0 – U + FFEF omis) | |||||||||||||||
Remarques
|
||||||||||||||||
Il existe également une petite gamme “Katakana Phonetic Extensions” (U + 31F0 … U + 31FF), qui comprend quelques petits caractères Kana supplémentaires pour écrire la langue Ainu. D’autres petits caractères de kana sont présents dans le bloc “Small Kana Extension”.
Unicode comprend également “Katakana Letter Archaic E” (U + 1B000), ainsi que 255 Hiragana archaïque, dans le bloc de supplément Kana. [16] Il comprend également 31 autres Hiragana archaïques dans le bloc Kana Extended-A. [17]
| Supplément Kana [d’abord] Graphique officiel du code du consortium Unicode (PDF) |
||||||||||||||||
| 0 | d’abord | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | UN | B | C | D | ET | F | |
| U + 1B00X | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
| U + 1b01x | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
| U + 1b02x | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
| U + 1B03X | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
| Et + 1b04x | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
| U + 1B05X | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
| U + 1b06x | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
| Et + 1b07x | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
| U + 1B08X | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
| U + 1b09x | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
| U + 1b0ax | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
| Et + 1b0bx | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
| U + 1b0cx | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
| Et + 1b0dx | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
| U + 1b0ex | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
| U + 1b0fx | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
Remarques
|
||||||||||||||||
| Kana étendu-a [d’abord] [2] Graphique officiel du code du consortium Unicode (PDF) |
||||||||||||||||
| 0 | d’abord | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | UN | B | C | D | ET | F | |
| U + 1b10x | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
| U + 1b11x | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
| U + 1b12x | ? | ? | ? | |||||||||||||
Remarques
|
||||||||||||||||
Le bloc Kana Extended-B a été ajouté en septembre 2021 avec la sortie de la version 14.0:
Voir également [ modifier ]]
Les références [ modifier ]]
- ^ Thomas E. McAuley, Changement de langue en Asie de l’Est, 2001: 90
- ^ un b c Super daijinbayashi [ Super daijirin ].
- ^ Hatasa, Yukiko Abe; Kazumi Hatasa; Seiichi Makino (2010). Nakama 1: Japonais d’introduction: communication, culture, contexte 2e éd . Heinning. p. 2. ISBN 978-0495798187 .
- ^ Tawada, Yoko (2020). En écrivant et en réécriture . Londres: Lexington Books. p. 43. ISBN 978-1-4985-9004-4 .
- ^ un b Seeley, Christopher (1991). Une histoire d’écriture au Japon . pp. 109 (note de bas de page 18). ISBN 90-04-09081-9 .
- ^ un b c “Y a-t-il un symbole de kana pour ye ou yi?” . SLJ FAQ . Récupéré 4 août 2016 .
- ^ un b c Katō, Nozomu (2008-01-14). “JTC1 / SC2 / WG2 N3388: proposition pour coder deux caractères de kana concernant vous” (PDF) . Récupéré 4 août 2016 .
- ^ un b “Supplément Kana” (PDF) . Unicode 6.0 . Unicode. 2010 . Récupéré 22 juin 2016 .
- ^ Plus d’informations sont disponibles à JA: Yae sur le wikipedia japonais.
- ^ “Charte de kana japonaise des Pays-Bas” . www.raccoonbend.com .
- ^ Katō, Nozomu. “L2 / 08-359: À propos de Wg2 N3528” (PDF) .
- ^ un b “Récolte à Izu” (en japonais). Archivé de l’original le 2008-03-03.
- ^ Plus d’informations sont disponibles à Ja: faire , JA: Yai et JA: Le 50e # 51 tous les personnages / sons qui sont tous différents: Meiji de la fin de la période Edo sur le wikipedia japonais.
- ^ “Kana étendue-A” (PDF) . UNICODE 14.0 CODE DE DELTA . Consortium Unicode. 2021.
- ^ un b Frellesvig, Bjarke (2010). Une histoire de la langue japonaise . La presse de l’Universite de Cambridge. pp. 12, 17, 23–24, 158–160, 173. ISBN 978-0-521-65320-6 . Récupéré 2022-03-07 .
- ^ https://www.unicode.org/charts/pdf/u1b000.pdf [ URL nue PDF ]]
- ^ https://www.unicode.org/charts/pdf/u1b100.pdf [ URL nue PDF ]]
Liens externes [ modifier ]]
Recent Comments