Lucid (langage de programmation) – Wikipedia wiki
Un article de Wikipédia, l’encyclopédie libre
Lucide est un langage de programmation de flux de données conçu pour expérimenter avec des modèles de programmation Neumann non VON. Il a été conçu par Bill Wadge et Ed Ashcroft et décrit dans le livre de 1985 Lucid, le langage de programmation de flux de données . [d’abord]
Plucid a été le premier interprète de Lucid.
Lucide Utilise un modèle axé sur la demande pour le calcul des données. Chaque instruction peut être comprise comme une équation définissant un réseau de processeurs et de lignes de communication entre eux à travers lesquels les données circulent. Chaque variable est un flux infini de valeurs et chaque fonction est un filtre ou un transformateur. L’itération est simulée par les valeurs «actuelles» et l’opérateur «FBY» (lire comme «suivi») permettant la composition des flux.
Lucid est basé sur une algèbre d’histoires, une histoire étant une séquence infinie d’éléments de données. Sur le plan opérationnel, une histoire peut être considérée comme un enregistrement des valeurs changeantes d’une variable, des opérations historiques telles que First et Next peuvent être comprises d’une manière suggérée par leurs noms. Lucid a été à l’origine conçu comme une langue disciplinée et mathématiquement pure et unique, dans laquelle la vérification serait simplifiée. Cependant, l’interprétation du flux de données a été une influence importante sur la direction dans laquelle Lucid a évolué. [d’abord]
Détails [ modifier ]]
Dans Lucid (et d’autres langues de flux de données), une expression qui contient une variable qui n’a pas encore été liée attend jusqu’à ce que la variable ait été liée, avant de procéder. Une expression comme x + y Attendra que X et Y soient liés avant de revenir avec la sortie de l’expression. Une conséquence importante de cela est que la logique explicite pour la mise à jour des valeurs connexes est évitée, ce qui entraîne une réduction substantielle du code, par rapport aux langues grand public.
Chaque variable de Lucid est un flux de valeurs. Une expression n = 1 fby n + 1 définit un flux
Utilisation de l’opérateur «FBY» (un mnémonique pour «suivi de»). FBY définit ce qui arrive après le précédent
expression. (Dans ce cas, le flux produit 1,2,3, …).
Les valeurs d’un flux peuvent être traitées par ces opérateurs (en supposant que X est la variable utilisée):
'Premier x' – Répondance à la première valeur dans le flux x,
'X' – la valeur actuelle du flux,
'Suivant X' – Repare la valeur suivante dans le flux.
'Travail' – Un opérateur qui fait quelque chose «dès que« la condition donnée devient vraie.
'x sur p' – On est un opérateur qui répète l’ancienne valeur du flux X, et se met à jour des nouvelles valeurs uniquement lorsque le flux P fabrique un vrai valeur disponible. (Il sert à ralentir le flux x)
c’est à dire.: x sur p est le flux x avec de nouvelles valeurs apparaissant sur la vérité de p.
Le calcul est effectué en définissant des filtres ou des fonctions de transformation qui agissent sur ces flux de données variant dans le temps.
Exemples [ modifier ]]
Factoriel [ modifier ]]
facteur
où
n = 0 fby (n + 1);
fac = 1 fby (fac * (n + 1));
fin
Séquence de fibonacci [ modifier ]]
mensonge
où
fib = 0 fby (1 fby fib + fib suivant);
fin
Total d’une séquence [ modifier ]]
total
où
total = 0 fby total + x
fin;
Moyenne de course [ modifier ]]
running_avg
où
sum = premier (entrée) fby sum + suivant (entrée);
n = 1 fby n + 1;
running_avg = sum / n;
fin;
nombres premiers [ modifier ]]
prime
où
prime = 2 fby (n chaque fois iSprime (n));
n = 3 fby n + 1;
isprime (n) = pas (divs) asa divs ou prime * prime> n
où
N est le courant n;
divs = n mod prime eq 0;
fin;
fin
Diagramme de flux de données [ modifier ]]
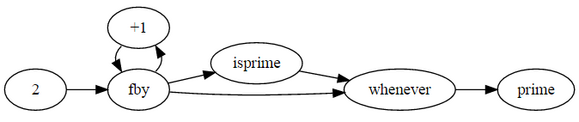
Tri rapide [ modifier ]]
Qsort (a) = si eof (d'abord a) alors a else suivent (qsort (b0), qsort (b1)) fi
où
p = d'abord a
Diagramme de flux de données [ modifier ]]
--------> chaque fois -----> QSORT ---------
| ^ |
| | |
| pas |
| ^ |
| ---> Premièrement | |
| | | |
| V | |
| ---> moins --- |
| | |
| V V
--- + --------> chaque fois -----> qsort -----> con -------> ifthenelse ----->
| ^ ^
| | |
--------> Suivant ----> First ------> Iseod -------------- |
| |
-------------------------------------------------- ---------
Carré moyen racine [ modifier ]]
sqroot (avg (carré (a)))
où
carré (x) = x * x;
avg (y) = moyenne
où
n = 1 fby n + 1;
moyenne = d'abord y fby moyenne + d;
d = (suivant y - moyenne) / (n + 1);
fin;
sqroot (z) = environ ASA err <0,0001
où
Z est le courant z;
approx = z / 2 fby (environ + z / approx) / 2;
err = abs (carré (approx) -z);
fin;
fin
Problème de marteau [ modifier ]]
H
où
h = 1 fby fusion (fusion (2 * h, 3 * h), 5 * h);
fusionner (x, y) = si xx <= yy alors xx else yy fi
où
xx = x sur xx <= yy;
yy = y sur yy <= xx;
fin;
fin;
Diagramme de flux de données [ modifier ]]

Les références [ modifier ]]
Liens externes [ modifier ]]
Recent Comments