Informationsmodell – Wikipedia
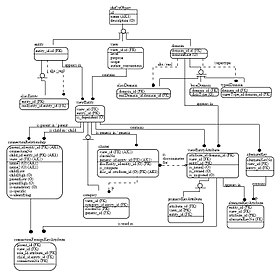
Ein Informationsmodell In der Softwareentwicklung werden Konzepte und Beziehungen, Einschränkungen, Regeln und Operationen dargestellt, um die Datensemantik für einen ausgewählten Diskursbereich festzulegen. Typischerweise spezifiziert es Beziehungen zwischen Arten von Dingen, kann aber auch Beziehungen zu einzelnen Dingen einschließen. Es kann eine gemeinsam nutzbare, stabile und organisierte Struktur von Informationsanforderungen oder Wissen für den Domänenkontext bereitstellen.[1]
Überblick[edit]
Der Begriff Informationsmodell Im Allgemeinen wird es für Modelle einzelner Dinge wie Einrichtungen, Gebäude, Prozessanlagen usw. verwendet. In diesen Fällen ist das Konzept auf Anlageninformationsmodelle, Gebäudeinformationsmodelle, Anlageninformationsmodelle usw. spezialisiert. Ein solches Informationsmodell ist eine Integration eines Modells der Einrichtung mit den Daten und Dokumenten über die Einrichtung.
Im Bereich Software-Engineering und Datenmodellierung ist ein Informationsmodell normalerweise eine abstrakte, formale Darstellung von Entitätstypen, die ihre Eigenschaften, Beziehungen und die Operationen enthalten können, die mit ihnen ausgeführt werden können. Die Entitätstypen im Modell können Arten von Objekten der realen Welt sein, z. B. Geräte in einem Netzwerk oder Vorkommen, oder sie können selbst abstrakt sein, z. B. für die in einem Abrechnungssystem verwendeten Entitäten. In der Regel werden sie zum Modellieren einer eingeschränkten Domäne verwendet, die durch einen geschlossenen Satz von Entitätstypen, Eigenschaften, Beziehungen und Operationen beschrieben werden kann.
Ein Informationsmodell bietet Formalismus für die Beschreibung einer Problemdomäne, ohne die Zuordnung dieser Beschreibung zu einer tatsächlichen Implementierung in Software einzuschränken. Es kann viele Zuordnungen des Informationsmodells geben. Solche Zuordnungen werden als Datenmodelle bezeichnet, unabhängig davon, ob es sich um Objektmodelle (z. B. unter Verwendung von UML), Entitätsbeziehungsmodelle oder XML-Schemata handelt.
Informationsmodellierungssprachen[edit]
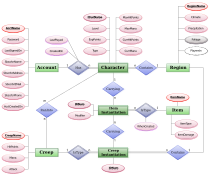

1976 wurde von Peter Chen eine grafische Notation für Entity-Relationship (ER) eingeführt. Er betonte, dass es sich um eine “semantische” Modellierungstechnik handele und unabhängig von Datenbankmodellierungstechniken wie Hierarchical, CODASYL, Relational usw. sei.[2] Seitdem haben sich die Sprachen für Informationsmodelle weiterentwickelt. Einige Beispiele sind die Integrated Definition Language 1 Extended (IDEF1X), die EXPRESS-Sprache und die Unified Modeling Language (UML).[1]
Forschungen von Zeitgenossen von Peter Chen wie JRAbrial (1974) und GM Nijssen (1976) führten zu den heutigen FOM-Sprachen (Fact Oriented Modeling), die eher auf sprachlichen Aussagen als auf “Entitäten” basieren. FOM-Tools können verwendet werden, um ein ER-Modell zu generieren, was bedeutet, dass der Modellierer die zeitaufwändige und fehleranfällige Praxis der manuellen Normalisierung vermeiden kann. Die Sprache der Objektrollenmodellierung (ORM) und die vollständig kommunikationsorientierte Informationsmodellierung (FCO-IM) sind beide Forschungsergebnisse, die auf früheren Forschungen basieren.
In den 1980er Jahren gab es verschiedene Ansätze, um Chens Entity Relationship Model zu erweitern. Ebenfalls wichtig in diesem Jahrzehnt ist REMORA von Colette Rolland.[3]
Die ICAM-Definitionssprache (IDEF) wurde im Zeitraum 1976 bis 1982 aus dem ICAM-Programm der US-Luftwaffe entwickelt.[4] Das Ziel des ICAM-Programms war laut Lee (1999) die Steigerung der Fertigungsproduktivität durch systematische Anwendung der Computertechnologie. IDEF umfasst drei verschiedene Modellierungsmethoden: IDEF0, IDEF1 und IDEF2 zum Erstellen eines Funktionsmodells, eines Informationsmodells bzw. eines dynamischen Modells. IDEF1X ist eine erweiterte Version von IDEF1. Die Sprache ist gemeinfrei. Es ist eine grafische Darstellung und wird unter Verwendung des ER-Ansatzes und der relationalen Theorie entworfen. Es wird verwendet, um die „reale Welt“ in Bezug auf Entitäten, Attribute und Beziehungen zwischen Entitäten darzustellen. Die Normalisierung wird durch KEY Structures und KEY Migration erzwungen. Die Sprache identifiziert Eigenschaftsgruppierungen (Aggregation), um vollständige Entitätsdefinitionen zu bilden.[1]
EXPRESS wurde als ISO 10303-11 erstellt, um die Informationsanforderungen des Produktdatenmodells formal festzulegen. Es ist Teil einer Reihe von Standards, die informell als STandard für den Austausch von Produktmodelldaten (STEP) bezeichnet werden. Es wurde erstmals in den frühen 1990er Jahren eingeführt.[5][6] Die Sprache ist nach Lee (1999) eine Textdarstellung. Darüber hinaus ist eine grafische Teilmenge von EXPRESS mit dem Namen EXPRESS-G verfügbar. EXPRESS basiert auf Programmiersprachen und dem OO-Paradigma. Eine Reihe von Sprachen haben zu EXPRESS beigetragen. Insbesondere Ada, Algol, C, C ++, Euler, Modula-2, Pascal, PL / 1 und SQL. EXPRESS besteht aus Sprachelementen, die eine eindeutige Objektdefinition und die Angabe von Einschränkungen für die definierten Objekte ermöglichen. Es verwendet die SCHEMA-Deklaration, um die Partitionierung bereitzustellen, und unterstützt die Angabe von Dateneigenschaften, Einschränkungen und Operationen.[1]
UML ist eine Modellierungssprache zum Spezifizieren, Visualisieren, Konstruieren und Dokumentieren der Artefakte und nicht der Prozesse von Softwaresystemen. Es wurde ursprünglich von Grady Booch, James Rumbaugh und Ivar Jacobson konzipiert. UML wurde 1997 von der Object Management Group (OMG) als Standard genehmigt. Die Sprache ist laut Lee (1999) nicht proprietär und für die Öffentlichkeit zugänglich. Es ist eine grafische Darstellung. Die Sprache basiert auf dem objektorientierten Paradigma. UML enthält Notationen und Regeln und dient zur Darstellung der Datenanforderungen in Form von OO-Diagrammen. UML organisiert ein Modell in einer Reihe von Ansichten, die verschiedene Aspekte eines Systems darstellen. Der Inhalt einer Ansicht wird in Diagrammen beschrieben, die Diagramme mit Modellelementen sind. Ein Diagramm enthält Modellelemente, die allgemeine OO-Konzepte wie Klassen, Objekte, Nachrichten und Beziehungen zwischen diesen Konzepten darstellen.[1]
IDEF1X, EXPRESS und UML können alle verwendet werden, um ein konzeptionelles Modell zu erstellen, und laut Lee (1999) hat jedes seine eigenen Eigenschaften. Obwohl einige zu einer natürlichen Nutzung führen können (z. B. Implementierung), ist eine nicht unbedingt besser als eine andere. In der Praxis kann es erforderlich sein, mehr als eine Sprache zu verwenden, um alle Informationsmodelle zu entwickeln, wenn eine Anwendung komplex ist. Tatsächlich ist die Modellierungspraxis oft wichtiger als die gewählte Sprache.[1]
Informationsmodelle können auch in formalisierten natürlichen Sprachen wie Gellish ausgedrückt werden. Gellish mit natürlichen Sprachvarianten Gellish Formal English, Gellish Formal Dutch (Gellish Formeel Nederlands)usw. ist eine Informationsrepräsentationssprache oder Modellierungssprache, die in der Gellish Smart Dictionary-Taxonomy definiert ist und die Form einer Taxonomie / Ontologie hat. Eine Gellish-Datenbank eignet sich nicht nur zum Speichern von Informationsmodellen, sondern auch von Wissensmodellen, Anforderungsmodellen und Wörterbüchern, Taxonomien und Ontologien. Informationsmodelle in Gellish English verwenden Gellish Formal English-Ausdrücke. Ein geografisches Informationsmodell kann beispielsweise aus einer Reihe von Gellish Formal English-Ausdrücken bestehen, z.
- the Eiffel towerParis - Paris city
Informationsanforderungen und Kenntnisse können beispielsweise wie folgt ausgedrückt werden:
- towergeographical area - city geographical area
Solche Gellish-Ausdrücke verwenden Namen von Konzepten (wie ‘Stadt’) und Beziehungstypen (wie ⟨ist in⟩ und ⟨ist als a⟩ klassifiziert), die aus der Gellish Formal English Dictionary-Taxonomie (oder Ihrer eigenen) ausgewählt werden sollten Domain-Wörterbuch). Die Gellish English Dictionary-Taxonomy ermöglicht die Erstellung semantisch reichhaltiger Informationsmodelle, da das Wörterbuch Definitionen von mehr als 40000 Konzepten enthält, darunter mehr als 600 Standardrelationstypen. Daher besteht ein Informationsmodell in Gellish aus einer Sammlung von Gellish-Ausdrücken, die diese Phrasen und Wörterbuchkonzepte verwenden, um Fakten auszudrücken oder Aussagen, Fragen und Antworten zu treffen.
Standardsätze von Informationsmodellen[edit]
Die Distributed Management Task Force (DMTF) bietet einen Standardsatz von Informationsmodellen für verschiedene Unternehmensdomänen unter dem allgemeinen Titel Common Information Model (CIM). Spezifische Informationsmodelle werden von CIM für bestimmte Verwaltungsdomänen abgeleitet.
Das TeleManagement Forum (TMF) hat ein erweitertes Modell für die Telekommunikationsdomäne (das Shared Information / Data-Modell oder SID) als ein anderes definiert. Dies umfasst Ansichten aus den Geschäfts-, Service- und Ressourcendomänen der Telekommunikationsbranche. Das TMF hat eine Reihe von Grundsätzen festgelegt, die eine OSS-Integration übernehmen sollte, sowie eine Reihe von Modellen, die standardisierte Ansätze bieten.
Die Modelle interagieren mit dem Informationsmodell (Shared Information / Data Model oder SID) über ein Prozessmodell (Business Process Framework (eTOM) oder eTOM) und ein Lebenszyklusmodell.
Siehe auch[edit]
- ^ ein b c d e f Y. Tina Lee (1999). “Informationsmodellierung vom Entwurf bis zur Implementierung” Nationales Institut für Standards und Technologie.
- ^ Peter Chen (1976). “Das Entity-Relationship-Modell – Auf dem Weg zu einer einheitlichen Sicht auf Daten”. Im: ACM-Transaktionen auf DatenbanksystemenVol. 1, Nr. 1, März 1976.
- ^ Die Geschichte der konzeptuellen Modellierung bei uni-klu.ac.at.
- ^ D. Appleton Company, Inc. (1985). “Integriertes Informationsunterstützungssystem: Handbuch zur Informationsmodellierung, IDEF1 – Erweitert (IDEF1X)”. ICAM-Projektpriorität 6201, Unterauftrag Nr. 013-078846, USAF-Hauptvertrag Nr. F33615-80-C-5155, Luftwaffenstützpunkt Wright-Patterson, Ohio, Dezember 1985.
- ^ ISO 10303-11: 1994 (E), Industrielle Automatisierungssysteme und Integration – Darstellung und Austausch von Produktdaten – Teil 11: Das EXPRESS-Sprachreferenzhandbuch.
- ^ D. Schenck und P. Wilson (1994). Informationsmodellierung auf EXPRESS-Weise. Oxford University Press, New York, NY, 1994.
Verweise[edit]
Weiterführende Literatur[edit]
Externe Links[edit]
- RFC 3198 – Terminologie für richtlinienbasiertes Management
Recent Comments