Standardabweichung – Wikipedia
Maß für das Ausmaß der Variation oder Streuung eines Satzes von Werten

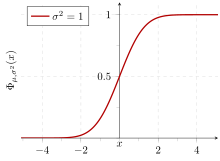
In der Statistik ist die Standardabweichung ist ein Maß für das Ausmaß der Variation oder Streuung eines Satzes von Werten.[1] Eine niedrige Standardabweichung zeigt an, dass die Werte tendenziell nahe am Mittelwert (auch als erwarteter Wert bezeichnet) des Satzes liegen, während eine hohe Standardabweichung anzeigt, dass die Werte über einen größeren Bereich verteilt sind.
Die Standardabweichung kann abgekürzt werden SDund wird am häufigsten in mathematischen Texten und Gleichungen durch den griechischen Kleinbuchstaben Sigma dargestellt σfür die Populationsstandardabweichung oder den lateinischen Buchstaben s für die Stichprobenstandardabweichung.[2]
(Für andere Verwendungen des Symbols σ in Naturwissenschaften und Mathematik siehe Sigma § Naturwissenschaften und Mathematik.)
Die Standardabweichung einer Zufallsvariablen, Stichprobe, statistischen Grundgesamtheit, eines Datensatzes oder einer Wahrscheinlichkeitsverteilung ist die Quadratwurzel ihrer Varianz. Es ist algebraisch einfacher, wenn auch in der Praxis weniger robust als die durchschnittliche absolute Abweichung.[3][4] Eine nützliche Eigenschaft der Standardabweichung ist, dass sie im Gegensatz zur Varianz in derselben Einheit wie die Daten ausgedrückt wird.
Die Standardabweichung einer Population oder Stichprobe und der Standardfehler einer Statistik (z. B. des Stichprobenmittelwerts) sind sehr unterschiedlich, hängen jedoch zusammen. Der Standardfehler des Stichprobenmittelwerts ist die Standardabweichung des Mittelwertsatzes, der durch Ziehen einer unendlichen Anzahl wiederholter Stichproben aus der Grundgesamtheit und Berechnen eines Mittelwerts für jede Stichprobe ermittelt werden würde. Der Standardfehler des Mittelwerts entspricht der Populationsstandardabweichung geteilt durch die Quadratwurzel der Stichprobengröße und wird unter Verwendung der Stichprobenstandardabweichung geteilt durch die Quadratwurzel der Stichprobengröße geschätzt. Beispielsweise ist der Standardfehler einer Umfrage (der als Fehlerquote der Umfrage angegeben wird) die erwartete Standardabweichung des geschätzten Mittelwerts, wenn dieselbe Umfrage mehrmals durchgeführt wird. Somit schätzt der Standardfehler die Standardabweichung einer Schätzung, die selbst misst, wie stark die Schätzung von der bestimmten Stichprobe abhängt, die aus der Grundgesamtheit entnommen wurde.
In der Wissenschaft ist es üblich, sowohl die Standardabweichung der Daten (als zusammenfassende Statistik) als auch den Standardfehler der Schätzung (als Maß für den potenziellen Fehler in den Ergebnissen) anzugeben. Konventionell werden nur Effekte berücksichtigt, die mehr als zwei Standardfehler von einer Nullerwartung entfernt sind “statistisch signifikant”, ein Schutz gegen falsche Schlussfolgerungen, die wirklich auf zufällige Stichprobenfehler zurückzuführen sind.
Wenn nur eine Stichprobe von Daten aus einer Population verfügbar ist, wird der Begriff verwendet Standardabweichung der Probe oder Standardabweichung der Probe kann sich entweder auf die oben genannte Menge beziehen, die auf diese Daten angewendet wird, oder auf eine modifizierte Menge, die eine unvoreingenommene Schätzung der ist Bevölkerungsstandardabweichung (die Standardabweichung der gesamten Bevölkerung).
Grundlegende Beispiele[edit]
Populationsstandardabweichung der Noten von acht Schülern[edit]
Angenommen, die gesamte interessierende Bevölkerung besteht aus acht Schülern in einer bestimmten Klasse. Für eine endliche Menge von Zahlen wird die Populationsstandardabweichung ermittelt, indem die Quadratwurzel des Durchschnitts der quadratischen Abweichungen der von ihrem Durchschnittswert subtrahierten Werte gezogen wird. Die Noten einer Klasse von acht Schülern (dh einer statistischen Grundgesamtheit) sind die folgenden acht Werte:

Diese acht Datenpunkte haben den Mittelwert (Durchschnitt) von 5:

Berechnen Sie zunächst die Abweichungen jedes Datenpunkts vom Mittelwert und quadrieren Sie das Ergebnis jedes:

Die Varianz ist der Mittelwert dieser Werte:

und die Population Die Standardabweichung entspricht der Quadratwurzel der Varianz:

Diese Formel ist nur gültig, wenn die acht Werte, mit denen wir begonnen haben, die gesamte Population bilden. Wenn die Werte stattdessen eine Zufallsstichprobe waren, die aus einer großen Elternpopulation gezogen wurde (zum Beispiel waren es 8 Schüler, die zufällig und unabhängig aus einer Klasse von 2 Millionen ausgewählt wurden), dann dividiert man durch 7 (was ist n – 1) Anstatt von 8 (was ist n) im Nenner der letzten Formel, und das Ergebnis ist
In diesem Fall würde das Ergebnis der ursprünglichen Formel als bezeichnet Stichprobe Standardabweichung und bezeichnet mit s Anstatt von
 In diesem Fall würde das Ergebnis der ursprünglichen Formel als bezeichnet Stichprobe Standardabweichung und bezeichnet mit s Anstatt von
In diesem Fall würde das Ergebnis der ursprünglichen Formel als bezeichnet Stichprobe Standardabweichung und bezeichnet mit s Anstatt von Teilen durch n – 1 statt von n gibt eine unvoreingenommene Schätzung der Varianz der größeren Elternpopulation. Dies ist bekannt als Bessels Korrektur.[5][6] Der Grund dafür ist ungefähr, dass die Formel für die Stichprobenvarianz auf der Berechnung der Unterschiede der Beobachtungen vom Stichprobenmittelwert beruht und der Stichprobenmittelwert selbst so konstruiert wurde, dass er den Beobachtungen so nahe wie möglich kommt, also nur durch dividiert n würde die Variabilität unterschätzen.
 Teilen durch n – 1 statt von n gibt eine unvoreingenommene Schätzung der Varianz der größeren Elternpopulation. Dies ist bekannt als Bessels Korrektur.[5][6] Der Grund dafür ist ungefähr, dass die Formel für die Stichprobenvarianz auf der Berechnung der Unterschiede der Beobachtungen vom Stichprobenmittelwert beruht und der Stichprobenmittelwert selbst so konstruiert wurde, dass er den Beobachtungen so nahe wie möglich kommt, also nur durch dividiert n würde die Variabilität unterschätzen.
Teilen durch n – 1 statt von n gibt eine unvoreingenommene Schätzung der Varianz der größeren Elternpopulation. Dies ist bekannt als Bessels Korrektur.[5][6] Der Grund dafür ist ungefähr, dass die Formel für die Stichprobenvarianz auf der Berechnung der Unterschiede der Beobachtungen vom Stichprobenmittelwert beruht und der Stichprobenmittelwert selbst so konstruiert wurde, dass er den Beobachtungen so nahe wie möglich kommt, also nur durch dividiert n würde die Variabilität unterschätzen.
Standardabweichung der Durchschnittsgröße für erwachsene Männer[edit]
Wenn die interessierende Population ungefähr normal verteilt ist, gibt die Standardabweichung Auskunft über den Anteil der Beobachtungen über oder unter bestimmten Werten. Beispielsweise beträgt die durchschnittliche Körpergröße für erwachsene Männer in den USA etwa 177,8 cm (70 Zoll) mit einer Standardabweichung von 7,62 cm (3 Zoll). Dies bedeutet, dass die meisten Männer (etwa 68%, unter der Annahme einer Normalverteilung) eine Körpergröße innerhalb von 7,62 cm (3 Zoll) des Mittelwerts (170,18–185,42 cm (67–73 Zoll)) haben – eine Standardabweichung – und fast alle Männer ( etwa 95%) haben eine Höhe innerhalb von 15,24 cm (6 Zoll) vom Mittelwert (162,56–193,04 cm (64–76 Zoll)) – zwei Standardabweichungen. Wenn die Standardabweichung Null wäre, wären alle Männer genau 177,8 cm groß. Wenn die Standardabweichung 50,8 cm (20 Zoll) betragen würde, hätten Männer viel variablere Höhen mit einem typischen Bereich von 127–228,6 cm (50–90 Zoll). Drei Standardabweichungen machen 99,7% der untersuchten Stichprobenpopulation aus, vorausgesetzt, die Verteilung ist normal oder glockenförmig (siehe die 68-95-99.7-Regel oder die empirische Regel, für mehr Informationen).
Definition von Bevölkerungswerten[edit]
Lassen X. eine Zufallsvariable mit Mittelwert sein μ::
![operatorname {E} [X]= mu. , !](https://wikimedia.org/api/rest_v1/media/math/render/svg/a850f6d56e315eaef8b630976d5164b368ecb072)
Hier bezeichnet der Operator E den Durchschnitts- oder Erwartungswert von X.. Dann ist die Standardabweichung von X. ist die Menge
![{ displaystyle { begin {align} sigma & = { sqrt { operatorname {E} left[(X-mu )^{2}right]}} \ & = { sqrt { operatorname {E} left[X^{2}right]+ operatorname {E} [-2mu X]+ operatorname {E} left[mu ^{2}right]}} \ & = { sqrt { operatorname {E} left[X^{2}right]-2 mu operatorname {E} [X]+ mu ^ {2}}} \ & = { sqrt { operatorname {E} left[X^{2}right]-2 mu ^ {2} + mu ^ {2}}} \ & = { sqrt { operatorname {E} left[X^{2}right]- mu ^ {2}}} \ & = { sqrt { operatorname {E} left[X^{2}right]- ( operatorname {E} [X]) ^ {2}}} end {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b2528934774f53f8c30b27ba52d6262052749385)
(abgeleitet unter Verwendung der Eigenschaften des erwarteten Wertes).
Mit anderen Worten, die Standardabweichung σ (Sigma) ist die Quadratwurzel der Varianz von X.;; dh es ist die Quadratwurzel des Durchschnittswerts von (X. – – μ)2.
Die Standardabweichung einer (univariaten) Wahrscheinlichkeitsverteilung ist dieselbe wie die einer Zufallsvariablen mit dieser Verteilung. Nicht alle Zufallsvariablen haben eine Standardabweichung, da diese erwarteten Werte nicht existieren müssen. Beispielsweise ist die Standardabweichung einer Zufallsvariablen, die einer Cauchy-Verteilung folgt, aufgrund ihres erwarteten Werts undefiniert μ ist nicht definiert.
Diskrete Zufallsvariable[edit]
In dem Fall wo X. nimmt zufällige Werte aus einem endlichen Datensatz x1, x2, …, xN.Bei jedem Wert mit der gleichen Wahrscheinlichkeit beträgt die Standardabweichung
![{ displaystyle sigma = { sqrt {{ frac {1} {N}} left[(x_{1}-mu )^{2}+(x_{2}-mu )^{2}+cdots +(x_{N}-mu )^{2}right]}}, { text {where}} mu = { frac {1} {N}} (x_ {1} + cdots + x_ {N}),}](https://wikimedia.org/api/rest_v1/media/math/render/svg/827beb1be760eed3cb07b20d29f01d326f728071)
oder unter Verwendung der Summationsnotation

Wenn die Werte anstelle gleicher Wahrscheinlichkeiten unterschiedliche Wahrscheinlichkeiten haben, lassen Sie x1 Wahrscheinlichkeit haben p1, x2 Wahrscheinlichkeit haben p2, …, xN. Wahrscheinlichkeit haben pN.. In diesem Fall beträgt die Standardabweichung

Kontinuierliche Zufallsvariable[edit]
Die Standardabweichung einer stetigen reellen Zufallsvariablen X. mit Wahrscheinlichkeitsdichtefunktion p(x) ist

und wo die Integrale bestimmte Integrale sind, für die man sich entscheidet x Bereich über den Satz möglicher Werte der Zufallsvariablen X..
Bei einer parametrischen Verteilungsfamilie kann die Standardabweichung in Form der Parameter ausgedrückt werden. Zum Beispiel bei der logarithmischen Normalverteilung mit Parametern μ und σ2ist die Standardabweichung

Einschätzung[edit]
Man kann die Standardabweichung einer gesamten Population in Fällen (wie standardisierten Tests) finden, in denen jedes Mitglied einer Population beprobt wird. In Fällen, in denen dies nicht möglich ist, die Standardabweichung σ wird geschätzt, indem eine Zufallsstichprobe aus der Population untersucht und eine Statistik der Stichprobe berechnet wird, die als Schätzung der Populationsstandardabweichung verwendet wird. Eine solche Statistik wird als Schätzer bezeichnet, und der Schätzer (oder der Wert des Schätzers, nämlich die Schätzung) wird als Stichprobenstandardabweichung bezeichnet und mit bezeichnet s (möglicherweise mit Modifikatoren).
Anders als bei der Schätzung des Populationsmittelwerts, für den der Stichprobenmittelwert ein einfacher Schätzer mit vielen wünschenswerten Eigenschaften (unverzerrt, effizient, maximale Wahrscheinlichkeit) ist, gibt es keinen einzigen Schätzer für die Standardabweichung mit all diesen Eigenschaften und eine unverzerrte Schätzung von Standardabweichung ist ein sehr technisch kompliziertes Problem. Am häufigsten wird die Standardabweichung mit dem geschätzt korrigierte Standardabweichung der Probe (mit N. – 1), nachstehend definiert, und dies wird oft als das bezeichnet “Standardabweichung der Probe”ohne Qualifikation. Andere Schätzer sind jedoch in anderer Hinsicht besser: der nicht korrigierte Schätzer (unter Verwendung von N.) ergibt bei Verwendung einen niedrigeren mittleren quadratischen Fehler N. – 1,5 (für die Normalverteilung) beseitigt die Vorspannung fast vollständig.
Nicht korrigierte Standardabweichung der Probe[edit]
Die Formel für die Population Die Standardabweichung (einer endlichen Population) kann auf die Stichprobe angewendet werden, wobei die Größe der Stichprobe als Größe der Population verwendet wird (obwohl die tatsächliche Populationsgröße, aus der die Stichprobe gezogen wird, viel größer sein kann). Dieser Schätzer bezeichnet mit sN.ist bekannt als die unkorrigierte Standardabweichung der Probeoder manchmal die Standardabweichung der Probe (als die gesamte Bevölkerung betrachtet) und ist wie folgt definiert:[7]

wo
sind die beobachteten Werte der Probengegenstände und
 sind die beobachteten Werte der Probengegenstände und
sind die beobachteten Werte der Probengegenstände und ist der Mittelwert dieser Beobachtungen, während der Nenner N. steht für die Größe der Stichprobe: Dies ist die Quadratwurzel der Stichprobenvarianz, die der Durchschnitt der quadratischen Abweichungen vom Stichprobenmittelwert ist.
 ist der Mittelwert dieser Beobachtungen, während der Nenner N. steht für die Größe der Stichprobe: Dies ist die Quadratwurzel der Stichprobenvarianz, die der Durchschnitt der quadratischen Abweichungen vom Stichprobenmittelwert ist.
ist der Mittelwert dieser Beobachtungen, während der Nenner N. steht für die Größe der Stichprobe: Dies ist die Quadratwurzel der Stichprobenvarianz, die der Durchschnitt der quadratischen Abweichungen vom Stichprobenmittelwert ist.
Dies ist ein konsistenter Schätzer (er konvergiert in der Wahrscheinlichkeit gegen den Populationswert, wenn die Anzahl der Stichproben gegen unendlich geht) und ist die Maximum-Likelihood-Schätzung, wenn die Population normal verteilt ist.[citation needed] Dies ist jedoch ein voreingenommener Schätzer, da die Schätzungen im Allgemeinen zu niedrig sind. Die Vorspannung nimmt mit zunehmender Stichprobengröße ab und fällt mit 1 / abN.und ist daher für kleine oder mittlere Stichprobengrößen am bedeutendsten; zum
Standardabweichung der Probe korrigiert[edit]

Wenn die voreingenommene Stichprobenvarianz (Das zweite zentrale Moment der Stichprobe, bei dem es sich um eine nach unten gerichtete Schätzung der Populationsvarianz handelt) wird verwendet, um eine Schätzung der Standardabweichung der Population zu berechnen. Das Ergebnis ist

Hier führt die Quadratwurzel durch Jensens Ungleichung zu einer weiteren Abwärtsverzerrung, da die Quadratwurzel eine konkave Funktion ist. Die Abweichung in der Varianz kann leicht korrigiert werden, aber die Abweichung von der Quadratwurzel ist schwieriger zu korrigieren und hängt von der fraglichen Verteilung ab.
Ein unvoreingenommener Schätzer für die Varianz wird durch Anwenden der Besselschen Korrektur unter Verwendung von gegeben N. – 1 statt N. zu ergeben unvoreingenommene Stichprobenvarianz, bezeichnet s2::

Dieser Schätzer ist unverzerrt, wenn die Varianz vorliegt und die Stichprobenwerte bei Ersetzung unabhängig voneinander gezogen werden. N. – 1 entspricht der Anzahl der Freiheitsgrade im Vektor der Abweichungen vom Mittelwert,

Das Nehmen von Quadratwurzeln führt zu einer erneuten Verzerrung (da die Quadratwurzel eine nichtlineare Funktion ist, die nicht mit der Erwartung pendelt) und ergibt die korrigierte Standardabweichung der Probe, bezeichnet durch s:[2]

Wie oben erklärt, während s2 ist ein unvoreingenommener Schätzer für die Populationsvarianz, s ist immer noch ein voreingenommener Schätzer für die Populationsstandardabweichung, obwohl er deutlich weniger voreingenommen ist als die nicht korrigierte Standardabweichung der Stichprobe. Dieser Schätzer wird allgemein verwendet und ist allgemein einfach als der bekannt “Standardabweichung der Probe”. Die Vorspannung kann für kleine Abtastwerte immer noch groß sein (N. weniger als 10). Mit zunehmender Probengröße nimmt die Vorspannung ab. Wir erhalten mehr Informationen und den Unterschied zwischen
und
 und
und wird kleiner.
 wird kleiner.
wird kleiner.
Unvoreingenommene Standardabweichung der Probe[edit]
Für die unverzerrte Schätzung der Standardabweichung gibt es keine Formel, die über alle Verteilungen hinweg funktioniert, im Gegensatz zu Mittelwert und Varianz. Stattdessen, s wird als Basis verwendet und durch einen Korrekturfaktor skaliert, um eine unverzerrte Schätzung zu erzeugen. Für die Normalverteilung ist ein unverzerrter Schätzer gegeben durch s/.c4, wo der Korrekturfaktor (der abhängt von N.) wird in Bezug auf die Gammafunktion angegeben und ist gleich:

Dies liegt daran, dass die Stichprobenverteilung der Stichprobenstandardabweichung einer (skalierten) Chi-Verteilung folgt und der Korrekturfaktor der Mittelwert der Chi-Verteilung ist.
Eine Annäherung kann durch Ersetzen gegeben werden N. – 1 mit N. – 1,5, ergibt:

Der Fehler in dieser Näherung nimmt quadratisch ab (als 1 /N.2), und es ist für alle außer den kleinsten Proben oder der höchsten Präzision geeignet: z N. = 3 die Vorspannung ist gleich 1,3% und für N. = 9 die Vorspannung beträgt bereits weniger als 0,1%.
Eine genauere Annäherung ist zu ersetzen
oben mit
 oben mit
oben mit .[8]
 .[8]
.[8]Bei anderen Verteilungen hängt die richtige Formel von der Verteilung ab. Als Faustregel gilt jedoch die weitere Verfeinerung der Näherung:

wo γ2 bezeichnet die Bevölkerungsüberschuss-Kurtosis. Die überschüssige Kurtosis kann entweder für bestimmte Verteilungen im Voraus bekannt sein oder aus den Daten geschätzt werden.[citation needed]
Konfidenzintervall einer abgetasteten Standardabweichung[edit]
Die Standardabweichung, die wir durch Abtasten einer Verteilung erhalten, ist selbst nicht absolut genau, sowohl aus mathematischen Gründen (hier erklärt durch das Konfidenzintervall) als auch aus praktischen Gründen der Messung (Messfehler). Der mathematische Effekt kann durch das Konfidenzintervall oder CI beschrieben werden.
Betrachten Sie die folgenden Beispiele, um zu zeigen, wie eine größere Stichprobe das Konfidenzintervall enger macht: Eine kleine Population von N. = 2 hat nur 1 Freiheitsgrad zum Schätzen der Standardabweichung. Das Ergebnis ist, dass ein 95% CI der SD von 0,45 × SD bis 31,9 × SD läuft; Die Faktoren hier sind wie folgt:

wo
ist der p-th Quantil der Chi-Quadrat-Verteilung mit k Freiheitsgrade und
 ist der p-th Quantil der Chi-Quadrat-Verteilung mit k Freiheitsgrade und
ist der p-th Quantil der Chi-Quadrat-Verteilung mit k Freiheitsgrade und ist das Konfidenzniveau. Dies entspricht dem Folgenden:
 ist das Konfidenzniveau. Dies entspricht dem Folgenden:
ist das Konfidenzniveau. Dies entspricht dem Folgenden:

Mit k = 1,
und
 und
und . Die Kehrwerte der Quadratwurzeln dieser beiden Zahlen geben uns die oben angegebenen Faktoren 0,45 und 31,9.
 . Die Kehrwerte der Quadratwurzeln dieser beiden Zahlen geben uns die oben angegebenen Faktoren 0,45 und 31,9.
. Die Kehrwerte der Quadratwurzeln dieser beiden Zahlen geben uns die oben angegebenen Faktoren 0,45 und 31,9.
Eine größere Bevölkerung von N. = 10 hat 9 Freiheitsgrade zum Schätzen der Standardabweichung. Die gleichen Berechnungen wie oben ergeben in diesem Fall einen 95% CI von 0,69 × SD bis 1,83 × SD. Selbst bei einer Stichprobenpopulation von 10 kann die tatsächliche SD um fast den Faktor 2 höher sein als die abgetastete SD. Für eine Stichprobenpopulation N = 100 beträgt dies 0,88 × SD bis 1,16 × SD. Um sicherer zu sein, dass die abgetastete SD nahe an der tatsächlichen SD liegt, müssen wir eine große Anzahl von Punkten abtasten.
Dieselben Formeln können verwendet werden, um Konfidenzintervalle für die Varianz von Residuen aus kleinsten Quadraten zu erhalten, die unter die normale Standardtheorie passen, wobei k ist jetzt die Anzahl der Freiheitsgrade für Fehler.
Grenzen der Standardabweichung[edit]
Für eine Reihe von N. > 4 Daten über einen Wertebereich R.eine Obergrenze für die Standardabweichung s ist gegeben durch s = 0,6R.[9]
Eine Schätzung der Standardabweichung für N. > 100 Daten, die als annähernd normal angesehen werden, ergeben sich aus der Heuristik, dass 95% der Fläche unter der Normalkurve ungefähr zwei Standardabweichungen zu beiden Seiten des Mittelwerts liegen, so dass mit einer Wahrscheinlichkeit von 95% der gesamte Wertebereich liegt R. stellt vier Standardabweichungen dar, so dass s ≈ R / 4. Diese sogenannte Bereichsregel ist bei der Schätzung der Stichprobengröße nützlich, da der Bereich möglicher Werte leichter zu schätzen ist als die Standardabweichung. Andere Teiler K (N) des Bereichs so, dass s ≤ R / K (N) sind für andere Werte von verfügbar N. und für nicht normale Verteilungen.[10]
Identitäten und mathematische Eigenschaften[edit]
Die Standardabweichung ist bei Ortsänderungen unveränderlich und skaliert direkt mit der Skala der Zufallsvariablen. Also für eine Konstante c und Zufallsvariablen X. und Y.::

Die Standardabweichung der Summe zweier Zufallsvariablen kann mit ihren individuellen Standardabweichungen und der Kovarianz zwischen ihnen in Beziehung gesetzt werden:

wo
und
 und
und stehen für Varianz bzw. Kovarianz.
 stehen für Varianz bzw. Kovarianz.
stehen für Varianz bzw. Kovarianz.
Die Berechnung der Summe der quadratischen Abweichungen kann sich auf Momente beziehen, die direkt aus den Daten berechnet werden. In der folgenden Formel wird der Buchstabe E als Mittelwert des erwarteten Wertes interpretiert, dh als Mittelwert.
![{ displaystyle sigma (X) = { sqrt { operatorname {E} left[(X-operatorname {E} [X]) ^ {2} right]}} = { sqrt { operatorname {E} left[X^{2}right]- ( operatorname {E} [X]) ^ {2}}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d3ab12089bd2027790ef060ff7cc2ec05ae2021f)
Die Standardabweichung der Stichprobe kann wie folgt berechnet werden:
![{ displaystyle s (X) = { sqrt { frac {N} {N-1}}} { sqrt { operatorname {E} left[(X-operatorname {E} [X]) ^ {2} right]}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/702e9da21c721697e6e81932bf8b7443028f7d6d)
Für eine endliche Population mit gleichen Wahrscheinlichkeiten an allen Punkten haben wir

Dies bedeutet, dass die Standardabweichung gleich der Quadratwurzel der Differenz zwischen dem Durchschnitt der Quadrate der Werte und dem Quadrat des Durchschnittswerts ist.
Siehe Berechnungsformel für die Varianz zum Beweis und für ein analoges Ergebnis für die Standardabweichung der Stichprobe.
Interpretation und Anwendung[edit]

Eine große Standardabweichung zeigt an, dass sich die Datenpunkte weit vom Mittelwert ausbreiten können, und eine kleine Standardabweichung zeigt an, dass sie eng um den Mittelwert gruppiert sind.
Beispielsweise hat jede der drei Populationen {0, 0, 14, 14}, {0, 6, 8, 14} und {6, 6, 8, 8} einen Mittelwert von 7. Ihre Standardabweichungen betragen 7, 5 bzw. 1. Die dritte Population hat eine viel kleinere Standardabweichung als die beiden anderen, da ihre Werte alle nahe bei 7 liegen. Diese Standardabweichungen haben die gleichen Einheiten wie die Datenpunkte selbst. Wenn beispielsweise der Datensatz {0, 6, 8, 14} das Alter einer Population von vier Geschwistern in Jahren darstellt, beträgt die Standardabweichung 5 Jahre. Als weiteres Beispiel kann die Bevölkerung {1000, 1006, 1008, 1014} die von vier Athleten zurückgelegten Strecken in Metern darstellen. Es hat einen Mittelwert von 1007 Metern und eine Standardabweichung von 5 Metern.
Die Standardabweichung kann als Maß für die Unsicherheit dienen. In der Physik gibt beispielsweise die angegebene Standardabweichung einer Gruppe wiederholter Messungen die Genauigkeit dieser Messungen an. Bei der Entscheidung, ob Messungen mit einer theoretischen Vorhersage übereinstimmen, ist die Standardabweichung dieser Messungen von entscheidender Bedeutung: Wenn der Mittelwert der Messungen zu weit von der Vorhersage entfernt ist (wobei der Abstand in Standardabweichungen gemessen wird), wird die Theorie wahrscheinlich getestet muss überarbeitet werden. Dies ist sinnvoll, da sie außerhalb des Wertebereichs liegen, der vernünftigerweise zu erwarten wäre, wenn die Vorhersage korrekt wäre und die Standardabweichung angemessen quantifiziert würde. Siehe Vorhersageintervall.
Während die Standardabweichung misst, wie weit typische Werte tendenziell vom Mittelwert abweichen, stehen andere Messgrößen zur Verfügung. Ein Beispiel ist die mittlere absolute Abweichung, die als direkteres Maß für die durchschnittliche Entfernung angesehen werden kann, verglichen mit der mittleren quadratischen Entfernung, die der Standardabweichung inhärent ist.
Anwendungsbeispiele[edit]
Der praktische Wert für das Verständnis der Standardabweichung einer Reihe von Werten besteht darin, zu erkennen, wie stark die Abweichung vom Durchschnitt (Mittelwert) vorliegt.
Experimentelle, industrielle und Hypothesentests[edit]
Die Standardabweichung wird häufig verwendet, um reale Daten mit einem Modell zu vergleichen und das Modell zu testen. Beispielsweise muss in industriellen Anwendungen das Gewicht von Produkten, die von einer Produktionslinie kommen, möglicherweise einem gesetzlich vorgeschriebenen Wert entsprechen. Durch das Wiegen eines Teils der Produkte kann ein Durchschnittsgewicht ermittelt werden, das sich immer geringfügig vom langfristigen Durchschnitt unterscheidet. Unter Verwendung von Standardabweichungen kann ein Minimal- und Maximalwert berechnet werden, bei dem das gemittelte Gewicht innerhalb eines sehr hohen Prozentsatzes der Zeit liegt (99,9% oder mehr). Wenn es außerhalb des Bereichs liegt, muss der Produktionsprozess möglicherweise korrigiert werden. Statistische Tests wie diese sind besonders wichtig, wenn die Tests relativ teuer sind. Zum Beispiel, wenn das Produkt geöffnet und abgelassen und gewogen werden muss oder wenn das Produkt durch den Test anderweitig verbraucht wurde.
In der experimentellen Wissenschaft wird ein theoretisches Realitätsmodell verwendet. Die Teilchenphysik verwendet üblicherweise einen Standard von “5 Sigma” für die Erklärung einer Entdeckung.[11] Ein Fünf-Sigma-Level bedeutet eine Chance von 3,5 Millionen, dass eine zufällige Fluktuation das Ergebnis liefert. Dieses Maß an Sicherheit war erforderlich, um zu behaupten, dass in zwei unabhängigen Experimenten am CERN ein mit dem Higgs-Boson übereinstimmendes Teilchen entdeckt worden war.[12] und dies war auch das Signifikanzniveau, das zur Erklärung der ersten Beobachtung von Gravitationswellen führte.[13]
Wetter[edit]
Betrachten Sie als einfaches Beispiel die durchschnittlichen täglichen Höchsttemperaturen für zwei Städte, eine im Landesinneren und eine an der Küste. Es ist hilfreich zu verstehen, dass der Bereich der täglichen Höchsttemperaturen für küstennahe Städte kleiner ist als für Städte im Landesinneren. Während diese beiden Städte jeweils die gleiche durchschnittliche Maximaltemperatur haben können, ist die Standardabweichung der täglichen Maximaltemperatur für die Küstenstadt geringer als die der Binnenstadt, da an einem bestimmten Tag die tatsächliche Maximaltemperatur wahrscheinlicher ist weiter von der durchschnittlichen Höchsttemperatur für die Binnenstadt entfernt zu sein als für die Küstenstadt.
Finanzen[edit]
In der Finanzbranche wird die Standardabweichung häufig als Maß für das Risiko verwendet, das mit Preisschwankungen eines bestimmten Vermögenswerts (Aktien, Anleihen, Immobilien usw.) oder für das Risiko eines Vermögensportfolios verbunden ist[14] (aktiv verwaltete Investmentfonds, Index-Investmentfonds oder ETFs). Das Risiko ist ein wichtiger Faktor für die effiziente Verwaltung eines Anlageportfolios, da es die Variation der Renditen des Vermögenswerts und / oder des Portfolios bestimmt und den Anlegern eine mathematische Grundlage für Anlageentscheidungen bietet (sogenannte Mittelwertvarianzoptimierung). Das grundlegende Risikokonzept besteht darin, dass mit zunehmendem Risiko auch die erwartete Rendite einer Anlage steigen sollte, eine Erhöhung, die als Risikoprämie bezeichnet wird. Mit anderen Worten, Anleger sollten eine höhere Rendite einer Anlage erwarten, wenn diese Anlage ein höheres Risiko oder eine höhere Unsicherheit birgt. Bei der Bewertung von Anlagen sollten Anleger sowohl die erwartete Rendite als auch die Unsicherheit zukünftiger Renditen schätzen. Die Standardabweichung liefert eine quantifizierte Schätzung der Unsicherheit zukünftiger Renditen.
Angenommen, ein Anleger musste zwischen zwei Aktien wählen. Aktie A hatte in den letzten 20 Jahren eine durchschnittliche Rendite von 10 Prozent mit einer Standardabweichung von 20 Prozentpunkten (pp) und Aktie B hatte im gleichen Zeitraum eine durchschnittliche Rendite von 12 Prozent, aber eine höhere Standardabweichung von 30 pp. Auf der Grundlage von Risiko und Rendite kann ein Anleger entscheiden, dass Aktie A die sicherere Wahl ist, da die zusätzlichen zwei Prozentpunkte der Rendite von Aktie B die zusätzliche Standardabweichung von 10 pp (größeres Risiko oder Unsicherheit der erwarteten Rendite) nicht wert sind. Aktie B wird unter den gleichen Umständen wahrscheinlich häufiger hinter der ursprünglichen Investition zurückbleiben (aber auch die ursprüngliche Investition übersteigen) als Aktie A, und es wird geschätzt, dass sie im Durchschnitt nur zwei Prozent mehr zurückbringt. In diesem Beispiel wird erwartet, dass Aktie A ungefähr 10 Prozent plus oder minus 20 Prozentpunkte (ein Bereich von 30 Prozent bis –10 Prozent) verdient, was ungefähr zwei Dritteln der Rendite des zukünftigen Jahres entspricht. Wenn ein Anleger in Zukunft extremere mögliche Renditen oder Ergebnisse in Betracht zieht, sollte er Ergebnisse von bis zu 10 Prozent plus oder minus 60 Prozent oder einen Bereich von 70 Prozent bis -50 Prozent erwarten, der Ergebnisse für drei Standardabweichungen von der durchschnittlichen Rendite enthält (ungefähr 99,7 Prozent der wahrscheinlichen Renditen).
Die Berechnung des Durchschnitts (oder des arithmetischen Mittelwerts) der Rendite eines Wertpapiers über einen bestimmten Zeitraum ergibt die erwartete Rendite des Vermögenswerts. Wenn für jede Periode die erwartete Rendite von der tatsächlichen Rendite abgezogen wird, ergibt sich die Differenz zum Mittelwert. Durch Quadrieren der Differenz in jeder Periode und Berechnen des Durchschnitts ergibt sich die Gesamtvarianz der Rendite des Vermögenswerts. Je größer die Varianz ist, desto größer ist das Risiko für die Sicherheit. Wenn Sie die Quadratwurzel dieser Varianz ermitteln, erhalten Sie die Standardabweichung des betreffenden Anlageinstrumentes.
Die Populationsstandardabweichung wird verwendet, um die Breite von Bollinger-Bändern festzulegen, einem weit verbreiteten technischen Analysewerkzeug. Zum Beispiel wird das obere Bollinger-Band als angegeben
Der am häufigsten verwendete Wert für n ist 2; Bei einer normalen Verteilung der Renditen besteht eine Wahrscheinlichkeit von etwa fünf Prozent, nach draußen zu gehen.
 Der am häufigsten verwendete Wert für n ist 2; Bei einer normalen Verteilung der Renditen besteht eine Wahrscheinlichkeit von etwa fünf Prozent, nach draußen zu gehen.
Der am häufigsten verwendete Wert für n ist 2; Bei einer normalen Verteilung der Renditen besteht eine Wahrscheinlichkeit von etwa fünf Prozent, nach draußen zu gehen.
Finanzielle Zeitreihen sind als instationäre Reihen bekannt, während die obigen statistischen Berechnungen, wie z. B. die Standardabweichung, nur für stationäre Reihen gelten. Um die oben genannten statistischen Werkzeuge auf instationäre Reihen anzuwenden, muss die Reihe zunächst in eine stationäre Reihe umgewandelt werden, damit statistische Werkzeuge verwendet werden können, die nun eine gültige Grundlage für die Arbeit haben.
Geometrische Interpretation[edit]
Um einige geometrische Einsichten und Erläuterungen zu erhalten, beginnen wir mit einer Grundgesamtheit von drei Werten: x1, x2, x3. Dies definiert einen Punkt P. = (x1, x2, x3) im R.3. Betrachten Sie die Linie L. = {(r, r, r): r ∈ R.}. Dies ist das “Hauptdiagonale” durch den Ursprung gehen. Wenn unsere drei angegebenen Werte alle gleich wären, wäre die Standardabweichung Null und P. würde auf liegen L.. Es ist also nicht unangemessen anzunehmen, dass die Standardabweichung mit dem zusammenhängt Entfernung von P. zu L.. Das ist in der Tat der Fall. Orthogonal bewegen von L. auf den Punkt P.beginnt man an dem Punkt:

deren Koordinaten sind der Mittelwert der Werte, mit denen wir begonnen haben.
|
Ableitung von
|
|---|
|
ist an deshalb für einige . Die Linie ist orthogonal zum Vektor von zu . Deshalb: |
 ist an
ist an  deshalb
deshalb  für einige
für einige  .
.
 . Deshalb:
. Deshalb:
 cdot (x_ {1} - Ell, x_ {2} - Ell, x_ {3} - Ell) & = 0 \[4pt]r (x_ {1} - ell + x_ {2} - ell + x_ {3} - ell) & = 0 \[4pt]r left ( sum _ {i} x_ {i} -3 ell right) & = 0 \[4pt] sum _ {i} x_ {i} -3 ell & = 0 \[4pt]{ frac {1} {3}} sum _ {i} x_ {i} & = ell \[4pt]{ bar {x}} & = ell end {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/51526a39caa45834866ae2dc4bb3ed262ba7fbe0)
Eine kleine Algebra zeigt, dass der Abstand zwischen P. und M. (Dies entspricht dem orthogonalen Abstand zwischen P. und die Linie L.)
ist gleich der Standardabweichung des Vektors (x1, x2, x3), multipliziert mit der Quadratwurzel der Anzahl der Dimensionen des Vektors (in diesem Fall 3).
 ist gleich der Standardabweichung des Vektors (x1, x2, x3), multipliziert mit der Quadratwurzel der Anzahl der Dimensionen des Vektors (in diesem Fall 3).
ist gleich der Standardabweichung des Vektors (x1, x2, x3), multipliziert mit der Quadratwurzel der Anzahl der Dimensionen des Vektors (in diesem Fall 3).
Chebyshevs Ungleichung[edit]
Eine Beobachtung ist selten mehr als ein paar Standardabweichungen vom Mittelwert entfernt. Die Ungleichung von Chebyshev stellt sicher, dass für alle Verteilungen, für die die Standardabweichung definiert ist, die Datenmenge innerhalb einer Reihe von Standardabweichungen des Mittelwerts mindestens so groß ist wie in der folgenden Tabelle angegeben.
Regeln für normalverteilte Daten[edit]
Der zentrale Grenzwertsatz besagt, dass die Verteilung eines Durchschnitts vieler unabhängiger, identisch verteilter Zufallsvariablen zur berühmten glockenförmigen Normalverteilung mit einer Wahrscheinlichkeitsdichtefunktion von tendiert

wo μ ist der erwartete Wert der Zufallsvariablen, σ entspricht der Standardabweichung ihrer Verteilung geteilt durch n1/2, und n ist die Anzahl der Zufallsvariablen. Die Standardabweichung ist daher einfach eine Skalierungsvariable, die anpasst, wie breit die Kurve sein wird, obwohl sie auch in der Normalisierungskonstante erscheint.
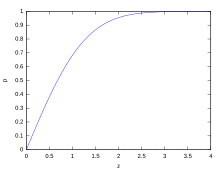
Wenn eine Datenverteilung ungefähr normal ist, ist der Anteil der Datenwerte innerhalb z Standardabweichungen des Mittelwerts sind definiert durch:

wo
ist die Fehlerfunktion. Der Anteil, der kleiner oder gleich einer Zahl ist, x, ist gegeben durch die kumulative Verteilungsfunktion:
 ist die Fehlerfunktion. Der Anteil, der kleiner oder gleich einer Zahl ist, x, ist gegeben durch die kumulative Verteilungsfunktion:
ist die Fehlerfunktion. Der Anteil, der kleiner oder gleich einer Zahl ist, x, ist gegeben durch die kumulative Verteilungsfunktion:
- .[16]
![{ displaystyle { text {Proportion}} leq x = { frac {1} {2}} left[1+operatorname {erf} left({frac {x-mu }{sigma {sqrt {2}}}}right)right]= { frac {1} {2}} left[1+operatorname {erf} left({frac {z}{sqrt {2}}}right)right]}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3907d1b0502235fa3fd00f261b290406a02e7b21)
Wenn eine Datenverteilung ungefähr normal ist, liegen ungefähr 68 Prozent der Datenwerte innerhalb einer Standardabweichung vom Mittelwert (mathematisch, μ ± σ, wo μ ist das arithmetische Mittel), etwa 95 Prozent liegen innerhalb von zwei Standardabweichungen (μ ± 2σ) und etwa 99,7 Prozent liegen innerhalb von drei Standardabweichungen (μ ± 3σ). Dies ist als die bekannt 68-95-99.7 Regel, oder die empirische Regel.
Für verschiedene Werte von z, der Prozentsatz der Werte, von denen erwartet wird, dass sie innerhalb und außerhalb des symmetrischen Intervalls liegen, CI = (-zσ, zσ), sind wie folgt:
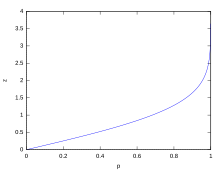
| Vertrauen Intervall |
Anteil innerhalb | Anteil ohne | |
|---|---|---|---|
| Prozentsatz | Prozentsatz | Fraktion | |
| 0,318639σ | 25% | 75% | 3/4 |
| 0,674490σ | 50%. | 50%. | 1 / 2 |
| 0,977925σ | 66.6%. | 33.3%. | 1/3 |
| 0,994458σ | 68% | 32% | 1 / 3.125 |
| 1σ | 68,2689492%. | 31.7310508%. | 1 / 3.1514872 |
| 1,281552σ | 80% | 20% | 15 |
| 1,644854σ | 90% | 10% | 1/10 |
| 1,959964σ | 95% | 5% | 1/20 |
| 2σ | 95,4499736%. | 4,5500264%. | 1 / 21.977895 |
| 2,575829σ | 99% | 1% | 1/100 |
| 3σ | 99,7300204%. | 0,2699796%. | 1 / 370.398 |
| 3,290527σ | 99,9% | 0,1% | 1 / 1000 |
| 3,890592σ | 99,99% | 0,01% | 1 / 10000 |
| 4σ | 99,993666%. | 0,006334%. | 1 / 15787 |
| 4.417173σ | 99,999% | 0,001% | 1 / 100000 |
| 4.5σ | 99,9993204653751% | 0,0006795346249% | 1 / 147159.5358 6.8 / 1000000 |
| 4.891638σ | 99,9999%. | 0,0001%. | 1 / 1000000 |
| 5σ | 99,9999426697%. | 0,0000573303%. | 1 / 1744278 |
| 5.326724σ | 99,99999%. | 0,00001%. | 1 / 10000000 |
| 5.730729σ | 99,999999%. | 0,000001%. | 1 / 100000000 |
| 6σ | 99,9999998027%. | 0,0000001973%. | 1 / 506797346 |
| 6.109410σ | 99,9999999%. | 0,0000001%. | 1 / 1000000000 |
| 6.466951σ | 99,99999999%. | 0,00000001%. | 1 / 10000000000 |
| 6.806502σ | 99,999999999%. | 0,000000001%. | 1 / 100000000000 |
| 7σ | 99,9999999997440% | 0,000000000256%. | 1 / 390682215445 |
Beziehung zwischen Standardabweichung und Mittelwert[edit]
Der Mittelwert und die Standardabweichung eines Datensatzes sind beschreibende Statistiken, die normalerweise zusammen angegeben werden. In gewissem Sinne ist die Standardabweichung a “natürlich” Maß für die statistische Streuung, wenn das Zentrum der Daten um den Mittelwert gemessen wird. Dies liegt daran, dass die Standardabweichung vom Mittelwert kleiner ist als von jedem anderen Punkt. Die genaue Aussage lautet wie folgt: Angenommen x1, …, xn sind reelle Zahlen und definieren die Funktion:

Mit Hilfe von Kalkül oder durch Ausfüllen des Quadrats kann dies gezeigt werden σ(r) hat im Mittel ein eindeutiges Minimum:

Die Variabilität kann auch anhand des Variationskoeffizienten gemessen werden, der das Verhältnis der Standardabweichung zum Mittelwert darstellt. Es ist eine dimensionslose Zahl.
Standardabweichung des Mittelwerts[edit]
Oft möchten wir einige Informationen über die Genauigkeit des Mittelwerts, den wir erhalten haben. Wir können dies erhalten, indem wir die Standardabweichung des Stichprobenmittelwerts bestimmen. Unter der Annahme einer statistischen Unabhängigkeit der Werte in der Stichprobe wird die Standardabweichung des Mittelwerts mit der Standardabweichung der Verteilung in Beziehung gesetzt durch:

wo N. ist die Anzahl der Beobachtungen in der Stichprobe, die zur Schätzung des Mittelwerts verwendet wurden. Dies kann leicht nachgewiesen werden mit (siehe grundlegende Eigenschaften der Varianz):

(Statistische Unabhängigkeit wird vorausgesetzt.)

daher

Ergebend:

Um die Standardabweichung des Mittelwerts abzuschätzen
Es ist notwendig, die Standardabweichung der gesamten Bevölkerung zu kennen
 Es ist notwendig, die Standardabweichung der gesamten Bevölkerung zu kennen
Es ist notwendig, die Standardabweichung der gesamten Bevölkerung zu kennen vorweg. In den meisten Anwendungen ist dieser Parameter jedoch unbekannt. Wenn beispielsweise eine Reihe von 10 Messungen einer zuvor unbekannten Größe in einem Labor durchgeführt wird, ist es möglich, den resultierenden Probenmittelwert und die Probenstandardabweichung zu berechnen, es ist jedoch unmöglich, die Standardabweichung des Mittelwerts zu berechnen.
 vorweg. In den meisten Anwendungen ist dieser Parameter jedoch unbekannt. Wenn beispielsweise eine Reihe von 10 Messungen einer zuvor unbekannten Größe in einem Labor durchgeführt wird, ist es möglich, den resultierenden Probenmittelwert und die Probenstandardabweichung zu berechnen, es ist jedoch unmöglich, die Standardabweichung des Mittelwerts zu berechnen.
vorweg. In den meisten Anwendungen ist dieser Parameter jedoch unbekannt. Wenn beispielsweise eine Reihe von 10 Messungen einer zuvor unbekannten Größe in einem Labor durchgeführt wird, ist es möglich, den resultierenden Probenmittelwert und die Probenstandardabweichung zu berechnen, es ist jedoch unmöglich, die Standardabweichung des Mittelwerts zu berechnen.
Schnelle Berechnungsmethoden[edit]
Die folgenden zwei Formeln können eine laufende (wiederholt aktualisierte) Standardabweichung darstellen. Ein Satz von zwei Leistungssummen s1 und s2 werden über eine Menge von berechnet N. Werte von x, bezeichnet als x1, …, xN.::

Angesichts der Ergebnisse dieser laufenden Summierungen sind die Werte N., s1, s2 kann jederzeit zur Berechnung der verwendet werden aktuell Wert der laufenden Standardabweichung:

Wobei N, wie oben erwähnt, die Größe des Wertesatzes ist (oder auch als betrachtet werden kann s0).
Ähnliches gilt für die Standardabweichung der Stichprobe.

In einer Computerimplementierung wie die drei sj Wenn die Summen groß werden, müssen wir Rundungsfehler, arithmetischen Überlauf und arithmetischen Unterlauf berücksichtigen. Die folgende Methode berechnet die Laufsummenmethode mit reduzierten Rundungsfehlern.[17] Das ist ein “einem Durchgang” Algorithmus zur Berechnung der Varianz von n Proben, ohne dass vorherige Daten während der Berechnung gespeichert werden müssen. Die Anwendung dieser Methode auf eine Zeitreihe führt zu aufeinanderfolgenden Werten der Standardabweichung entsprechend n Datenpunkte als n wird mit jeder neuen Stichprobe größer als eine Schiebefensterberechnung mit konstanter Breite.
Zum k = 1, …, n::

wobei A der Mittelwert ist.

Hinweis:
schon seit
 schon seit
schon seit oder
 oder
oder

Stichprobenvarianz:

Populationsvarianz:

Gewichtete Berechnung[edit]
Wenn die Werte xich werden mit ungleichen Gewichten gewichtet wich, die Macht summiert sich s0, s1, s2 werden jeweils berechnet als:

Und die Standardabweichungsgleichungen bleiben unverändert. s0 ist jetzt die Summe der Gewichte und nicht die Anzahl der Proben N..
Das inkrementelle Verfahren mit reduzierten Rundungsfehlern kann mit zusätzlicher Komplexität ebenfalls angewendet werden.
Für jedes muss eine laufende Summe von Gewichten berechnet werden k von 1 bis n::

und Orte, an denen 1 /n wird oben verwendet muss ersetzt werden durch wich/.W.n::

In der letzten Division

und

oder

wo n ist die Gesamtzahl der Elemente und n ‘ ist die Anzahl der Elemente mit einer Gewichtung ungleich Null.
Die obigen Formeln werden gleich den oben angegebenen einfacheren Formeln, wenn die Gewichte gleich eins genommen werden.
Geschichte[edit]
Der Begriff Standardabweichung wurde erstmals 1894 von Karl Pearson schriftlich verwendet, nachdem er es in Vorlesungen verwendet hatte.[18][19] Dies war ein Ersatz für frühere alternative Namen für dieselbe Idee: zum Beispiel Gauß mittlerer Fehler.[20]
Höhere Abmessungen[edit]
In zwei Dimensionen kann die Standardabweichung mit der Standardabweichungsellipse dargestellt werden, siehe Multivariate Normalverteilung § Geometrische Interpretation.
Siehe auch[edit]
Verweise[edit]
- ^ Bland, JM; Altman, DG (1996). “Statistikhinweise: Messfehler”. BMJ. 312 (7047): 1654. doi:10.1136 / bmj.312.7047.1654. PMC 2351401. PMID 8664723.
- ^ ein b “Liste der Wahrscheinlichkeits- und Statistiksymbole”. Math Vault. 26. April 2020. Abgerufen 21. August 2020.
- ^ Gauß, Carl Friedrich (1816). “Bestimmung der Aussagen der Beobachtungen”. Zeitschrift für Astronomie und Verwandte Wissenschaften. 1: 187–197.
- ^ Walker, Helen (1931). Studien zur Geschichte der statistischen Methode. Baltimore, MD: Williams & Wilkins Co., S. 24–25.
- ^ Weisstein, Eric W. “Bessels Korrektur”. MathWorld.
- ^ “Standardabweichungsformeln”. www.mathsisfun.com. Abgerufen 21. August 2020.
- ^ Weisstein, Eric W. “Standardabweichung”. mathworld.wolfram.com. Abgerufen 21. August 2020.
- ^ Gurland, John; Tripathi, Ram C. (1971), “Eine einfache Näherung für die unvoreingenommene Schätzung der Standardabweichung”, Der amerikanische Statistiker, 25 (4): 30–32, doi:10.2307 / 2682923, JSTOR 2682923
- ^ Shiffler, Ronald E.; Harsha, Phillip D. (1980). “Ober- und Untergrenze für die Standardabweichung der Stichprobe”. Statistik lehren. 2 (3): 84–86. doi:10.1111 / j.1467-9639.1980.tb00398.x.
- ^ Browne, Richard H. (2001). “Verwenden des Probenbereichs als Grundlage für die Berechnung der Probengröße in Leistungsberechnungen”. Der amerikanische Statistiker. 55 (4): 293–298. doi:10.1198 / 000313001753272420. JSTOR 2685690. S2CID 122328846.
- ^ “Was bedeutet das 5 Sigma?”. Physics.org. Abgerufen 5. Februar 2019.
- ^ “CERN-Experimente beobachten Partikel, die mit dem lang ersehnten Higgs-Boson | übereinstimmen CERN-Pressestelle”. Drücken Sie.web.cern.ch. 4. Juli 2012. Abgerufen 30. Mai 2015.
- ^ LIGO Scientific Collaboration, Virgo Collaboration (2016), “Beobachtung von Gravitationswellen aus einer binären Schwarzlochfusion”, Briefe zur körperlichen Überprüfung, 116 (6): 061102, arXiv:1602.03837, Bibcode:2016PhRvL.116f1102A, doi:10.1103 / PhysRevLett.116.061102, PMID 26918975, S2CID 124959784
- ^ “Was ist Standardabweichung?”. Unberührt. Abgerufen 29. Oktober 2011.
- ^ Ghahramani, Saeed (2000). Grundlagen der Wahrscheinlichkeit (2. Aufl.). New Jersey: Prentice Hall. p. 438.
- ^ Eric W. Weisstein. “Verteilungsfunktion”. MathWorld – Eine Wolfram-Webressource. Abgerufen 30. September 2014.
- ^ Welford, BP (August 1962). “Hinweis zu einer Methode zur Berechnung korrigierter Quadratsummen und Produkte”. Technometrie. 4 (3): 419–420. CiteSeerX 10.1.1.302.7503. doi:10.1080 / 00401706.1962.10490022.
- ^ Dodge, Yadolah (2003). Das Oxford Dictionary of Statistical Terms. Oxford University Press. ISBN 978-0-19-920613-1.
- ^ Pearson, Karl (1894). “Zur Dissektion asymmetrischer Frequenzkurven”. Philosophische Transaktionen der Royal Society A.. 185: 71–110. Bibcode:1894RSPTA.185 … 71P. doi:10.1098 / rsta.1894.0003.
- ^ Miller, Jeff. “Früheste bekannte Verwendung einiger Wörter der Mathematik”.
Externe Links[edit]
Recent Comments