Clustering-Koeffizient – Wikipedia
Messen Sie, wie verbunden und gruppiert ein Knoten in seinem Diagramm ist
In der Graphentheorie a Clustering-Koeffizient ist ein Maß für den Grad, in dem Knoten in einem Diagramm dazu neigen, sich zu gruppieren. Es gibt Hinweise darauf, dass in den meisten realen Netzwerken und insbesondere in sozialen Netzwerken Knoten dazu neigen, eng verbundene Gruppen zu bilden, die durch eine relativ hohe Dichte an Bindungen gekennzeichnet sind. Diese Wahrscheinlichkeit ist tendenziell größer als die durchschnittliche Wahrscheinlichkeit einer zufällig zwischen zwei Knoten hergestellten Verbindung (Holland und Leinhardt, 1971;[1] Watts und Strogatz, 1998[2]).
Es gibt zwei Versionen dieser Maßnahme: die globale und die lokale. Die globale Version wurde entwickelt, um einen allgemeinen Hinweis auf das Clustering im Netzwerk zu geben, während die lokale Version einen Hinweis auf die Einbettung einzelner Knoten gibt.
Lokaler Clusterkoeffizient[edit]
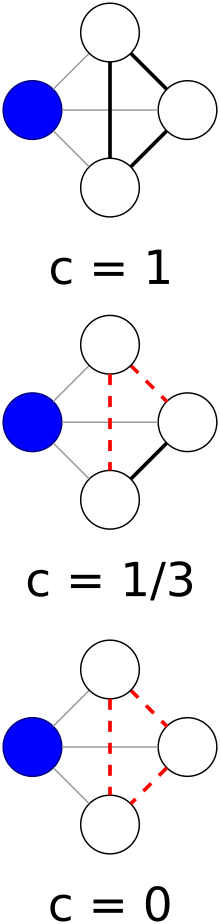
Das lokaler Clusterkoeffizient eines Scheitelpunkts (Knotens) in einem Diagramm quantifiziert, wie nahe seine Nachbarn an einer Clique sind (vollständiges Diagramm). Duncan J. Watts und Steven Strogatz führten die Maßnahme 1998 ein, um festzustellen, ob ein Graph ein kleines Netzwerk ist.
Ein Graph
besteht formal aus einer Reihe von Eckpunkten
 besteht formal aus einer Reihe von Eckpunkten
besteht formal aus einer Reihe von Eckpunkten und eine Reihe von Kanten
 und eine Reihe von Kanten
und eine Reihe von Kanten zwischen ihnen. Eine Ecke
 zwischen ihnen. Eine Ecke
zwischen ihnen. Eine Ecke verbindet den Scheitelpunkt
 verbindet den Scheitelpunkt
verbindet den Scheitelpunkt mit Scheitelpunkt
 mit Scheitelpunkt
mit Scheitelpunkt .
 .
.
Die Nachbarschaft
für einen Scheitelpunkt
 für einen Scheitelpunkt
für einen Scheitelpunkt wird wie folgt als seine unmittelbar verbundenen Nachbarn definiert:

Wir definieren
als die Anzahl der Eckpunkte,
 als die Anzahl der Eckpunkte,
als die Anzahl der Eckpunkte, , in der Nachbarschaft,
 , in der Nachbarschaft,
, in der Nachbarschaft, eines Scheitelpunktes.
Der lokale Clusterkoeffizient
für einen Scheitelpunkt
 für einen Scheitelpunkt
für einen Scheitelpunkt ist dann gegeben durch den Anteil der Verbindungen zwischen den Eckpunkten innerhalb ihrer Nachbarschaft geteilt durch die Anzahl der Verbindungen, die möglicherweise zwischen ihnen existieren könnten. Für einen gerichteten Graphen
unterscheidet sich von
und daher für jede Nachbarschaft
 und daher für jede Nachbarschaft
und daher für jede Nachbarschaft es gibt
Verknüpfungen, die zwischen den Eckpunkten in der Nachbarschaft bestehen könnten (
 Verknüpfungen, die zwischen den Eckpunkten in der Nachbarschaft bestehen könnten (
Verknüpfungen, die zwischen den Eckpunkten in der Nachbarschaft bestehen könnten (ist die Anzahl der Nachbarn eines Scheitelpunkts). Und so kam es dass der lokaler Clusterkoeffizient für gerichtete Graphen ist gegeben als [2]

Ein ungerichteter Graph hat die Eigenschaft, dass
und
gelten als identisch. Daher, wenn ein Scheitelpunkt
hat
Nachbarn,
Kanten könnten zwischen den Eckpunkten innerhalb der Nachbarschaft existieren. Und so kam es dass der lokaler Clustering-Koeffizient für ungerichtete Graphen kann definiert werden als
 Kanten könnten zwischen den Eckpunkten innerhalb der Nachbarschaft existieren. Und so kam es dass der lokaler Clustering-Koeffizient für ungerichtete Graphen kann definiert werden als
Kanten könnten zwischen den Eckpunkten innerhalb der Nachbarschaft existieren. Und so kam es dass der lokaler Clustering-Koeffizient für ungerichtete Graphen kann definiert werden als

Lassen
sei die Anzahl der Dreiecke an
 sei die Anzahl der Dreiecke an
sei die Anzahl der Dreiecke an für ungerichteten Graphen
 für ungerichteten Graphen
für ungerichteten Graphen . Das ist,
 . Das ist,
. Das ist, ist die Anzahl der Untergraphen von
mit 3 Kanten und 3 Eckpunkten, von denen einer ist
. Lassen
 . Lassen
. Lassen sei die Anzahl der Tripel
 sei die Anzahl der Tripel
sei die Anzahl der Tripel . Das ist,
 . Das ist,
. Das ist, ist die Anzahl der Teilgraphen (nicht unbedingt induziert) mit 2 Kanten und 3 Eckpunkten, von denen einer ist
und so dass
fällt an beiden Kanten auf. Dann können wir auch den Clustering-Koeffizienten als definieren

Es ist einfach zu zeigen, dass die beiden vorhergehenden Definitionen gleich sind, da

Diese Maßnahmen sind 1, wenn jeder Nachbar mit verbunden ist
ist auch mit jedem anderen Scheitelpunkt in der Nachbarschaft verbunden und 0, wenn kein Scheitelpunkt mit verbunden ist
verbindet sich mit jedem anderen Scheitelpunkt, mit dem verbunden ist
.
Da jeder Graph durch seine Adjazenzmatrix vollständig spezifiziert ist EINkann der lokale Clusterkoeffizient für einen einfachen ungerichteten Graphen ausgedrückt werden als EIN wie:[3]

wo:

und C.ich= 0 wenn kich ist null oder eins. Im obigen Ausdruck zählt der Zähler doppelt so viele vollständige Dreiecke wie dieser Scheitelpunkt ich ist beteiligt an. Im Nenner, kich2 zählt die Anzahl der Kantenpaare, die vertexen ich ist beteiligt an plus der Anzahl der einzelnen Kanten, die zweimal durchlaufen werden. kich ist die Anzahl der Kanten, die mit dem Scheitelpunkt i verbunden sind und subtrahieren kich entfernt dann letzteres und lässt nur einen Satz von Kantenpaaren übrig, die möglicherweise zu Dreiecken verbunden werden könnten. Für jedes solche Kantenpaar gibt es ein weiteres Kantenpaar, das das gleiche Dreieck bilden könnte, sodass der Nenner doppelt so viele denkbare Dreiecke wie dieser Scheitelpunkt zählt ich beteiligt sein könnte.
Globaler Clustering-Koeffizient[edit]
Das globaler Clusterkoeffizient basiert auf Tripletts von Knoten. Ein Triplett besteht aus drei Knoten, die entweder durch zwei (offenes Triplett) oder drei (geschlossenes Triplett) ungerichtete Bindungen verbunden sind. Ein Dreiecksgraph enthält daher drei geschlossene Tripletts, von denen eines auf jedem der Knoten zentriert ist (nb bedeutet, dass die drei Tripletts in einem Dreieck aus überlappenden Auswahlen von Knoten stammen). Der globale Clusterkoeffizient ist die Anzahl der geschlossenen Tripletts (oder 3 x Dreiecke) über der Gesamtzahl der Tripletts (sowohl offen als auch geschlossen). Der erste Versuch, es zu messen, wurde von Luce und Perry (1949) unternommen.[4] Diese Maßnahme gibt einen Hinweis auf die Clusterbildung im gesamten Netzwerk (global) und kann sowohl auf ungerichtete als auch auf gerichtete Netzwerke angewendet werden (häufig als Transitivität bezeichnet, siehe Wasserman und Faust, 1994, Seite 243)[5]).
Der globale Clustering-Koeffizient ist definiert als:
- .

Die Anzahl der geschlossenen Tripletts wurde in der Literatur auch als 3 × Dreiecke bezeichnet.
- .

Eine Verallgemeinerung auf gewichtete Netzwerke wurde von Opsahl und Panzarasa (2009) vorgeschlagen.[6] und eine Neudefinition von Zwei-Modus-Netzwerken (sowohl binär als auch gewichtet) von Opsahl (2009).[7]
Da jeder Graph durch seine Adjazenzmatrix vollständig spezifiziert ist EINkann der globale Clusterkoeffizient für einen ungerichteten Graphen ausgedrückt werden als EIN wie:

wo:
und C.= 0, wenn der Nenner Null ist.
Durchschnittlicher Clustering-Koeffizient des Netzwerks[edit]
Alternativ zum globalen Clustering-Koeffizienten wird der Gesamtgrad der Clustering in einem Netzwerk von Watts und Strogatz gemessen[2] als Durchschnitt der lokalen Clusterkoeffizienten aller Eckpunkte
::[8]
 ::[8]
::[8]
Es ist erwähnenswert, dass diese Metrik den Knoten mit niedrigem Grad mehr Gewicht beimisst, während das Transitivitätsverhältnis den Knoten mit hohem Grad mehr Gewicht beimisst.
Ein Graph wird als kleine Welt betrachtet, wenn der Graph eine kleine mittlere kürzeste Pfadlänge hat, die mit dem natürlichen Protokoll der Anzahl der Knoten im Netzwerk skaliert.
.[9] Zum Beispiel ist ein Zufallsgraph eine kleine Welt, ein Gitter nicht, und skalierungsfreie Graphen werden oft als ultrakleine Welt betrachtet, da ihre mittlere kürzeste Pfadlänge mit skaliert
 .[9] Zum Beispiel ist ein Zufallsgraph eine kleine Welt, ein Gitter nicht, und skalierungsfreie Graphen werden oft als ultrakleine Welt betrachtet, da ihre mittlere kürzeste Pfadlänge mit skaliert
.[9] Zum Beispiel ist ein Zufallsgraph eine kleine Welt, ein Gitter nicht, und skalierungsfreie Graphen werden oft als ultrakleine Welt betrachtet, da ihre mittlere kürzeste Pfadlänge mit skaliert .
 .
.
Eine Verallgemeinerung auf gewichtete Netzwerke wurde von Barrat et al. (2004),[10] und eine Neudefinition zu zweigeteilten Graphen (auch als Zwei-Moden-Netzwerke bezeichnet) von Latapy et al. (2008)[11] und Opsahl (2009).[7]
Alternative Verallgemeinerungen zu gewichteten und gerichteten Graphen wurden von Fagiolo (2007) bereitgestellt.[12] und Clemente und Grassi (2018).[13]
Diese Formel ist standardmäßig nicht für Diagramme mit isolierten Scheitelpunkten definiert. siehe Kaiser (2008)[14] und Barmpoutis et al.[15] Die Netzwerke mit dem größtmöglichen durchschnittlichen Clusterkoeffizienten haben einen modularen Aufbau und gleichzeitig den kleinstmöglichen durchschnittlichen Abstand zwischen den verschiedenen Knoten.[15]
Versickerung von Clusternetzwerken[edit]
Zur Untersuchung der Robustheit von Clusternetzwerken wird ein Perkolationsansatz entwickelt.[16][17][18] Die Robustheit gegenüber lokalisierten Angriffen wurde unter Verwendung lokalisierter Perkolation untersucht.[19]
Die Wellenlokalisierung in komplexen Clusternetzwerken wurde ebenfalls untersucht.[20]
Siehe auch[edit]
Verweise[edit]
- ^ PW Holland & S. Leinhardt (1971). “Transitivität in Strukturmodellen kleiner Gruppen”. Vergleichende Gruppenstudien. 2 (2): 107–124. doi:10.1177 / 104649647100200201.
- ^ ein b c DJ Watts & Steven Strogatz (Juni 1998). “Kollektive Dynamik von ‘Small-World’-Netzwerken”. Natur. 393 (6684): 440–442. Bibcode:1998Natur.393..440W. doi:10.1038 / 30918. PMID 9623998.
- ^ Wang, Yu; Ghumare, Eshwar; Vandenberghe, Rik; Dupont, Patrick (2017). “Vergleich verschiedener Verallgemeinerungen des Clustering-Koeffizienten und der lokalen Effizienz für gewichtete ungerichtete Graphen”. Neuronale Berechnung. 29 (2): 313–331. doi:10.1162 / NECO_a_00914. Abgerufen 8. August 2020.
- ^ RD Luce & AD Perry (1949). “Eine Methode zur Matrixanalyse der Gruppenstruktur”. Psychometrika. 14 (1): 95–116. doi:10.1007 / BF02289146. PMID 18152948.
- ^ Stanley Wasserman, Katherine Faust, 1994. Analyse sozialer Netzwerke: Methoden und Anwendungen. Cambridge: Cambridge University Press.
- ^ Tore Opsahl & Pietro Panzarasa (2009). “Clustering in gewichteten Netzwerken”. Soziale Netzwerke. 31 (2): 155–163. doi:10.1016 / j.socnet.2009.02.002.
- ^ ein b Tore Opsahl (2009). “Clustering in Zwei-Modus-Netzwerken”. Konferenz und Workshop zur Zwei-Moden-Sozialanalyse (30. September – 2. Oktober 2009).
- ^ Kemper, Andreas (2009). Bewertung von Netzwerkeffekten in Softwaremärkten: Ein komplexer Netzwerkansatz. Springer. p. 142. ISBN 9783790823660.
- ^ http://networksciencebook.com/4#ultra-small
- ^ Barrat, A.; Barthelemy, M.; Pastor-Satorras, R.; Vespignani, A. (2004). “Die Architektur komplexer gewichteter Netzwerke”. Verfahren der Nationalen Akademie der Wissenschaften. 101 (11): 3747–3752. arXiv:cond-mat / 0311416. Bibcode:2004PNAS..101.3747B. doi:10.1073 / pnas.0400087101. PMC 374315. PMID 15007165.
- ^ Latapy, M.; Magnien, C.; Del Vecchio, N. (2008). “Grundbegriffe für die Analyse großer Zwei-Modus-Netzwerke”. Soziale Netzwerke. 30 (1): 31–48. doi:10.1016 / j.socnet.2007.04.006.
- ^ Fagiolo, G. (2007). “Clustering in komplex gerichteten Netzwerken”. Körperliche Überprüfung E.. 76 (2 Pt 2): 026107. CiteSeerX 10.1.1.262.1006. doi:10.1103 / PhysRevE.76.026107. PMID 17930104.
- ^ Clemente, GP; Grassi, R. (2018). “Directed Clustering in gewichteten Netzwerken: Eine neue Perspektive”. Chaos, Solitonen & Fraktale. 107: 26–38. arXiv:1706.07322. Bibcode:2018CSF … 107 … 26C. doi:10.1016 / j.chaos.2017.12.007.
- ^ Kaiser, Marcus (2008). “Mittlere Clusterkoeffizienten: Die Rolle isolierter Knoten und Blätter bei Clustering-Maßnahmen für Netzwerke in kleinen Welten”. Neues Journal für Physik. 10 (8): 083042. arXiv:0802.2512. Bibcode:2008NJPh … 10h3042K. doi:10.1088 / 1367-2630 / 10/8/083042.
- ^ ein b Barmpoutis, D.; Murray, RM (2010). “Netzwerke mit der kleinsten durchschnittlichen Entfernung und dem größten durchschnittlichen Clustering”. arXiv:1007.4031 [q-bio.MN].
- ^ MEJ Newman (2009). “Zufällige Graphen mit Clustering”. Phys. Rev. Lett. 103: 058701.
- ^ A. Hackett; S. Melnik & JP Gleeson (2011). “Kaskaden in einer Klasse von Cluster-Zufallsnetzwerken”. Phys. Rev. E.. 83: 056107.
- ^ S. Shao; X. Huang; ER Stanley; S. Havlin (2014). “Robustheit eines teilweise voneinander abhängigen Netzwerks aus Cluster-Netzwerken”. Phys. Rev. E.. 89: 032812.
- ^ Fan Wang; Ruijin Du; Lixin Tian; Shuai Shao; H Eugene Stanley; Shlomo Havlin (2019). “Lokalisierter Angriff auf Netzwerke mit Clustering Huifang Hao”. Neues Journal für Physik. 21: 013014.
- ^ L. Jahnke; JW Kantelhardt; R. Berkovits; S. Havlin Phys (2008). “Wellenlokalisierung in komplexen Netzwerken mit hohem Clustering”. Phys. Rev. Lett. 101: 175702.
Recent Comments