DNA-Replikation – Wikipedia
Biologischer Prozess
In der Molekularbiologie, DNA Replikation ist der biologische Prozess der Herstellung zweier identischer DNA-Replikate aus einem ursprünglichen DNA-Molekül.[1] Die DNA-Replikation findet in allen lebenden Organismen statt und ist der wichtigste Teil der biologischen Vererbung. Dies ist wichtig für die Zellteilung während des Wachstums und der Reparatur von geschädigtem Gewebe und stellt gleichzeitig sicher, dass jede der neuen Zellen ihre eigene Kopie der DNA erhält.[2] Die Zelle besitzt die charakteristische Eigenschaft der Teilung, die die Replikation der DNA unabdingbar macht.
DNA besteht aus einer Doppelhelix zweier komplementärer Stränge. Die Doppelhelix beschreibt das Erscheinungsbild einer doppelsträngigen DNA, die also aus zwei linearen Strängen besteht, die gegeneinander verlaufen und sich zu einer Form verdrillen.[3] Während der Replikation werden diese Stränge getrennt. Jeder Strang des ursprünglichen DNA-Moleküls dient dann als Matrize für die Herstellung seines Gegenstücks, ein Prozess, der als semikonservative Replikation bezeichnet wird. Als Ergebnis der semikonservativen Replikation wird die neue Helix aus einem ursprünglichen DNA-Strang sowie einem neu synthetisierten Strang bestehen.[4] Zelluläre Korrekturlese- und Fehlerprüfungsmechanismen sorgen für eine nahezu perfekte Wiedergabetreue der DNA-Replikation.[5][6]
In einer Zelle beginnt die DNA-Replikation an bestimmten Stellen oder Replikationsursprüngen im Genom[7] die das genetische Material eines Organismus enthält.[8] Das Abwickeln der DNA am Ursprung und die Synthese neuer Stränge, die von einem Enzym namens Helikase aufgenommen werden, führt dazu, dass Replikationsgabeln bidirektional vom Ursprung aus wachsen. Eine Reihe von Proteinen ist mit der Replikationsgabel verbunden, um bei der Initiierung und Fortsetzung der DNA-Synthese zu helfen. Am prominentesten synthetisiert die DNA-Polymerase die neuen Stränge, indem sie Nukleotide hinzufügt, die jeden (Matrizen-)Strang komplementieren. Die DNA-Replikation findet während des S-Stadiums der Interphase statt.
DNA-Replikation (DNA-Amplifikation) kann auch durchgeführt werden in vitro (künstlich außerhalb einer Zelle). Aus Zellen isolierte DNA-Polymerasen und künstliche DNA-Primer können verwendet werden, um die DNA-Synthese an bekannten Sequenzen in einem DNA-Matrizenmolekül zu starten. Beispiele hierfür sind die Polymerase-Kettenreaktion (PCR), die Ligase-Kettenreaktion (LCR) und die transkriptionsvermittelte Amplifikation (TMA). Im März 2021 berichteten Forscher über Hinweise darauf, dass eine vorläufige Form der Transfer-RNA, eine notwendige Komponente der Translation, der biologischen Synthese neuer Proteine gemäß dem genetischen Code, in der sehr frühen Entwicklung des Lebens selbst ein Replikatormolekül gewesen sein könnte. oder Abiogenese.[9][10]
DNA-Struktur[edit]
DNA existiert als doppelsträngige Struktur, wobei beide Stränge zusammengerollt sind, um die charakteristische Doppelhelix zu bilden. Jeder DNA-Einzelstrang ist eine Kette von vier Nukleotidtypen. Nukleotide in DNA enthalten einen Desoxyribose-Zucker, ein Phosphat und eine Nukleobase. Die vier Nukleotidtypen entsprechen den vier Nukleobasen Adenin, Cytosin, Guanin und Thymin, die üblicherweise als A, C, G und T abgekürzt werden. Adenin und Guanin sind Purinbasen, während Cytosin und Thymin Pyrimidine sind. Diese Nukleotide bilden Phosphodiesterbindungen, wodurch das Phosphat-Desoxyribose-Rückgrat der DNA-Doppelhelix gebildet wird, wobei die Nukleobasen nach innen (dh zum Gegenstrang) zeigen. Nukleobasen werden zwischen Strängen durch Wasserstoffbrücken gepaart, um Basenpaare zu bilden. Adenin paart sich mit Thymin (zwei Wasserstoffbrücken) und Guanin paart mit Cytosin (drei Wasserstoffbrücken).
DNA-Stränge haben eine Direktionalität, und die verschiedenen Enden eines Einzelstrangs werden als “3′ (drei-primes) Ende” und “5′ (fünf-gestrichenes) Ende” bezeichnet. Wenn die Basensequenz eines DNA-Einzelstrangs angegeben ist, ist das linke Ende der Sequenz das 5′-Ende, während das rechte Ende der Sequenz das 3′-Ende ist. Die Stränge der Doppelhelix sind antiparallel, wobei einer von 5′ bis 3′ und der gegenüberliegende Strang von 3′ bis 5′ verläuft. Diese Begriffe beziehen sich auf das Kohlenstoffatom in Desoxyribose, an das sich das nächste Phosphat in der Kette anlagert. Direktionalität hat Konsequenzen bei der DNA-Synthese, da DNA-Polymerase DNA nur in eine Richtung synthetisieren kann, indem sie Nukleotide an das 3′-Ende eines DNA-Strangs anfügt.
Die Paarung komplementärer Basen in der DNA (durch Wasserstoffbrückenbindung) bedeutet, dass die in jedem Strang enthaltenen Informationen redundant sind. Phosphodiester-(Intra-Strang-)Bindungen sind stärker als Wasserstoff-(Zwischen-Strang-)Bindungen. Die eigentliche Aufgabe der Phosphodiester-Bindungen besteht darin, in DNA-Polymeren den 5′-Kohlenstoff eines Nukleotids mit dem 3′-Kohlenstoff eines anderen Nukleotids zu verbinden, während die Wasserstoffbrücken die DNA-Doppelhelices entlang der Helixachse stabilisieren, aber nicht in Richtung der Achse 1 .[11] Dadurch können die Stränge voneinander getrennt werden. Die Nukleotide an einem Einzelstrang können daher verwendet werden, um Nukleotide an einem neu synthetisierten Partnerstrang zu rekonstruieren.[12]
DNA-Polymerase[edit]

DNA-Polymerasen sind eine Familie von Enzymen, die alle Formen der DNA-Replikation durchführen.[14] DNA-Polymerasen können im Allgemeinen keine Synthese neuer Stränge initiieren, sondern können nur einen bestehenden DNA- oder RNA-Strang, der mit einem Matrizenstrang gepaart ist, verlängern. Um mit der Synthese zu beginnen, muss ein kurzes RNA-Fragment, ein sogenannter Primer, erzeugt und mit dem DNA-Matrizenstrang gepaart werden.
DNA-Polymerase fügt einen neuen DNA-Strang hinzu, indem sie das 3′-Ende einer bestehenden Nukleotidkette verlängert, indem neue Nukleotide hinzugefügt werden, die nacheinander über die Bildung von Phosphodiester-Bindungen an den Matrizenstrang angepasst sind. Die Energie für diesen Prozess der DNA-Polymerisation stammt aus der Hydrolyse der hochenergetischen Phosphatbindungen (Phosphoanhydrid) zwischen den drei Phosphaten, die an jede nicht eingebaute Base gebunden sind. Freie Basen mit ihren angehängten Phosphatgruppen werden Nukleotide genannt; insbesondere werden Basen mit drei gebundenen Phosphatgruppen als Nukleosidtriphosphate bezeichnet. Beim Anfügen eines Nukleotids an einen wachsenden DNA-Strang wird die Bildung einer Phosphodiesterbindung zwischen dem proximalen Phosphat des Nukleotids an die wachsende Kette von der Hydrolyse einer hochenergetischen Phosphatbindung unter Freisetzung der beiden distalen Phosphate als Pyrophosphat begleitet . Die enzymatische Hydrolyse des resultierenden Pyrophosphats zu anorganischem Phosphat verbraucht eine zweite energiereiche Phosphatbindung und macht die Reaktion effektiv irreversibel.[Note 1]
Im Allgemeinen sind DNA-Polymerasen sehr genau, mit einer intrinsischen Fehlerrate von weniger als einem Fehler pro 107 Nukleotide hinzugefügt.[15] Darüber hinaus haben einige DNA-Polymerasen auch die Fähigkeit zum Korrekturlesen; sie können Nukleotide vom Ende eines wachsenden Strangs entfernen, um fehlgepaarte Basen zu korrigieren. Schließlich überwachen Fehlpaarungsreparaturmechanismen nach der Replikation die DNA auf Fehler und sind in der Lage, Fehlpaarungen in dem neu synthetisierten DNA-Strang von der ursprünglichen Strangsequenz zu unterscheiden. Zusammen ermöglichen diese drei Unterscheidungsschritte eine Replikationstreue von weniger als einem Fehler pro 109 Nukleotide hinzugefügt.[15]
Die DNA-Replikationsrate in einer lebenden Zelle wurde zuerst als die Rate der Phagen-T4-DNA-Verlängerung in Phagen-infizierten gemessen E coli.[16] Während des exponentiellen DNA-Anstiegs bei 37 °C betrug die Rate 749 Nukleotide pro Sekunde. Die Mutationsrate pro Basenpaar pro Replikation während der Phagen-T4-DNA-Synthese beträgt 1,7 pro 108.[17]
Replikationsprozess[edit]

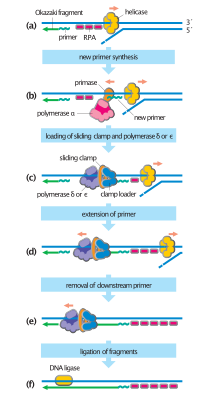
Die DNA-Replikation läuft wie alle biologischen Polymerisationsprozesse in drei enzymatisch katalysierten und koordinierten Schritten ab: Initiation, Elongation und Termination.
Einleitung[edit]
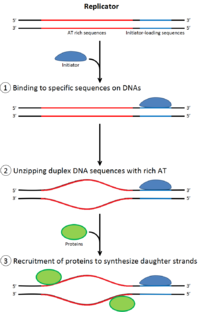
Damit sich eine Zelle teilen kann, muss sie zunächst ihre DNA replizieren.[18] Die DNA-Replikation ist ein Alles-oder-nichts-Prozess; Sobald die Replikation beginnt, wird sie abgeschlossen. Sobald die Replikation abgeschlossen ist, tritt sie im selben Zellzyklus nicht erneut auf. Dies wird durch die Aufteilung der Initiation des Prä-Replikationskomplexes ermöglicht.
Prä-Replikationskomplex[edit]
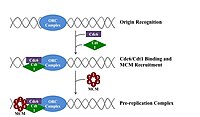
In der späten Mitose- und frühen G1-Phase assembliert ein großer Komplex von Initiatorproteinen an bestimmten Punkten in der DNA, die als “Ursprünge” bekannt sind, zum Prä-Replikationskomplex.[7] In E coli das primäre Initiatorprotein ist DNAA; in Hefe ist dies der Ursprungserkennungskomplex.[19] Sequenzen, die von Initiatorproteinen verwendet werden, neigen dazu, “AT-reich” zu sein (reich an Adenin- und Thyminbasen), da AT-Basenpaare zwei Wasserstoffbrückenbindungen haben (anstelle der drei, die in einem CG-Paar gebildet werden) und daher leichter zu trennen sind.[20] In Eukaryoten katalysiert der Ursprungserkennungskomplex den Zusammenbau von Initiatorproteinen in den Präreplikationskomplex. Cdc6 und Cdt1 assoziieren dann mit dem gebundenen Ursprungserkennungskomplex am Ursprung, um einen größeren Komplex zu bilden, der notwendig ist, um den Mcm-Komplex auf die DNA zu laden. Der Mcm-Komplex ist die Helikase, die die DNA-Helix an den Replikationsstartpunkten und Replikationsgabeln in Eukaryoten entwirrt. Der Mcm-Komplex wird in der späten G1-Phase rekrutiert und durch den ORC-Cdc6-Cdt1-Komplex über ATP-abhängiges Protein-Remodeling auf die DNA geladen. Das Laden des Mcm-Komplexes auf die Ursprungs-DNA markiert den Abschluss der Komplexbildung vor der Replikation.[21]
Wenn die Umweltbedingungen in der späten G1-Phase stimmen, werden die G1- und G1/S-Cyclin-Cdk-Komplexe aktiviert, die die Expression von Genen stimulieren, die Komponenten der DNA-Synthesemaschinerie kodieren. Die G1/S-Cdk-Aktivierung fördert auch die Expression und Aktivierung von S-Cdk-Komplexen, die je nach Spezies und Zelltyp eine Rolle bei der Aktivierung von Replikationsstartpunkten spielen können. Die Kontrolle dieser Cdks variiert je nach Zelltyp und Entwicklungsstadium. Diese Regulation wird am besten in knospenden Hefen verstanden, wo die S-Cycline Clb5 und Clb6 hauptsächlich für die DNA-Replikation verantwortlich sind.[22] Clb5,6-Cdk1-Komplexe lösen direkt die Aktivierung von Replikationsstartpunkten aus und werden daher während der gesamten S-Phase benötigt, um jeden Startpunkt direkt zu aktivieren.[21]
In ähnlicher Weise wird Cdc7 auch durch die S-Phase benötigt, um Replikationsstartpunkte zu aktivieren. Cdc7 ist während des gesamten Zellzyklus nicht aktiv und seine Aktivierung wird streng zeitlich gesteuert, um eine vorzeitige Initiation der DNA-Replikation zu vermeiden. Im späten G1 steigt die Cdc7-Aktivität abrupt als Folge der Assoziation mit der regulatorischen Untereinheit Dbf4 an, die Cdc7 direkt bindet und dessen Proteinkinase-Aktivität fördert. Es wurde festgestellt, dass Cdc7 ein geschwindigkeitsbegrenzender Regulator der Ursprungsaktivität ist. Zusammen wirken die G1/S-Cdks und/oder S-Cdks und Cdc7 zusammen, um die Replikationsursprünge direkt zu aktivieren, was zur Initiation der DNA-Synthese führt.[21]
Präinitiationskomplex[edit]
In der frühen S-Phase führt die Aktivierung von S-Cdk und Cdc7 zum Zusammenbau des Präinitiationskomplexes, eines massiven Proteinkomplexes, der am Ursprung gebildet wird. Die Bildung des Präinitiationskomplexes verdrängt Cdc6 und Cdt1 aus dem Ursprungsreplikationskomplex, inaktiviert und zerlegt den Präreplikationskomplex. Das Laden des Präinitiationskomplexes auf den Ursprung aktiviert die Mcm-Helikase, wodurch die DNA-Helix abgewickelt wird. Der Präinitiationskomplex lädt auch α-Primase und andere DNA-Polymerasen auf die DNA.[21]
Nachdem die α-Primase die ersten Primer synthetisiert hat, interagieren die Primer-Template-Verbindungen mit dem Clamp Loader, der die Gleitklemme auf die DNA lädt, um die DNA-Synthese zu beginnen. Die Komponenten des Präinitiationskomplexes bleiben mit Replikationsgabeln verbunden, wenn sie sich vom Ursprung entfernen.[21]
Verlängerung[edit]
DNA-Polymerase hat 5′–3′-Aktivität. Alle bekannten DNA-Replikationssysteme benötigen eine freie 3′-Hydroxylgruppe, bevor die Synthese eingeleitet werden kann (Anmerkung: Das DNA-Templat wird in 3′ bis 5′-Richtung gelesen, während ein neuer Strang in 5′ bis 3′-Richtung synthetisiert wird – dies ist oft verwirrt). Vier verschiedene Mechanismen für die DNA-Synthese sind bekannt:
- Alle zellulären Lebensformen und viele DNA-Viren, Phagen und Plasmide verwenden eine Primase, um einen kurzen RNA-Primer mit einer freien 3′-OH-Gruppe zu synthetisieren, der anschließend durch eine DNA-Polymerase verlängert wird.
- Die Retroelemente (einschließlich Retroviren) verwenden eine Transfer-RNA, die die DNA-Replikation anregt, indem sie ein freies 3′-OH bereitstellt, das zur Elongation durch die reverse Transkriptase verwendet wird.
- Bei den Adenoviren und der 29-Familie von Bakteriophagen wird die 3′-OH-Gruppe von der Seitenkette einer Aminosäure des genomgebundenen Proteins (dem terminalen Protein) bereitgestellt, an das Nukleotide durch die DNA-Polymerase angefügt werden, um einen neuen Strang zu bilden.
- Bei den einzelsträngigen DNA-Viren – einer Gruppe, die Circoviren, Geminiviren, Parvoviren und anderen umfasst – und auch bei den vielen Phagen und Plasmiden, die den Rolling Circle Replication (RCR)-Mechanismus verwenden, erzeugt die RCR-Endonuklease eine Kerbe im Genomstrang (einzelsträngige Viren) oder einer der DNA-Stränge (Plasmide). Das 5′-Ende des geknickten Strangs wird auf einen Tyrosinrest an der Nuklease übertragen und die freie 3′-OH-Gruppe wird dann von der DNA-Polymerase verwendet, um den neuen Strang zu synthetisieren.
Der erste ist der bekannteste dieser Mechanismen und wird von den zellulären Organismen genutzt. Bei diesem Mechanismus fügt Primase, sobald die beiden Stränge getrennt sind, RNA-Primer zu den Matrizensträngen hinzu. Der führende Strang erhält einen RNA-Primer, während der nachlaufende Strang mehrere erhält. Der führende Strang wird kontinuierlich von dem Primer durch eine DNA-Polymerase mit hoher Prozessivität verlängert, während der nachlaufende Strang von jedem Primer diskontinuierlich verlängert wird, wodurch Okazaki-Fragmente gebildet werden. RNase entfernt die Primer-RNA-Fragmente, und eine DNA-Polymerase mit geringer Prozessivität, die sich von der replikativen Polymerase unterscheidet, tritt ein, um die Lücken zu füllen. Wenn dies abgeschlossen ist, können eine einzelne Kerbe auf dem führenden Strang und mehrere Kerben auf dem nacheilenden Strang gefunden werden. Ligase arbeitet daran, diese Kerben auszufüllen und so das neu replizierte DNA-Molekül zu vervollständigen.
Die dabei verwendete Primase unterscheidet sich deutlich zwischen Bakterien und Archaeen/Eukaryoten. Bakterien verwenden eine Primase, die zur DnaG-Protein-Superfamilie gehört, die eine katalytische Domäne des TOPRIM-Faltungstyps enthält.[23] Die TOPRIM-Faltung enthält einen α/β-Kern mit vier konservierten Strängen in einer Rossmann-ähnlichen Topologie. Diese Struktur findet sich auch in den katalytischen Domänen von Topoisomerase Ia, Topoisomerase II, den Nukleasen der OLD-Familie und DNA-Reparaturproteinen, die mit dem RecR-Protein verwandt sind.
Die von Archaeen und Eukaryoten verwendete Primase enthält dagegen eine stark abgeleitete Version des RNA-Erkennungsmotivs (RRM). Diese Primase ist strukturell vielen viralen RNA-abhängigen RNA-Polymerasen, reversen Transkriptasen, zyklische Nukleotid-erzeugenden Cyclasen und DNA-Polymerasen der A/B/Y-Familien ähnlich, die an der DNA-Replikation und -Reparatur beteiligt sind. Bei der eukaryontischen Replikation bildet die Primase mit Pol α einen Komplex.[24]
Mehrere DNA-Polymerasen übernehmen unterschiedliche Rollen im DNA-Replikationsprozess. In E coli, DNA Pol III ist das Polymerase-Enzym, das hauptsächlich für die DNA-Replikation verantwortlich ist. Es assembliert an der Replikationsgabel zu einem Replikationskomplex, der eine extrem hohe Prozessivität aufweist und während des gesamten Replikationszyklus intakt bleibt. Im Gegensatz dazu ist DNA Pol I das Enzym, das für den Ersatz von RNA-Primern durch DNA verantwortlich ist. DNA Pol I hat zusätzlich zu seiner Polymeraseaktivität eine 5′- bis 3′-Exonuklease-Aktivität und verwendet seine Exonuklease-Aktivität, um die RNA-Primer davor abzubauen, während es den dahinter liegenden DNA-Strang in einem als Nick-Translation bezeichneten Prozess verlängert. Pol I ist viel weniger prozessiv als Pol III, da seine Hauptfunktion bei der DNA-Replikation darin besteht, viele kurze DNA-Regionen zu erzeugen, anstatt einige sehr lange Regionen.
In Eukaryoten hilft das Enzym Pol α mit geringer Prozessivität, die Replikation zu initiieren, da es mit Primase einen Komplex bildet.[25] In Eukaryoten wird angenommen, dass die führende Strangsynthese von Pol durchgeführt wird; Diese Ansicht wurde jedoch kürzlich in Frage gestellt, was auf eine Rolle von Pol δ hindeutet.[26] Primerentfernung ist abgeschlossen Pol δ[27] während die Reparatur der DNA während der Replikation durch Pol abgeschlossen wird.
Während die DNA-Synthese fortschreitet, wickeln sich die ursprünglichen DNA-Stränge auf jeder Seite der Blase weiter ab und bilden eine Replikationsgabel mit zwei Zinken. Bei Bakterien, die auf ihrem kreisförmigen Chromosom einen einzigen Replikationsursprung haben, erzeugt dieser Prozess eine “Theta-Struktur” (ähnlich dem griechischen Buchstaben Theta: θ). Im Gegensatz dazu haben Eukaryoten längere lineare Chromosomen und initiieren die Replikation an mehreren Ursprüngen innerhalb dieser.[28]
Replikationsgabel[edit]
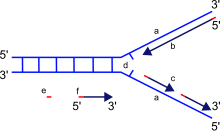
a: Templat, b: Leitstrang, c: Nachlaufstrang, d: Replikationsgabel, e: Primer, f: Okazaki-Fragmente

Die Replikationsgabel ist eine Struktur, die sich während der DNA-Replikation innerhalb der langen helikalen DNA bildet. Es wird von Helikasen erzeugt, die die Wasserstoffbrücken aufbrechen, die die beiden DNA-Stränge in der Helix zusammenhalten. Die resultierende Struktur hat zwei sich verzweigende “Zapfen”, von denen jede aus einem einzelnen DNA-Strang besteht. Diese beiden Stränge dienen als Matrize für die führenden und nacheilenden Stränge, die erzeugt werden, wenn die DNA-Polymerase komplementäre Nukleotide an die Matrizen anpasst; die Matrizen können richtigerweise als die Matrize des führenden Strangs und die Matrize des nacheilenden Strangs bezeichnet werden.
DNA wird von der DNA-Polymerase in 3′- bis 5′-Richtung gelesen, was bedeutet, dass der neue Strang in 5′- bis 3′-Richtung synthetisiert wird. Da die Matrizen des führenden und des nacheilenden Strangs an der Replikationsgabel in entgegengesetzte Richtungen orientiert sind, besteht ein Hauptproblem darin, wie die Synthese neuer DNA des nacheilenden Strangs erreicht werden kann, deren Syntheserichtung der Richtung der wachsenden Replikationsgabel entgegengesetzt ist.
Leitstrang[edit]
Der führende Strang ist der Strang der neuen DNA, der in der gleichen Richtung wie die wachsende Replikationsgabel synthetisiert wird. Diese Art der DNA-Replikation ist kontinuierlich.
Nachlaufender Strang[edit]
Der nachlaufende Strang ist der Strang neuer DNA, dessen Syntheserichtung der Richtung der wachsenden Replikationsgabel entgegengesetzt ist. Aufgrund seiner Orientierung ist die Replikation des nacheilenden Strangs komplizierter als die des führenden Strangs. Als Folge davon ist zu sehen, dass die DNA-Polymerase auf diesem Strang dem anderen Strang “hinterherhinkt”.
Der nacheilende Strang wird in kurzen, getrennten Segmenten synthetisiert. Auf dem nacheilenden Strand Vorlage, “liest” eine Primase die Matrizen-DNA und initiiert die Synthese eines kurzen komplementären RNA-Primers. Eine DNA-Polymerase verlängert die geprimten Segmente und bildet Okazaki-Fragmente. Die RNA-Primer werden dann entfernt und durch DNA ersetzt, und die DNA-Fragmente werden durch DNA-Ligase zusammengefügt.
Dynamik an der Replikationsgabel[edit]
In allen Fällen besteht die Helikase aus sechs Polypeptiden, die sich nur um einen Strang der zu replizierenden DNA wickeln. Die beiden Polymerasen sind an das Helikaseheximer gebunden. Bei Eukaryoten wickelt sich die Helikase um den führenden Strang und bei Prokaryoten um den nacheilenden Strang.[29]
Da die Helikase die DNA an der Replikationsgabel abwickelt, wird die vorausliegende DNA gezwungen, sich zu drehen. Dieser Prozess führt zu einer Ansammlung von Wendungen in der DNA vor Ihnen.[30] Dieser Aufbau bildet einen Torsionswiderstand, der schließlich den Fortschritt der Replikationsgabel stoppen würde. Topoisomerasen sind Enzyme, die die DNA-Stränge vorübergehend brechen und die Spannung abbauen, die durch das Abwickeln der beiden Stränge der DNA-Helix entsteht; Topoisomerasen (einschließlich DNA-Gyrase) erreichen dies, indem sie der DNA-Helix negative Supercoils hinzufügen.[31]
Nackte einzelsträngige DNA neigt dazu, sich in sich selbst zurückzufalten und Sekundärstrukturen zu bilden; diese Strukturen können die Bewegung der DNA-Polymerase stören. Um dies zu verhindern, binden einzelsträngige Bindungsproteine an die DNA, bis ein zweiter Strang synthetisiert ist, wodurch die Bildung einer Sekundärstruktur verhindert wird.[32]
Doppelsträngige DNA ist um Histone gewickelt, die eine wichtige Rolle bei der Regulierung der Genexpression spielen, daher muss die replizierte DNA an denselben Stellen wie die ursprüngliche DNA um Histone gewickelt werden. Um dies zu gewährleisten, zerlegen Histon-Chaperone das Chromatin vor der Replikation und ersetzen die Histone an der richtigen Stelle. Einige Schritte in diesem Zusammenbau sind etwas spekulativ.[33]
Klammerproteine bilden eine gleitende Klammer um die DNA, die der DNA-Polymerase hilft, den Kontakt mit ihrer Matrize aufrechtzuerhalten, wodurch die Prozessivität unterstützt wird. Durch die Innenseite der Klemme kann DNA hindurchgefädelt werden. Sobald die Polymerase das Ende der Matrize erreicht oder doppelsträngige DNA erkennt, durchläuft die Gleitklemme eine Konformationsänderung, die die DNA-Polymerase freisetzt. Clamp-ladende Proteine werden verwendet, um die Clamp anfänglich zu laden und die Verbindung zwischen Template und RNA-Primern zu erkennen.[6]:274-5
DNA-Replikationsproteine[edit]
An der Replikationsgabel fügen sich viele Replikationsenzyme auf der DNA zu einer komplexen molekularen Maschine zusammen, die als Replisom bezeichnet wird. Im Folgenden finden Sie eine Liste der wichtigsten DNA-Replikationsenzyme, die am Replisom beteiligt sind:[34]
| Enzym | Funktion bei der DNA-Replikation |
|---|---|
| DNA-Helikase | Auch als helix-destabilisierendes Enzym bekannt. Helicase trennt die beiden DNA-Stränge an der Replikationsgabel hinter der Topoisomerase. |
| DNA-Polymerase | Das Enzym, das während der DNA-Replikation für die Katalyse der Addition von Nukleotidsubstraten an die DNA in der Richtung von 5′ nach 3′ verantwortlich ist. Führt auch Korrekturlesen und Fehlerkorrekturen durch. Es gibt viele verschiedene Arten von DNA-Polymerase, von denen jede unterschiedliche Funktionen in verschiedenen Zelltypen erfüllt. |
| DNA-Klemme | Ein Protein, das verhindert, dass sich verlängernde DNA-Polymerasen vom DNA-Elternstrang dissoziieren. |
| Einzelstrang-DNA-bindendes Protein | Binden Sie an ssDNA und verhindern Sie, dass die DNA-Doppelhelix erneut anlagert, nachdem die DNA-Helikase sie abgewickelt hat, wodurch die Strangtrennung aufrechterhalten und die Synthese des neuen Strangs erleichtert wird. |
| Topoisomerase | Entspannt die DNA von ihrer supergewundenen Natur. |
| DNA-Gyrase | Entlastet das Abwickeln durch DNA-Helikase; Dies ist eine spezielle Art von Topoisomerase |
| DNA-Ligase | Re-annealt die halbkonservativen Stränge und verbindet Okazaki-Fragmente des nacheilenden Strangs. |
| Primas | Bietet einen Ausgangspunkt für RNA (oder DNA) für die DNA-Polymerase, um mit der Synthese des neuen DNA-Strangs zu beginnen. |
| Telomerase | Verlängert telomere DNA durch Hinzufügen repetitiver Nukleotidsequenzen an den Enden von eukaryotische Chromosomen. Dadurch können Keimzellen und Stammzellen die Hayflick-Grenze der Zellteilung umgehen.[35] |
Replikationsmaschinen[edit]

Replikationsmaschinen bestehen aus Faktoren, die an der DNA-Replikation beteiligt sind und auf Template-ssDNAs erscheinen. Replikationsmaschinen umfassen Primosotoren sind Replikationsenzyme; DNA-Polymerase, DNA-Helikasen, DNA-Klemmen und DNA-Topoisomerasen und Replikationsproteine; zB einzelsträngige DNA-bindende Proteine (SSB). In den Replikationsmaschinen koordinieren sich diese Komponenten. Bei den meisten Bakterien befinden sich alle an der DNA-Replikation beteiligten Faktoren auf Replikationsgabeln und die Komplexe bleiben während der DNA-Replikation auf den Gabeln. Diese Replikationsmaschinen heißen Antworten oder DNA-Replicase-Systeme. Diese Begriffe sind Oberbegriffe für Proteine, die sich auf Replikationsgabeln befinden. In eukaryontischen und einigen Bakterienzellen werden die Replisomen nicht gebildet.
Da sich Replikationsmaschinen nicht relativ zu Template-DNAs wie Fabriken bewegen, werden sie als a . bezeichnet Replikationsfabrik.[36] In einer alternativen Figur ähneln DNA-Fabriken Projektoren und DNAs sind wie Kinofilme, die ständig in die Projektoren laufen. Im Replikationsfabrikmodell laufen die Helikasen entlang der DNAs ineinander, nachdem sowohl DNA-Helikasen für führende Stränge als auch für nachlaufende Stränge auf die Template-DNAs geladen wurden. Die Helikasen bleiben für den Rest des Replikationsprozesses assoziiert. Peter Meisteret al. beobachteten direkt Replikationsstellen in knospenden Hefen, indem sie grün fluoreszierende Protein (GFP)-markierte DNA-Polymerasen &agr; Sie entdeckten die DNA-Replikation von Paaren der markierten Loci, die symmetrisch von einem Replikationsstartpunkt beabstandet waren, und stellten fest, dass der Abstand zwischen den Paaren mit der Zeit deutlich abnahm.[37] Dieser Befund legt nahe, dass der Mechanismus der DNA-Replikation mit DNA-Fabriken zusammenhängt. Das heißt, Paare von Replikationsfabriken werden auf Replikationsursprünge und die miteinander verbundenen Fabriken geladen. Außerdem wandern Matrizen-DNAs in die Fabriken, was die Extrusion der Matrizen-ssDNAs und neue DNAs mit sich bringt. Meisters Entdeckung ist der erste direkte Beweis für das Replikationsfabrikmodell. Nachfolgende Forschungen haben gezeigt, dass DNA-Helikasen in vielen eukaryontischen Zellen Dimere bilden und bakterielle Replikationsmaschinen während der DNA-Synthese an einer einzigen intranuklearen Stelle verbleiben.[36]
Die Replikationsfabriken führen die Entflechtung von Schwesterchromatiden durch. Die Entflechtung ist essentiell für die Verteilung der Chromatiden in Tochterzellen nach der DNA-Replikation. Denn Schwesterchromatiden halten sich nach der DNA-Replikation aneinander fest Kohäsin Ringe gibt es die einzige Chance für die Entflechtung bei der DNA-Replikation. Die Fixierung von Replikationsmaschinen als Replikationsfabriken kann die Erfolgsrate der DNA-Replikation verbessern. Wenn sich Replikationsgabeln in den Chromosomen frei bewegen, wird die Verkettung der Kerne erschwert und behindert die mitotische Segregation.[37]
Beendigung[edit]
Eukaryoten initiieren die DNA-Replikation an mehreren Punkten im Chromosom, so dass sich Replikationsgabeln an vielen Punkten im Chromosom treffen und enden. Da Eukaryoten lineare Chromosomen haben, kann die DNA-Replikation nicht das äußerste Ende der Chromosomen erreichen. Aufgrund dieses Problems geht DNA in jedem Replikationszyklus ab dem Ende des Chromosoms verloren. Telomere sind Regionen repetitiver DNA in der Nähe der Enden und tragen dazu bei, den Verlust von Genen aufgrund dieser Verkürzung zu verhindern. Die Verkürzung der Telomere ist ein normaler Vorgang in Körperzellen. Dadurch werden die Telomere des Tochter-DNA-Chromosoms verkürzt. Dadurch können sich Zellen nur eine bestimmte Anzahl von Malen teilen, bevor der DNA-Verlust eine weitere Teilung verhindert. (Dies ist als Hayflick-Limit bekannt.) Innerhalb der Keimzelllinie, die die DNA an die nächste Generation weitergibt, verlängert die Telomerase die repetitiven Sequenzen der Telomerregion, um einen Abbau zu verhindern. Telomerase kann in Körperzellen fälschlicherweise aktiv werden, was manchmal zur Bildung von Krebs führt. Eine erhöhte Telomeraseaktivität ist eines der Kennzeichen von Krebs.
Die Terminierung erfordert, dass der Fortschritt der DNA-Replikationsgabel gestoppt oder blockiert werden muss. Termination an einem spezifischen Locus, wenn sie auftritt, beinhaltet die Wechselwirkung zwischen zwei Komponenten: (1) einer Terminationsstellensequenz in der DNA und (2) einem Protein, das an diese Sequenz bindet, um die DNA-Replikation physikalisch zu stoppen. Bei verschiedenen Bakterienarten wird dies als DNA-Replikationsterminus-Bindungsprotein oder Ter-Protein bezeichnet.
Da Bakterien kreisförmige Chromosomen haben, tritt die Beendigung der Replikation auf, wenn die beiden Replikationsgabeln am gegenüberliegenden Ende des Elternchromosoms aufeinandertreffen. E coli reguliert diesen Prozess durch die Verwendung von Terminationssequenzen, die, wenn sie vom Tus-Protein gebunden werden, nur eine Richtung der Replikationsgabel passieren lassen. Als Ergebnis sind die Replikationsgabeln darauf beschränkt, sich immer innerhalb der Terminationsregion des Chromosoms zu treffen.[38]
Verordnung[edit]

Eukaryoten[edit]
Bei Eukaryoten wird die DNA-Replikation im Rahmen des Zellzyklus gesteuert. Während die Zelle wächst und sich teilt, durchläuft sie Stadien im Zellzyklus; Die DNA-Replikation findet während der S-Phase (Synthesephase) statt. Der Fortschritt der eukaryontischen Zelle durch den Zyklus wird durch Zellzyklus-Checkpoints kontrolliert. Das Fortschreiten durch Checkpoints wird durch komplexe Interaktionen zwischen verschiedenen Proteinen, einschließlich Cyclinen und cyclinabhängigen Kinasen, kontrolliert.[39] Im Gegensatz zu Bakterien repliziert eukaryotische DNA in den Grenzen des Zellkerns.[40]
Der G1/S-Checkpoint (oder Restriktions-Checkpoint) regelt, ob eukaryotische Zellen in den Prozess der DNA-Replikation und anschließenden Teilung eintreten. Zellen, die diesen Kontrollpunkt nicht passieren, bleiben im G0-Stadium und replizieren ihre DNA nicht.
Nach dem Passieren des G1/S-Checkpoints darf die DNA in jedem Zellzyklus nur einmal repliziert werden. Wenn sich der Mcm-Komplex vom Ursprung entfernt, wird der Präreplikationskomplex abgebaut. Da ein neuer Mcm-Komplex nicht an einem Ursprung geladen werden kann, bis die Prä-Replikations-Untereinheiten reaktiviert sind, kann ein Replikationsursprung nicht zweimal im gleichen Zellzyklus verwendet werden.[21]
Die Aktivierung von S-Cdks in der frühen S-Phase fördert die Zerstörung oder Hemmung einzelner Komponenten des Prä-Replikationskomplexes, wodurch ein sofortiger Wiederzusammenbau verhindert wird. S- und M-Cdks blockieren auch nach Abschluss der S-Phase weiterhin den Zusammenbau des Prä-Replikationskomplexes, wodurch sichergestellt wird, dass der Zusammenbau nicht erneut stattfinden kann, bis die gesamte Cdk-Aktivität in der späten Mitose reduziert ist.[21]
In knospenden Hefen wird die Hemmung des Zusammenbaus durch Cdk-abhängige Phosphorylierung von Komponenten des Prä-Replikationskomplexes verursacht. Zu Beginn der S-Phase bewirkt die Phosphorylierung von Cdc6 durch Cdk1 die Bindung von Cdc6 an die SCF-Ubiquitin-Proteinligase, die eine proteolytische Zerstörung von Cdc6 verursacht. Die Cdk-abhängige Phosphorylierung von Mcm-Proteinen fördert ihren Export aus dem Zellkern zusammen mit Cdt1 während der S-Phase und verhindert so das Laden neuer Mcm-Komplexe am Ursprung während eines einzelnen Zellzyklus. Die Cdk-Phosphorylierung des Ursprungs-Replikationskomplexes hemmt auch den Zusammenbau des Prä-Replikationskomplexes. Das individuelle Vorliegen eines dieser drei Mechanismen reicht aus, um den Zusammenbau des Präreplikationskomplexes zu hemmen. Mutationen aller drei Proteine in derselben Zelle lösen jedoch eine Neuinitiierung an vielen Replikationsursprüngen innerhalb eines Zellzyklus aus.[21][41]
In tierischen Zellen ist das Protein Geminin ein wichtiger Inhibitor des Zusammenbaus des Prä-Replikationskomplexes. Geminin bindet Cdt1, verhindert seine Bindung an den Ursprungserkennungskomplex. In G1 werden die Geminin-Spiegel durch die APC niedrig gehalten, die Geminin ubiquitiniert, um es gezielt abzubauen. Wenn Geminin zerstört wird, wird Cdt1 freigesetzt, wodurch es beim Zusammenbau des Prä-Replikationskomplexes funktionieren kann. Am Ende von G1 wird die APC inaktiviert, wodurch Geminin akkumulieren und Cdt1 binden kann.[21]
Die Replikation von Chloroplasten- und Mitochondriengenomen erfolgt unabhängig vom Zellzyklus durch den Prozess der D-Loop-Replikation.
Replikationsfokus[edit]
In Wirbeltierzellen konzentrieren sich Replikationsstellen an Positionen, die als bezeichnet werden Replikationsfokus.[37] Replikationsstellen können durch Immunfärbung von Tochtersträngen und Replikationsenzymen und Überwachung von GFP-markierten Replikationsfaktoren nachgewiesen werden. Durch diese Verfahren wird festgestellt, dass Replikationsherde unterschiedlicher Größe und Position in der S-Phase der Zellteilung auftreten und ihre Anzahl pro Kern viel kleiner ist als die Anzahl der genomischen Replikationsgabeln.
P. Heunet al.,[37](2001) verfolgten GFP-markierte Replikationsherde in knospenden Hefezellen und zeigten, dass sich die Replikationsursprünge in der G1- und S-Phase ständig bewegen und die Dynamik in der S-Phase signifikant abnahm.[37] Traditionell wurden Replikationsstellen auf der räumlichen Struktur von Chromosomen durch Kernmatrix oder Lamins fixiert. Die Ergebnisse von Heun widerlegten die traditionellen Konzepte, knospende Hefen haben keine Lamins und unterstützen, dass sich Replikationsursprünge selbst zusammensetzen und Replikationsherde bilden.
Durch räumlich und zeitlich kontrolliertes Brennen von Replikationsstartpunkten wird die Bildung von Replikationsherden reguliert. DA Jackson et al. (1998) zeigten, dass benachbarte Ursprünge gleichzeitig in Säugerzellen feuern.[37] Die räumliche Gegenüberstellung von Replikationsstellen bringt Clusterbildung von Replikationsgabeln. Das Clustering macht Rettung von blockierten Replikationsgabeln und begünstigt den normalen Verlauf der Replikationsgabeln. Der Fortschritt von Replikationsgabeln wird durch viele Faktoren gehemmt; Kollision mit Proteinen oder mit Komplexen, die stark an DNA binden, Mangel an dNTPs, Nicks an Template-DNAs und so weiter. Wenn Replikationsgabeln stehen bleiben und die verbleibenden Sequenzen von den blockierten Gabeln nicht repliziert werden, haben die Tochterstränge nick erhaltene nicht replizierte Stellen. Die nicht replizierten Stellen am Strang eines Elternteils halten den anderen Strang zusammen, aber keine Tochterstränge. Daher können sich die resultierenden Schwesterchromatiden nicht voneinander trennen und sich nicht in 2 Tochterzellen teilen. Wenn benachbarte Ursprünge feuern und eine Abzweigung von einem Ursprung angehalten wird, greift die Abzweigung von einem anderen Ursprung auf eine entgegengesetzte Richtung der blockierten Abzweigung zu und dupliziert die nicht replizierten Sites. Als anderer Mechanismus der Rettung gibt es die Anwendung von ruhende Replikationsursprünge dass überschüssige Ursprünge bei der normalen DNA-Replikation nicht feuern.
Bakterien[edit]
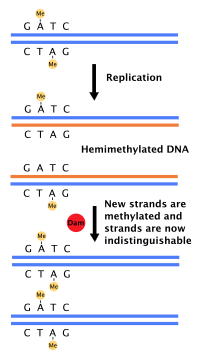
Die meisten Bakterien durchlaufen keinen genau definierten Zellzyklus, sondern kopieren ihre DNA kontinuierlich; während des schnellen Wachstums kann dies zum gleichzeitigen Auftreten mehrerer Replikationsrunden führen.[42] In E coli, den am besten charakterisierten Bakterien, wird die DNA-Replikation durch mehrere Mechanismen reguliert, darunter: die Hemimethylierung und Sequestrierung der Ursprungssequenz, das Verhältnis von Adenosintriphosphat (ATP) zu Adenosindiphosphat (ADP) und die Protein-DnaA-Spiegel. All diese steuern die Bindung von Initiatorproteinen an die Ursprungssequenzen.
Weil E coli methyliert GATC-DNA-Sequenzen, führt die DNA-Synthese zu hemimethylierten Sequenzen. Diese hemimethylierte DNA wird vom Protein SeqA erkannt, das die Ursprungssequenz bindet und maskiert; außerdem bindet DnaA (benötigt für den Start der Replikation) weniger gut an hemimethylierte DNA. Als Ergebnis werden neu replizierte Ursprünge daran gehindert, sofort eine weitere Runde der DNA-Replikation einzuleiten.[43]
ATP baut sich auf, wenn sich die Zelle in einem reichen Medium befindet und löst die DNA-Replikation aus, sobald die Zelle eine bestimmte Größe erreicht hat. ATP konkurriert mit ADP um die Bindung an DnaA, und der DnaA-ATP-Komplex ist in der Lage, die Replikation zu initiieren. Eine bestimmte Anzahl von DnaA-Proteinen wird auch für die DNA-Replikation benötigt – jedes Mal, wenn der Ursprung kopiert wird, verdoppelt sich die Anzahl der Bindungsstellen für DnaA, was die Synthese von mehr DnaA erfordert, um eine weitere Replikation zu ermöglichen.
Bei schnell wachsenden Bakterien, wie z E coli, dauert die Chromosomenreplikation länger als die Zellteilung. Die Bakterien lösen dies, indem sie eine neue Replikationsrunde einleiten, bevor die vorherige beendet wurde.[44] Die neue Replikationsrunde bildet das Chromosom der Zelle, die zwei Generationen nach der sich teilenden Zelle geboren wird. Dieser Mechanismus erzeugt überlappende Replikationszyklen.
Probleme mit der DNA-Replikation[edit]
|
Diese Abteilung braucht Erweiterung. Sie können helfen, indem Sie es ergänzen. (Mai 2020)
|
Es gibt viele Ereignisse, die zu Replikationsstress beitragen, darunter:[45]
Polymerase Kettenreaktion[edit]
Forscher replizieren häufig DNA in vitro unter Verwendung der Polymerase-Kettenreaktion (PCR). Die PCR verwendet ein Primerpaar, um eine Zielregion in der Template-DNA zu überspannen, und polymerisiert dann Partnerstränge in jede Richtung von diesen Primern unter Verwendung einer thermostabilen DNA-Polymerase. Die Wiederholung dieses Prozesses über mehrere Zyklen amplifiziert die Ziel-DNA-Region. Zu Beginn jedes Zyklus wird die Mischung aus Matrize und Primern erhitzt, wodurch das neu synthetisierte Molekül und die Matrize getrennt werden. Dann, wenn die Mischung abkühlt, werden beide zu Matrizen für das Annealing neuer Primer, und die Polymerase erstreckt sich von diesen. Infolgedessen verdoppelt sich die Anzahl der Kopien der Zielregion jede Runde und steigt exponentiell an.[46]
Siehe auch[edit]
- ^ Die Energetik dieses Prozesses kann auch helfen, die Richtung der Synthese zu erklären – würde die DNA in 3′- bis 5′-Richtung synthetisiert, würde die Energie für den Prozess eher vom 5′-Ende des wachsenden Strangs als von freien Nukleotiden kommen. Das Problem ist, dass wenn die hochenergetischen Triphosphate auf dem wachsenden Strang und nicht auf den freien Nukleotiden wären, ein Korrekturlesen durch Entfernen eines nicht übereinstimmenden terminalen Nukleotids problematisch wäre: Sobald ein Nukleotid hinzugefügt wird, geht das Triphosphat verloren und ein einzelnes Phosphat bleibt an das Rückgrat zwischen dem neuen Nukleotid und dem Rest des Strangs. Wenn das hinzugefügte Nukleotid fehlgepaart wäre, würde die Entfernung zu einem DNA-Strang führen, der durch ein Monophosphat am Ende des “wachsenden Strangs” anstelle eines hochenergetischen Triphosphats endet. Der Strang würde also stecken bleiben und nicht mehr wachsen können. Tatsächlich stammen die bei jedem Schritt hydrolysierten hochenergetischen Triphosphate von den freien Nukleotiden, nicht vom polymerisierten Strang, so dass dieses Problem nicht besteht.
Verweise[edit]
- ^ “DNA-Replikation | Warum müssen wir die DNA-Replikation studieren?”. Leben der Mikroben. 2020-05-25. Abgerufen 2020-05-29.
- ^ “GENETIK / DNA REPLIKATION (BASIC) – Pathwayz”. www.pathwayz.org. Abgerufen 2020-12-10.
- ^ “Doppelhelix | Lernen Sie Wissenschaft bei Scitable”. www.natur.com. Abgerufen 2020-12-10.
- ^ Bete LA. “Semi-konservative DNA-Replikation; Meselson und Stahl”.
- ^ Eine unvollständige DNA-Replikation führt zu Mutationen. Berg JM, Tymoczko JL, Stryer L, Clarke ND (2002). “Kapitel 27: DNA-Replikation, Rekombination und Reparatur”. Biochemie. WH Freeman und Company. ISBN 0-7167-3051-0. Archiviert von das Original am 26.03.2020. Abgerufen 2019-08-09.
- ^ ein B H. Lodish, A. Berk, SL Zipursky et al. (2000). “DNA-Replikation, Reparatur und Rekombination”. Molekulare Zellbiologie (4. Aufl.). WH Freeman. ISBN 0-7167-3136-3.
- ^ ein B Berg JM, Tymoczko JL, Stryer L, Clarke ND (2002). “Kapitel 27, Abschnitt 4: DNA-Replikation beider Stränge schreitet schnell von bestimmten Startstellen fort”. Biochemie. WH Freeman und Company. ISBN 0-7167-3051-0. Archiviert von das Original am 26.03.2020. Abgerufen 2019-08-09.
- ^ “Was ist ein Genom?”. dein Genom. Abgerufen 2020-12-10.
- ^ Kühnlein, Alexandra; Lanzmich, Simon A.; Brun, Dieter (2. März 2021). “tRNA-Sequenzen können sich zu einem Replikator zusammenfügen”. eLife. mach:10.7554/eLife.63431. Abgerufen 3. April 2021.
- ^ Maximilian, Ludwig (3. April 2021). „Das Huhn-und-Ei-Problem lösen – „Ein Schritt näher an der Rekonstruktion des Ursprungs des Lebens““. SciTechTäglich. Abgerufen 3. April 2021.
- ^ “DNA Funktion & Struktur (mit Diagramm) (Artikel)”. Khan Akademie. Abgerufen 2020-12-10.
- ^ Alberts B. et al. (2002). Molekularbiologie der Zelle (4. Aufl.). Girlande Wissenschaft. S. 238–240. ISBN 0-8153-3218-1.
- ^ Allison LA (2007). Grundlegende Molekularbiologie. Blackwell-Publishing. P. 112. ISBN 978-1-4051-0379-4.
- ^ Berg JM, Tymoczko JL, Stryer L, Clarke ND (2002). Biochemie. WH Freeman und Company. ISBN 0-7167-3051-0. Kapitel 27, Abschnitt 2: DNA-Polymerasen benötigen ein Templat und einen Primer
- ^ ein B McCulloch SD, Kunkel TA (Januar 2008). “Die Genauigkeit der DNA-Synthese durch eukaryotische Replikations- und Transläsionssynthese-Polymerasen”. Zellforschung. 18 (1): 148–61. mach:10.1038/cr.2008.4. PMC 3639319. PMID 18166979.
- ^ McCarthy D, Minner C, Bernstein H, Bernstein C (Oktober 1976). „DNA-Elongationsraten und Wachstumspunktverteilungen von Wildtyp-Phagen T4 und einer DNA-Verzögerungs-Amber-Mutante“. Zeitschrift für Molekularbiologie. 106 (4): 963–81. mach:10.1016/0022-2836(76)90346-6. PMID 789903.
- ^ Drake Zeuge Jehovas (1970) Die molekulare Basis der Mutation. Holden-Tag, San Francisco ISBN 0816224501 ISBN 978-0816224500
- ^ Alberts B, Johnson A, Lewis J, Raff M, Roberts K, Walter P (2002). Molekularbiologie der Zelle. Girlande Wissenschaft. ISBN 0-8153-3218-1. Kapitel 5: DNA-Replikationsmechanismen
- ^ Weigel C, Schmidt A, Rückert B, Lurz R, Messer W (November 1997). “DnaA-Proteinbindung an einzelne DnaA-Boxen im Escherichia coli-Replikationsursprung, oriC”. Das EMBO-Journal. 16 (21): 6574–83. mach:10.1093/emboj/16.21.6574. PMC 1170261. PMID 9351837.
- ^ Lodish H, Berk A, Zipursky LS, Matsudaira P, Baltimore D, Darnell J (2000). Molekulare Zellbiologie. WH Freeman und Company. ISBN 0-7167-3136-3.12.1. Allgemeine Merkmale der chromosomalen Replikation: Drei gemeinsame Merkmale der Replikationsursprünge
- ^ ein B C D e F g h ich Morgan DO (2007). Der Zellzyklus: Prinzipien der Kontrolle. London: Neue Wissenschaftspresse. S. 64–75. ISBN 978-0-19-920610-0. OCLC 70173205.
- ^ Donaldson AD, Raghuraman MK, Friedman KL, Cross FR, Brewer BJ, Fangman WL (August 1998). “CLB5-abhängige Aktivierung von späten Replikationsursprüngen in S. cerevisiae”. Molekulare Zelle. 2 (2): 173–82. mach:10.1016/s1097-2765(00)80127-6. PMID 9734354.
- ^ Aravind L, Leipe DD, Koonin EV (September 1998). „Toprim – eine konservierte katalytische Domäne in Topoisomerasen vom Typ IA und II, Primasen vom DnaG-Typ, Nukleasen der OLD-Familie und RecR-Proteinen“. Nukleinsäureforschung. 26 (18): 4205–13. mach:10.1093/nar/26.18.4205. PMC 147817. PMID 9722641.
- ^ Frick DN, Richardson CC (Juli 2001). „DNA-Primas“. Jahresrückblick Biochemie. 70: 39–80. mach:10.1146/annurev.biochem.70.1.39. PMID 11395402. S2CID 33197061.
- ^ Barry ER, Bell SD (Dezember 2006). “DNA-Replikation in den Archaeen”. Mikrobiologie und Molekularbiologie Bewertungen. 70 (4): 876–87. mach:10.1128/MMBR.00029-06. PMC 1698513. PMID 17158702.
- ^ Stillman B (Juli 2015). “Überdenken von DNA-Polymerasen an der Replikationsgabel in Eukaryoten”. Molekulare Zelle. 59 (2): 139–41. mach:10.1016/j.molcel.2015.07.004. PMC 4636199. PMID 26186286.
- ^ Rossi ML (Februar 2009). Unterscheidung der Wege der Primerentfernung während der Reifung des eukaryotischen Okazaki-Fragments (Doktorarbeit). Fakultät für Medizin und Zahnmedizin, University of Rochester. hdl:1802/6537.
- ^ Huberman JA, Riggs AD (März 1968). „Über den Mechanismus der DNA-Replikation in Säugetierchromosomen“. Zeitschrift für Molekularbiologie. 32 (2): 327–41. mach:10.1016/0022-2836(68)90013-2. PMID 5689363.
- ^ Y. Gao, Y. Cui, T. Fox, S. Lin, H. Wang, N. de Val et al. (Februar 2019). “Strukturen und Funktionsprinzipien des Replisoms”. Wissenschaft. 363 (6429): 835. doi:10.1126/science.aav7003. PMC 6681829. PMID 30679383.
- ^ Alberts B, Johnson A, Lewis J, Raff M, Roberts K, Walter P (2002). Molekularbiologie der Zelle. Girlande Wissenschaft. ISBN 0-8153-3218-1. DNA-Replikationsmechanismen: DNA-Topoisomerasen verhindern das Verheddern der DNA während der Replikation
- ^ Reece RJ, Maxwell A (26. September 2008). „DNA-Gyrase: Struktur und Funktion“. Kritische Reviews in Biochemie und Molekularbiologie. 26 (3–4): 335–75. mach:10.3109/10409239109114072. PMID 1657531.
- ^ Alberts B, Johnson A, Lewis J, Raff M, Roberts K, Walter P (2002). Molekularbiologie der Zelle. Girlande Wissenschaft. ISBN 0-8153-3218-1. DNA-Replikationsmechanismen: Spezielle Proteine helfen, die DNA-Doppelhelix vor der Replikationsgabel zu öffnen
- ^ Lösegeld M, Dennehey B, Tyler JK (22. Januar 2010). “Histone während der DNA-Replikation und -Reparatur begleiten”. Zelle. 140 (2): 183-195. mach:10.1016/j.cell.2010.01.004. PMC 3433953. PMID 20141833.
- ^ Griffiths AJ, Wessler SR, Lewontin RC, Carroll SB (2008). Einführung in die genetische Analyse. WH Freeman und Company. ISBN 978-0-7167-6887-6.[Chapter 7: DNA: Structure and Replication. pg 283–290]
- ^ “Wird das Hayflick-Limit uns davon abhalten, ewig zu leben?”. Wie Dinge funktionieren. 2009-05-11. Abgerufen 20. Januar 2015.
- ^ ein B James D. Watsonet al. (2008), “Molekularbiologie des Gens”, Pearson Education: 237
- ^ ein B C D e F Peter Meister, Angela Taddei1, Susan M. Gasser (Juni 2006), “In und aus der Replikationsfabrik”, Zelle 125 (7): 1233–1235
- ^ Brown TA (2002). Genome. BIOS Scientific Publishers. ISBN 1-85996-228-9.13.2.3. Beendigung der Replikation
- ^ Alberts B, Johnson A, Lewis J, Raff M, Roberts K, Walter P (2002). Molekularbiologie der Zelle. Girlande Wissenschaft. ISBN 0-8153-3218-1. Intrazelluläre Kontrolle von Zellzyklusereignissen: S-Phase-Cyclin-Cdk-Komplexe (S-Cdks) initiieren die DNA-Replikation einmal pro Zyklus
- ^ Brown TA (2002). “13”. Genome (2. Aufl.). Oxford: Wiley-Liss.
- ^ Nguyen VQ, Co C, Li JJ (Juni 2001). „Cyclin-abhängige Kinasen verhindern die DNA-Replikation durch mehrere Mechanismen“. Natur. 411 (6841): 1068–73. Bibcode:2001Natur.411.1068N. mach:10.1038/35082600. PMID 11429609. S2CID 4393812.
- ^ Tobiason DM, Seifert HS (Juni 2006). “Der obligate Humanpathogen Neisseria gonorrhoeae ist polyploid”. PLOS Biologie. 4 (6): e185. mach:10.1371/journal.pbio.0040185. PMC 1470461. PMID 16719561.
- ^ Slater S, Wold S, Lu M, Boye E, Skarstad K, Kleckner N (September 1995). “E. coli SeqA-Protein bindet oriC in zwei verschiedenen Methyl-modulierten Reaktionen, die seiner Rolle bei der DNA-Replikationsinitiation und der Ursprungssequestrierung entsprechen”. Zelle. 82 (6): 927–36. mach:10.1016/0092-8674(95)90272-4. PMID 7553853. S2CID 14652024.
- ^ Cooper S, Helmstetter CE (Februar 1968). „Chromosomenreplikation und der Teilungszyklus von Escherichia coli B/r“. Zeitschrift für Molekularbiologie. 31 (3): 519–40. mach:10.1016/0022-2836(68)90425-7. PMID 4866337.
- ^ Zeman MK, Cimprich KA (Januar 2014). “Ursachen und Folgen von Replikationsstress”. Natur Zellbiologie. 16 (1): 2–9. mach:10.1038/ncb2897. PMC 4354890. PMID 24366029.
- ^ Saiki RK, Gelfand DH, Stoffel S, Scharf SJ, Higuchi R, Horn GT, et al. (Januar 1988). “Primer-gerichtete enzymatische Amplifikation von DNA mit einer thermostabilen DNA-Polymerase”. Wissenschaft. 239 (4839): 487–91. Bibcode:1988Sc…239..487S. mach:10.1126/science.239.4839.487. PMID 2448875.
Recent Comments