Disjunkte Datenstruktur – Wikipedia

MakeSet erzeugt 8 Singletons.Union, einige Sätze werden zusammen gruppiert.In der Informatik, u disjunkte Datenstruktur, auch a . genannt union–Datenstruktur finden oder Zusammenführen–Suchen-Set, ist eine Datenstruktur, die eine Sammlung von disjunkten (nicht überlappenden) Mengen speichert. Äquivalent speichert es eine Partition einer Menge in disjunkte Teilmengen. Es bietet Operationen zum Hinzufügen neuer Mengen, zum Zusammenführen von Mengen (ersetzen durch ihre Vereinigung) und zum Finden eines repräsentativen Mitglieds einer Menge. Die letzte Operation ermöglicht es, effizient herauszufinden, ob sich zwei Elemente in denselben oder unterschiedlichen Mengen befinden.
Obwohl es mehrere Möglichkeiten gibt, disjunkte Datenstrukturen zu implementieren, werden sie in der Praxis oft mit einer bestimmten Implementierung namens a . identifiziert disjunkter Wald. Dies ist ein spezialisierter Waldtyp, der Vereinigungen und Funde in nahezu konstanter amortisierter Zeit durchführt. Um eine Sequenz von . auszuführen m Additions-, Vereinigungs- oder Suchoperationen in einer disjunkten Gesamtstruktur mit n Knoten benötigt Gesamtzeit Ö(mα(n)), wo α(n) ist die extrem langsam wachsende inverse Ackermann-Funktion. Disjunkte Gesamtstrukturen garantieren diese Leistung nicht pro Vorgang. Einzelne Vereinigungs- und Suchvorgänge können länger als eine konstante Zeit dauern α(n) Zeit, aber jede Operation bewirkt, dass sich die Gesamtstruktur der disjunkten Menge selbst anpasst, sodass aufeinanderfolgende Operationen schneller sind. Disjunkte Wälder sind sowohl asymptotisch optimal als auch praktisch effizient.
Datenstrukturen mit disjunkten Mengen spielen eine Schlüsselrolle in Kruskals Algorithmus zum Auffinden des minimalen Spannbaums eines Graphen. Die Bedeutung von minimalen Spannbäumen bedeutet, dass disjunkte Datenstrukturen einer Vielzahl von Algorithmen zugrunde liegen. Darüber hinaus haben disjunkte Datenstrukturen auch Anwendungen für symbolische Berechnungen sowie in Compilern, insbesondere für Registerzuordnungsprobleme.
Geschichte[edit]
Disjunkte Wälder wurden erstmals 1964 von Bernard A. Galler und Michael J. Fischer beschrieben.[2] 1973 war ihre zeitliche Komplexität begrenzt auf
Ö(Protokoll*(n)){displaystyle O(log^{*}(n))}, der iterierte Logarithmus von


, von Hopcroft und Ullman.[3] 1975 bewies Robert Tarjan als erster die
Ö(mα(n)){displaystyle O(malpha(n))}

(inverse Ackermann-Funktion) obere Schranke der Zeitkomplexität des Algorithmus,[4] und zeigte 1979, dass dies die untere Grenze für einen eingeschränkten Fall war.[5] Das haben Fredman und Saks 1989 gezeigt
Ω(α(n)){displaystyle Omega (alpha (n))}

(amortisierte) Wörter müssen abgerufen werden durch irgendein disjunkte Datenstruktur pro Operation,[6] Damit wird die Optimalität der Datenstruktur bewiesen.


1991 veröffentlichten Galil und Italiano eine Übersicht über Datenstrukturen für disjunkte Mengen.[7]
1994 beschrieben Richard J. Anderson und Heather Woll eine parallelisierte Version von Union-Find, die niemals blockiert werden muss.[8]
2007 entwickelten Sylvain Conchon und Jean-Christophe Filliâtre eine persistente Version der disjunkten Walddatenstruktur, die eine effiziente Beibehaltung früherer Versionen der Struktur ermöglichte, und formalisierten ihre Korrektheit mit dem Beweisassistenten Coq.[9] Die Implementierung ist jedoch nur asymptotisch, wenn sie ephemer verwendet wird oder wenn dieselbe Version der Struktur wiederholt mit begrenztem Backtracking verwendet wird.
Darstellung[edit]
Jeder Knoten in einem Wald mit disjunkter Menge besteht aus einem Zeiger und einigen Hilfsinformationen, entweder einer Größe oder einem Rang (aber nicht beides). Die Zeiger werden verwendet, um übergeordnete Zeigerbäume zu erstellen, wobei jeder Knoten, der nicht die Wurzel eines Baums ist, auf seinen übergeordneten Knoten zeigt. Um Root-Knoten von anderen zu unterscheiden, haben ihre Elternzeiger ungültige Werte, wie z. B. einen zirkulären Verweis auf den Knoten oder einen Sentinel-Wert. Jeder Baum stellt eine im Wald gespeicherte Menge dar, wobei die Mitglieder der Menge die Knoten im Baum sind. Wurzelknoten stellen Mengenrepräsentanten bereit: Zwei Knoten befinden sich genau dann in derselben Menge, wenn die Wurzeln der Bäume, die die Knoten enthalten, gleich sind.
Knoten in der Gesamtstruktur können auf beliebige Weise gespeichert werden, die für die Anwendung geeignet ist, aber eine gängige Technik besteht darin, sie in einem Array zu speichern. In diesem Fall können Eltern durch ihren Array-Index angegeben werden. Jeder Array-Eintrag erfordert Θ(log n) Speicherbits für den Elternzeiger. Für den Rest des Eintrags ist eine vergleichbare oder geringere Speichermenge erforderlich, daher ist die Anzahl der zum Speichern des Waldes erforderlichen Bits (n Protokoll n). Wenn eine Implementierung Knoten fester Größe verwendet (wodurch die maximale Größe des Waldes begrenzt wird, der gespeichert werden kann), ist der erforderliche Speicher linear in n.
Betrieb[edit]
Datenstrukturen mit disjunkten Mengen unterstützen drei Operationen: Erstellen einer neuen Menge, die ein neues Element enthält; Finden des Repräsentanten der Menge, die ein gegebenes Element enthält; und Zusammenführen von zwei Sätzen.
Neue Sets erstellen[edit]
Die MakeSet Operation fügt ein neues Element hinzu. Dieses Element wird in einen neuen Satz platziert, der nur das neue Element enthält, und der neue Satz wird der Datenstruktur hinzugefügt. Wenn die Datenstruktur stattdessen als Teilung einer Menge betrachtet wird, dann ist die MakeSet Die Operation vergrößert die Menge durch Hinzufügen des neuen Elements und erweitert die vorhandene Partition, indem das neue Element in eine neue Untermenge eingefügt wird, die nur das neue Element enthält.
In einem zusammenhanglosen Wald, MakeSet initialisiert den Elternzeiger des Knotens und die Größe oder den Rang des Knotens. Wenn eine Wurzel durch einen Knoten repräsentiert wird, der auf sich selbst zeigt, kann das Hinzufügen eines Elements mit dem folgenden Pseudocode beschrieben werden:
function MakeSet(x) is
if x is not already in the forest then
x.parent := x
x.size := 1 // if nodes store size
x.rank := 0 // if nodes store rank
end if
end function
Diese Operation hat eine konstante Zeitkomplexität. Insbesondere das Initialisieren eines disjunkten Waldes mit n Knoten erfordert Ö(n)
Zeit.
In der Praxis, MakeSet muss eine Operation vorausgehen, die Speicher zuweist, um zu halten x. Solange die Speicherzuweisung ein amortisierter Vorgang mit konstanter Zeit ist, wie es für eine gute dynamische Array-Implementierung der Fall ist, ändert dies nicht die asymptotische Leistung der Zufallsstruktur.
Setvertreter finden[edit]
Die Find Operation folgt der Kette von Elternzeigern von einem angegebenen Abfrageknoten x bis es ein Wurzelelement erreicht. Dieses Wurzelelement stellt die Menge dar, zu der x gehört und kann sein x selbst. Find gibt das erreichte Wurzelelement zurück.
Ausführen von a Find Der Betrieb stellt eine wichtige Chance zur Verbesserung des Waldes dar. Die Zeit in a Find Die Operation wird damit verbracht, übergeordnete Zeiger zu verfolgen, daher führt ein flacherer Baum zu schnelleren Find Operationen. Wenn ein Find ausgeführt wird, gibt es keinen schnelleren Weg, die Wurzel zu erreichen, als jedem Elternzeiger nacheinander zu folgen. Die während dieser Suche besuchten Elternzeiger können jedoch aktualisiert werden, um näher auf die Wurzel zu zeigen. Da jedes Element, das auf dem Weg zu einer Wurzel besucht wird, Teil desselben Sets ist, ändert dies nichts an den im Forest gespeicherten Sets. Aber es macht Zukunft Find Operationen schneller, nicht nur für die Knoten zwischen dem Abfrageknoten und der Wurzel, sondern auch für deren Nachkommen. Diese Aktualisierung ist ein wichtiger Bestandteil der amortisierten Leistungsgarantie der disjunkten Gesamtstruktur.
Es gibt mehrere Algorithmen für Find die die asymptotisch optimale Zeitkomplexität erreichen. Eine Familie von Algorithmen, bekannt als Pfadkomprimierung, lässt jeden Knoten zwischen dem Abfrageknoten und dem Stamm auf den Stamm verweisen. Die Pfadkomprimierung kann mit einer einfachen Rekursion wie folgt implementiert werden:
function Find(x) is
if x.parent ≠ x then
x.parent := Find(x.parent)
return x.parent
else
return x
end if
end function
Diese Implementierung macht zwei Durchgänge, einen den Baum hinauf und einen zurück nach unten. Es erfordert genügend Arbeitsspeicher, um den Pfad vom Abfrageknoten zum Stamm zu speichern (im obigen Pseudocode wird der Pfad implizit unter Verwendung des Aufrufstapels dargestellt). Dies kann auf eine konstante Speichermenge verringert werden, indem beide Durchgänge in die gleiche Richtung ausgeführt werden. Die Konstantenspeicherimplementierung geht zweimal vom Abfrageknoten zum Stamm, einmal, um den Stamm zu finden und einmal, um Zeiger zu aktualisieren:
function Find(x) is
root := x
while root.parent ≠ root do
root := root.parent
end while
while x.parent ≠ root do
parent := x.parent
x.parent := root
x := parent
end while
return root
end function
Tarjan und Van Leeuwen entwickelten auch One-Pass Find Algorithmen, die die gleiche Worst-Case-Komplexität beibehalten, aber in der Praxis effizienter sind.[4] Diese werden Pfadaufspaltung und Pfadhalbierung genannt. Beide aktualisieren die Elternzeiger von Knoten auf dem Pfad zwischen dem Abfrageknoten und der Wurzel. Pfadaufteilung ersetzt jeden Elternzeiger auf diesem Pfad durch einen Zeiger auf den Großelternknoten des Knotens:
function Find(x) is
while x.parent ≠ x do
(x, x.parent) := (x.parent, x.parent.parent)
end while
return x
end function
Weghalbierung funktioniert ähnlich, ersetzt aber nur jeden anderen Elternzeiger:
function Find(x) is
while x.parent ≠ x do
x.parent := x.parent.parent
x := x.parent
end while
return x
end function
Zusammenführen von zwei Sätzen[edit]
Die Operation Union(x, y) ersetzt das Set mit x und das Set enthält ja mit ihrer Vereinigung. Union erste Verwendungen Find um die Wurzeln der Bäume zu bestimmen, die enthalten x und ja. Wenn die Wurzeln gleich sind, gibt es nichts mehr zu tun. Andernfalls müssen die beiden Bäume zusammengeführt werden. Dies geschieht durch Setzen des Elternzeigers von x‘s Wurzel zu ja‘s oder das Setzen des Elternzeigers von ja‘s Wurzel zu x‘S.
Die Wahl, welcher Knoten zum Elternknoten wird, hat Konsequenzen für die Komplexität zukünftiger Operationen auf dem Baum. Wenn es unvorsichtig gemacht wird, können Bäume übermäßig hoch werden. Nehmen wir zum Beispiel an, dass Union habe immer den Baum gemacht, der enthält x ein Unterbaum des Baums, der . enthält ja. Beginnen Sie mit einem Wald, der gerade mit Elementen initialisiert wurde
und ausführen Union(1, 2), Union(2, 3), …, Union(n - 1, n). Der resultierende Wald enthält einen einzelnen Baum, dessen Wurzel ist n, und der Pfad von 1 nach n geht durch jeden Knoten im Baum. Für diesen Wald ist die Zeit zu laufen Find(1) ist Ö(n).


In einer effizienten Implementierung wird die Baumhöhe mit Vereinigung nach Größe oder Vereinigung nach Rang. Beide erfordern, dass ein Knoten neben seinem Elternzeiger auch Informationen speichert. Diese Informationen werden verwendet, um zu entscheiden, welcher Stamm der neue Elternteil wird. Beide Strategien sorgen dafür, dass Bäume nicht zu tief werden.
Bei der Vereinigung nach Größe speichert ein Knoten seine Größe, die einfach die Anzahl der Nachkommen ist (einschließlich des Knotens selbst). Wenn die Bäume mit Wurzeln x und ja zusammengeführt werden, wird der Knoten mit mehr Nachkommen zum übergeordneten Knoten. Wenn die beiden Knoten die gleiche Anzahl von Nachkommen haben, kann jeder zum Elternteil werden. In beiden Fällen wird die Größe des neuen Elternknotens auf seine neue Gesamtzahl der Nachkommen eingestellt.
function Union(x, y) is
// Replace nodes by roots
x := Find(x)
y := Find(y)
if x = y then
return // x and y are already in the same set
end if
// If necessary, rename variables to ensure that
// x has at least as many descendants as y
if x.size < y.size then
(x, y) := (y, x)
end if
// Make x the new root
y.parent := x
// Update the size of x
x.size := x.size + y.size
end function
Die Anzahl der Bits, die zum Speichern der Größe erforderlich sind, ist eindeutig die Anzahl der Bits, die zum Speichern erforderlich sind n. Dies erhöht den Speicherbedarf des Waldes um einen konstanten Faktor.
Für die Vereinigung nach Rang speichert ein Knoten seine Rang, was eine obere Schranke für seine Höhe ist. Wenn ein Knoten initialisiert wird, wird sein Rang auf Null gesetzt. Bäume mit Wurzeln verschmelzen x und ja, vergleichen Sie zuerst ihre Reihen. Wenn die Ränge unterschiedlich sind, wird der größere Rangbaum zum übergeordneten Element, und die Ränge von x und ja Ändere dich nicht. Wenn die Ränge gleich sind, kann jeder zum Elternteil werden, aber der Rang des neuen Elternteils wird um eins erhöht. Während der Rang eines Knotens eindeutig mit seiner Höhe zusammenhängt, ist das Speichern von Rängen effizienter als das Speichern von Höhen. Die Höhe eines Knotens kann sich während a . ändern Find Das Speichern von Reihen vermeidet den zusätzlichen Aufwand, die Höhe korrekt zu halten. Im Pseudocode ist Vereinigung nach Rang:
function Union(x, y) is
// Replace nodes by roots
x := Find(x)
y := Find(y)
if x = y then
return // x and y are already in the same set
end if
// If necessary, rename variables to ensure that
// x has rank at least as large as that of y
if x.rank < y.rank then
(x, y) := (y, x)
end if
// Make x the new root
y.parent := x
// If necessary, increment the rank of x
if x.rank = y.rank then
x.rank := x.rank + 1
end if
end function
Es kann gezeigt werden, dass jeder Knoten einen Rang . hat
IchProtokollnIch{displaystyle lfloor log nrfloor }oder weniger.[10] Folglich kann der Rang gespeichert werden in Ö(Log-Log n) Bits, was ihn zu einem asymptotisch vernachlässigbaren Teil der Waldgröße macht.


Aus den obigen Implementierungen ist klar, dass die Größe und der Rang eines Knotens keine Rolle spielen, es sei denn, ein Knoten ist die Wurzel eines Baums. Sobald ein Knoten ein Kind wird, wird nie wieder auf seine Größe und seinen Rang zugegriffen.
Zeitkomplexität[edit]
Eine disjunkte Waldimplementierung, in der Find Elternzeiger nicht aktualisiert und in denen Union versucht nicht, Baumhöhen zu kontrollieren, kann Bäume mit Höhe haben Ö(n). In einer solchen Situation ist die Find und Union Operationen erfordern Ö(n) Zeit.
Wenn eine Implementierung nur die Pfadkomprimierung verwendet, wird eine Sequenz von n MakeSet Operationen, gefolgt von bis zu n – 1 Union Betrieb und F Find Betrieb, hat eine Worst-Case-Laufzeit von
.[10]


Union nach Rang verwenden, aber ohne Elternzeiger während zu aktualisieren Find, ergibt eine Laufzeit von
zum m Operationen jeglicher Art, bis zu n davon sind MakeSet Operationen.[10]


Die Kombination von Pfadkomprimierung, Teilung oder Halbierung mit Vereinigung nach Größe oder Rang reduziert die Laufzeit für m Operationen jeglicher Art, bis zu n davon sind MakeSet Operationen, zu
.[4][5] Dadurch wird die amortisierte Laufzeit jedes Vorgangs
Θ(α(n)){displaystyle Theta (alpha (n))}

. Dies ist asymptotisch optimal, was bedeutet, dass jede disjunkte Mengendatenstruktur verwenden muss
Ω(α(n)){displaystyle Omega (alpha (n))}

amortisierte Zeit pro Vorgang.[6] Hier ist die Funktion
α(n){displaystylealpha(n)}ist die inverse Ackermann-Funktion. Die inverse Ackermann-Funktion wächst außerordentlich langsam, daher ist dieser Faktor 4 oder weniger für jeden n das kann tatsächlich im physikalischen Universum geschrieben werden. Dies macht disjunkte Mengenoperationen praktisch amortisiert konstante Zeit.


Beweis der O(log*(n)) Zeitkomplexität von Union-Find[edit]
Die genaue Analyse der Leistung eines disjunkten Waldes ist etwas kompliziert. Es gibt jedoch eine viel einfachere Analyse, die beweist, dass die amortisierte Zeit für alle m Find oder Union Operationen auf einem disjunkten Wald mit n Objekte ist Ö(mlog*n), wo Protokoll* bezeichnet den iterierten Logarithmus.[11][12][13][14]
Lemma 1: Wenn die find-Funktion dem Pfad zur Wurzel folgt, steigt der Rang des Knotens, auf den sie trifft.
- Beweis: Behaupten Sie, dass diese Tatsache auch im Laufe der Zeit wahr bleibt, wenn die Operationen Find und Union auf den Datensatz angewendet werden. Wenn jeder Knoten zunächst die Wurzel seines eigenen Baums ist, ist dies trivialerweise wahr. Der einzige Fall, in dem der Rang eines Knotens geändert werden kann, ist, wenn die Operation Union by Rank angewendet wird. In diesem Fall wird ein Baum mit einem kleineren Rang an einen Baum mit einem höheren Rang angehängt und nicht umgekehrt. Und während der Find-Operation werden alle Knoten, die entlang des Pfads besucht werden, an die Wurzel angehängt, die einen höheren Rang als ihre Kinder hat, sodass auch diese Operation nichts an dieser Tatsache ändert.
Lemma 2: Ein Knoten du das ist die Wurzel eines Teilbaums mit Rang R hat mindestens
2R{displaystyle 2^{r}}Knoten.


- Beweis: Wenn zunächst jeder Knoten die Wurzel seines eigenen Baums ist, ist dies trivialerweise wahr. Angenommen, ein Knoten du mit Rang R hat mindestens 2R Knoten. Dann, wenn zwei Bäume mit Rang R werden mit der Operation Union by Rank zusammengeführt, einem Baum mit Rang R + 1 Ergebnisse, deren Wurzel mindestens 2R+2R=2R+1{displaystyle 2^{r}+2^{r}=2^{r+1}} Knoten.




Lemma 3: Die maximale Anzahl von Knoten des Rangs R ist höchstens
n2R.{displaystyle {frac {n}{2^{r}}}.}


- Beweis: Aus Lemma 2 wissen wir, dass ein Knoten du das ist die Wurzel eines Teilbaums mit Rang R hat mindestens 2R{displaystyle 2^{r}} Knoten. Wir erhalten die maximale Anzahl von Knoten des Rangs R wenn jeder Knoten mit Rang R ist die Wurzel eines Baumes, der genau . hat 2R{displaystyle 2^{r}} Knoten. In diesem Fall ist die Anzahl der Knoten vom Rang R ist n2R.{displaystyle {frac {n}{2^{r}}}.}
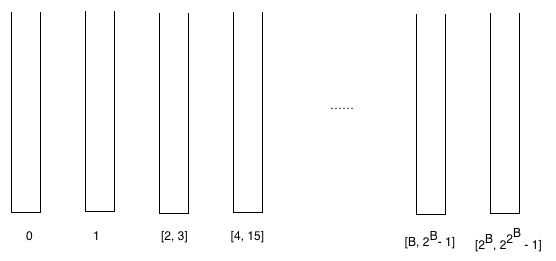
Der Einfachheit halber definieren wir hier “Bucket”: Ein Bucket ist eine Menge, die Scheitelpunkte mit bestimmten Rängen enthält.
Wir erstellen einige Buckets und legen induktiv Vertices entsprechend ihrer Ränge in die Buckets. Das heißt, Knoten mit Rang 0 gehen in den nullten Bucket, Knoten mit Rang 1 gehen in den ersten Bucket, Knoten mit Rang 2 und 3 gehen in den zweiten Bucket. Wenn die BNS Bucket enthält Knoten mit Rängen aus dem Intervall
[r,2r−1]=[r,R−1]{displaystyle left[r,2^{r}-1right]=[r,R-1]}dann enthält der (B+1)-te Bucket Knoten mit Rängen aus dem Intervall
[R,2R−1].{displaystyle left[R,2^{R}-1right].}
![{displaystyle left[r,2^{r}-1right]=[r,R-1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/49aa6ca95d184c363386c5c5aaa6c8932934e9b2)

![{displaystyle left[R,2^{R}-1right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fe254e2d62c18dbe3ed168f4417653d5afd1ed23)



Wir können zwei Beobachtungen über die Eimer machen.
- Die Gesamtzahl der Eimer ist höchstens Protokoll*n
- Beweis: Wenn wir von einem Eimer zum nächsten gehen, addieren wir noch zwei zur Potenz, d. h. den nächsten Eimer zu [B,2B−1]{displaystyle left[B,2^{B}-1right]} wird sein [2B,22B−1]{displaystyle left[2^{B},2^{2^{B}}-1right]}
- Die maximale Anzahl von Elementen im Bucket
[B,2B−1]{displaystyle left[B,2^{B}-1right]} ist höchstens 2n2B{displaystyle {frac {2n}{2^{B}}}}- Beweis: Die maximale Anzahl von Elementen im Eimer [B,2B−1]{displaystyle left[B,2^{B}-1right]} ist höchstens n2B+n2B+1+n2B+2+⋯+n22B−1≤2n2B.{displaystyle {frac {n}{2^{B}}}+{frac {n}{2^{B+1}}}+{frac {n}{2^{B+2}} }+cdots +{frac {n}{2^{2^{B}-1}}}leq {frac {2n}{2^{B}}}.}

![{displaystyle left[B,2^{B}-1right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/70d4053472d64e0df71dcc2afcd0a3612a0d0ec8)

![{displaystyle left[2^{B},2^{2^{B}}-1right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/da2969584bb2c660f6b964ed3f60a0d408a0d3bc)




Lassen F stellen die Liste der durchgeführten “Suchen”-Operationen dar, und lassen Sie






Dann sind die Gesamtkosten von m findet ist
T=T1+T2+T3.{displaystyle T=T_{1}+T_{2}+T_{3}.}


Da jede Find-Operation genau eine Traversierung durchführt, die zu einer Wurzel führt, gilt T1 = Ö(m).
Auch aus der oben angeführten Anzahl der Eimer haben wir T2 = Ö(mProtokoll*n).
Zum T3, nehmen wir an, wir durchlaufen eine Kante von du zu v, wo du und v haben Rang im Eimer [B, 2B − 1] und v ist nicht die Wurzel (zum Zeitpunkt dieser Durchquerung, sonst würde die Durchquerung berücksichtigt werden) T1). Fix du und betrachte die Folge
v1,v2,…,vk{displaystyle v_{1},v_{2},ldots,v_{k}}die die Rolle übernehmen v in verschiedenen Suchoperationen. Wegen der Pfadkompression und der Nichtberücksichtigung der Kante zu einer Wurzel enthält diese Folge nur verschiedene Knoten und wegen Lemma 1 wissen wir, dass die Ränge der Knoten in dieser Folge streng ansteigen. Da sich beide Knoten im Eimer befinden, können wir schließen, dass die Länge k der Sequenz (die Anzahl der Male, die node du an eine andere Wurzel im selben Bucket angehängt ist) ist höchstens die Anzahl der Ränge in den Buckets B, das heißt höchstens
2B−1−B<2B.{displaystyle 2^{B}-1-B<2^{B}.}



Deswegen,
T3≤Σ[B,2B−1]Σdu2B.{displaystyle T_{3}leq sum _{[B,2^{B}-1]}sum _{u}2^{B}.}

![{displaystyle T_{3}leq sum _{[B,2^{B}-1]}sum _{u}2^{B}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c6f85cd493fd0596a25595537c645fc839d9ebf0)
Aus den Beobachtungen 1 und 2 können wir schließen, dass
T3≤ΣB2B2n2B≤2nProtokoll*n.{displaystyle T_{3}leq sum_{B}2^{B}{frac {2n}{2^{B}}}leq 2nlog^{*}n.}


Deswegen,
T=T1+T2+T3=Ö(mProtokoll*n).{displaystyle T=T_{1}+T_{2}+T_{3}=O(mlog^{*}n).}


Anwendungen[edit]

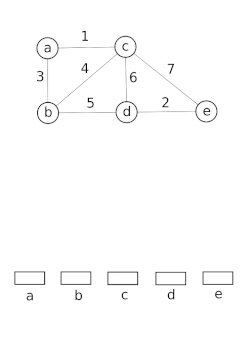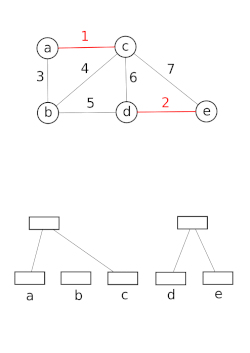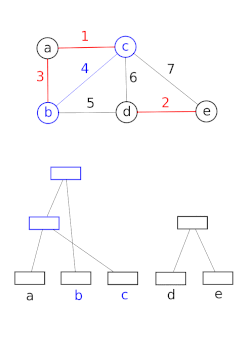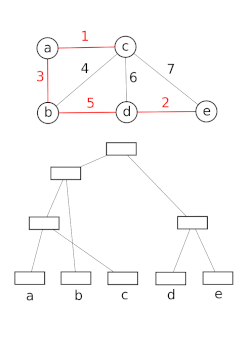
Datenstrukturen mit disjunkten Mengen modellieren die Partitionierung einer Menge, um beispielsweise die zusammenhängenden Komponenten eines ungerichteten Graphen zu verfolgen. Dieses Modell kann dann verwendet werden, um zu bestimmen, ob zwei Scheitelpunkte zu derselben Komponente gehören oder ob das Hinzufügen einer Kante zwischen ihnen zu einem Zyklus führen würde. Der Union-Find-Algorithmus wird in Hochleistungsimplementierungen der Vereinheitlichung verwendet.[15]
Diese Datenstruktur wird von der Boost Graph Library verwendet, um ihre Inkrementell verbundene Komponenten Funktionalität. Es ist auch eine Schlüsselkomponente bei der Implementierung des Kruskal-Algorithmus, um den minimalen Spannbaum eines Graphen zu finden.
Beachten Sie, dass die Implementierung als Wälder mit disjunkter Menge das Löschen von Kanten nicht zulässt, auch nicht ohne Pfadkomprimierung oder Rangheuristik.
Sharir und Agarwal berichten über Zusammenhänge zwischen dem Worst-Case-Verhalten disjunkter Mengen und der Länge von Davenport-Schinzel-Sequenzen, einer kombinatorischen Struktur aus der Computergeometrie.[16]
Siehe auch[edit]
Verweise[edit]
- ^ ein B C D e F Tarjan, Robert Endre (1975). „Effizienz eines guten, aber nicht linearen Set Union Algorithmus“. Zeitschrift der ACM. 22 (2): 215–225. mach:10.1145/321879.321884. hdl:1813/5942. S2CID 11105749.
- ^ Galler, Bernard A.; Fischer, Michael J. (Mai 1964). „Ein verbesserter Äquivalenzalgorithmus“. Mitteilungen des ACM. 7 (5): 301–303. mach:10.1145/364099.364331. S2CID 9034016.. Das Papier stammt aus disjunkten Wäldern.
- ^ Hopcroft, JE; Ullmann, JD (1973). “Zusammenführungsalgorithmen einstellen”. SIAM Journal on Computing. 2 (4): 294–303. mach:10.1137/0202024.
- ^ ein B C Tarjan, Robert E.; van Leeuwen, Jan (1984). „Worst-Case-Analyse von Set Union Algorithmen“. Zeitschrift der ACM. 31 (2): 245–281. mach:10.1145/62.2160. S2CID 5363073.
- ^ ein B Tarjan, Robert Endre (1979). “Eine Klasse von Algorithmen, die nichtlineare Zeit benötigen, um disjunkte Mengen aufrechtzuerhalten”. Zeitschrift für Informatik und Systemwissenschaften. 18 (2): 110–127. mach:10.1016/0022-0000(79)90042-4.
- ^ ein B Fredman, M.; Saks, M. (Mai 1989). „Die Zellsondierungskomplexität dynamischer Datenstrukturen“. Tagungsband des einundzwanzigsten jährlichen ACM Symposiums für Theory of Computing: 345–354. mach:10.1145/73007.73040. ISBN 0897913078. S2CID 13470414.
Satz 5: Beliebige CPROBE(log n) Die Implementierung des Mengenvereinigungsproblems erfordert Ω(m α(m, n)) Zeit zum Ausführen m Find’s und n−1 Unions, beginnend mit n Singleton-Sets.
- ^ Galil, Z.; Italiano, G. (1991). „Datenstrukturen und Algorithmen für disjunkte Satzvereinigungsprobleme“. ACM-Computing-Umfragen. 23 (3): 319–344. mach:10.1145/116873.116878. S2CID 207160759.
- ^ Anderson, Richard J.; Woll, Heather (1994). Wartefreie parallele Algorithmen für das Union-Find-Problem. 23. ACM-Symposium zur Computertheorie. S. 370–380.
- ^ Conchon, Sylvain; Filliâtre, Jean-Christophe (Oktober 2007). „Eine persistente Union-Find-Datenstruktur“. ACM SIGPLAN Workshop zu ML. Freiburg, Deutschland.
- ^ ein B C Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L.; Stein, Clifford (2009). „Kapitel 21: Datenstrukturen für disjunkte Mengen“. Einführung in Algorithmen (Dritte Aufl.). MIT-Presse. S. 571–572. ISBN 978-0-262-03384-8.
- ^ Raimund Seidel, Micha Sharir. “Top-down-Analyse der Pfadkompression”, SIAM J. Comput. 34(3):515–525, 2005
- ^ Tarjan, Robert Endre (1975). “Effizienz eines guten, aber nicht linearen Set-Union-Algorithmus”. Zeitschrift der ACM. 22 (2): 215–225. mach:10.1145/321879.321884. hdl:1813/5942. S2CID 11105749.
- ^ Hopcroft, JE; Ullmann, JD (1973). “Zusammenführungsalgorithmen einstellen”. SIAM Journal on Computing. 2 (4): 294–303. mach:10.1137/0202024.
- ^ Robert E. Tarjan und Jan van Leeuwen. Worst-Case-Analyse von Set-Union-Algorithmen. Zeitschrift der ACM, 31(2):245–281, 1984.
- ^ Ritter, Kevin (1989). “Vereinigung: Eine multidisziplinäre Umfrage” (PDF). ACM-Computing-Umfragen. 21: 93–124. mach:10.1145/62029.62030. S2CID 14619034.
- ^ Sharir, M.; Agarwal, P. (1995). Davenport-Schinzel-Sequenzen und ihre geometrischen Anwendungen. Cambridge University Press.
Externe Links[edit]
Recent Comments