Bioinformatik – Wikipedia
Computergestützte Analyse großer, komplexer biologischer Datenmengen




Bioinformatik ist ein interdisziplinäres Feld, das Methoden und Softwaretools zum Verständnis biologischer Daten entwickelt, insbesondere wenn die Datensätze groß und komplex sind. Als interdisziplinäres Wissenschaftsgebiet kombiniert die Bioinformatik Biologie, Informatik, Informationstechnik, Mathematik und Statistik, um die biologischen Daten zu analysieren und zu interpretieren. Bioinformatik wurde für verwendet in silico Analyse biologischer Abfragen mit mathematischen und statistischen Techniken.[clarification needed]
Die Bioinformatik umfasst biologische Studien, die Computerprogrammierung als Teil ihrer Methodik verwenden, sowie eine spezifische Analyse “Pipelines”, die insbesondere im Bereich der Genomik wiederholt verwendet werden. Übliche Anwendungen der Bioinformatik umfassen die Identifizierung von Kandidatengenen und Einzelnukleotidpolymorphismen (SNPs). Oft erfolgt eine solche Identifizierung mit dem Ziel, die genetischen Grundlagen von Krankheiten, einzigartige Anpassungen, wünschenswerte Eigenschaften (insbesondere bei landwirtschaftlichen Arten) oder Unterschiede zwischen Populationen besser zu verstehen. Auf weniger formale Weise versucht die Bioinformatik auch, die Organisationsprinzipien innerhalb von Nukleinsäure- und Proteinsequenzen zu verstehen, die als Proteomik bezeichnet werden.[1]
Einführung[edit]
Die Bioinformatik ist zu einem wichtigen Bestandteil vieler Bereiche der Biologie geworden. In der experimentellen Molekularbiologie ermöglichen Bioinformatik-Techniken wie Bild- und Signalverarbeitung die Extraktion nützlicher Ergebnisse aus großen Mengen von Rohdaten. Auf dem Gebiet der Genetik hilft es bei der Sequenzierung und Annotation von Genomen und ihren beobachteten Mutationen. Es spielt eine Rolle beim Text Mining biologischer Literatur und bei der Entwicklung biologischer und genetischer Ontologien zur Organisation und Abfrage biologischer Daten. Es spielt auch eine Rolle bei der Analyse der Expression und Regulation von Genen und Proteinen. Bioinformatik-Tools helfen beim Vergleichen, Analysieren und Interpretieren genetischer und genomischer Daten und allgemeiner beim Verständnis evolutionärer Aspekte der Molekularbiologie. Auf einer integrativeren Ebene hilft es, die biologischen Pfade und Netzwerke zu analysieren und zu katalogisieren, die ein wichtiger Bestandteil der Systembiologie sind. In der Strukturbiologie hilft es bei der Simulation und Modellierung von DNA,[2] RNA,[2][3] Proteine[4] sowie biomolekulare Wechselwirkungen.[5][6][7][8]
Geschichte[edit]
Historisch gesehen der Begriff Bioinformatik meinte nicht, was es heute bedeutet. Paulien Hogeweg und Ben Hesper prägten es 1970, um sich auf die Untersuchung von Informationsprozessen in biotischen Systemen zu beziehen.[9][10][11] Diese Definition stellte die Bioinformatik als ein Feld parallel zur Biochemie (Untersuchung chemischer Prozesse in biologischen Systemen).[9]
Sequenzen[edit]


Computer wurden in der Molekularbiologie unverzichtbar, als Proteinsequenzen verfügbar wurden, nachdem Frederick Sanger Anfang der 1950er Jahre die Insulinsequenz bestimmt hatte. Der manuelle Vergleich mehrerer Sequenzen erwies sich als unpraktisch. Eine Pionierin auf diesem Gebiet war Margaret Oakley Dayhoff.[12] Sie stellte eine der ersten Proteinsequenzdatenbanken zusammen, die ursprünglich als Bücher veröffentlicht wurden[13] und wegweisende Methoden zur Sequenzausrichtung und molekularen Evolution.[14] Ein weiterer früher Beitrag zur Bioinformatik war Elvin A. Kabat, der 1970 mit seinen umfassenden Mengen an Antikörpersequenzen, die zwischen 1980 und 1991 mit Tai Te Wu veröffentlicht wurden, Pionierarbeit in der biologischen Sequenzanalyse leistete.[15]
In den 1970er Jahren wurden neue Techniken zur Sequenzierung von DNA auf die Bakteriophagen MS2 und øX174 angewendet, und die erweiterten Nukleotidsequenzen wurden dann mit informativen und statistischen Algorithmen analysiert. Diese Studien haben gezeigt, dass bekannte Merkmale wie die Codierungssegmente und der Triplett-Code in einfachen statistischen Analysen aufgedeckt werden und somit das Konzept beweisen, dass Bioinformatik aufschlussreich wäre.[16][17]
Tore[edit]
Um zu untersuchen, wie sich normale zelluläre Aktivitäten bei verschiedenen Krankheitszuständen verändern, müssen die biologischen Daten kombiniert werden, um ein umfassendes Bild dieser Aktivitäten zu erhalten. Daher hat sich das Gebiet der Bioinformatik so weiterentwickelt, dass die dringendste Aufgabe nun die Analyse und Interpretation verschiedener Datentypen ist. Dies umfasst Nukleotid- und Aminosäuresequenzen, Proteindomänen und Proteinstrukturen.[18] Der eigentliche Prozess der Analyse und Interpretation von Daten wird als Computational Biology bezeichnet. Wichtige Unterdisziplinen in der Bioinformatik und Computerbiologie sind:
- Entwicklung und Implementierung von Computerprogrammen, die einen effizienten Zugriff auf, die Verwaltung und die Verwendung verschiedener Arten von Informationen ermöglichen.
- Entwicklung neuer Algorithmen (mathematische Formeln) und statistischer Maßnahmen zur Bewertung der Beziehungen zwischen Mitgliedern großer Datenmengen. Beispielsweise gibt es Verfahren, um ein Gen innerhalb einer Sequenz zu lokalisieren, die Proteinstruktur und / oder -funktion vorherzusagen und Proteinsequenzen in Familien verwandter Sequenzen zu gruppieren.
Das Hauptziel der Bioinformatik ist es, das Verständnis für biologische Prozesse zu verbessern. Was es jedoch von anderen Ansätzen unterscheidet, ist sein Fokus auf die Entwicklung und Anwendung rechenintensiver Techniken, um dieses Ziel zu erreichen. Beispiele hierfür sind: Mustererkennung, Data Mining, Algorithmen für maschinelles Lernen und Visualisierung. Zu den wichtigsten Forschungsanstrengungen auf diesem Gebiet gehören Sequenzausrichtung, Genfindung, Genomassemblierung, Wirkstoffdesign, Wirkstoffentdeckung, Proteinstrukturausrichtung, Proteinstrukturvorhersage, Vorhersage der Genexpression und Protein-Protein-Wechselwirkungen, genomweite Assoziationsstudien und die Modellierung der Evolution und Zellteilung / Mitose.
Die Bioinformatik umfasst nun die Erstellung und Weiterentwicklung von Datenbanken, Algorithmen, rechnerischen und statistischen Techniken sowie der Theorie zur Lösung formaler und praktischer Probleme, die sich aus der Verwaltung und Analyse biologischer Daten ergeben.
In den letzten Jahrzehnten haben rasante Entwicklungen in der Genom- und anderen molekularen Forschungstechnologien sowie Entwicklungen in den Informationstechnologien zusammen eine enorme Menge an Informationen in Bezug auf die Molekularbiologie hervorgebracht. Bioinformatik ist der Name für diese mathematischen und rechnerischen Ansätze, die zum Verständnis biologischer Prozesse verwendet werden.
Häufige Aktivitäten in der Bioinformatik umfassen das Kartieren und Analysieren von DNA- und Proteinsequenzen, das Ausrichten von DNA- und Proteinsequenzen, um diese zu vergleichen, sowie das Erstellen und Anzeigen von 3D-Modellen von Proteinstrukturen.
Beziehung zu anderen Feldern[edit]
Die Bioinformatik ist ein Wissenschaftsgebiet, das dem biologischen Rechnen ähnlich ist, sich jedoch von diesem unterscheidet, während es häufig als Synonym für Computational Biology angesehen wird. Biologische Berechnungen verwenden Bioengineering und Biologie, um biologische Computer zu bauen, während Bioinformatik Berechnungen verwendet, um die Biologie besser zu verstehen. Bioinformatik und Computerbiologie umfassen die Analyse biologischer Daten, insbesondere von DNA-, RNA- und Proteinsequenzen. Das Gebiet der Bioinformatik verzeichnete ab Mitte der neunziger Jahre ein explosives Wachstum, das vor allem auf das Humangenomprojekt und die raschen Fortschritte in der DNA-Sequenzierungstechnologie zurückzuführen war.
Die Analyse biologischer Daten zur Erzeugung aussagekräftiger Informationen umfasst das Schreiben und Ausführen von Softwareprogrammen, die Algorithmen aus Graphentheorie, künstlicher Intelligenz, Soft Computing, Data Mining, Bildverarbeitung und Computersimulation verwenden. Die Algorithmen hängen wiederum von theoretischen Grundlagen wie diskreter Mathematik, Steuerungstheorie, Systemtheorie, Informationstheorie und Statistik ab.
Sequenzanalyse[edit]
Da der Phage Φ-X174 1977 sequenziert wurde,[19] Die DNA-Sequenzen von Tausenden von Organismen wurden dekodiert und in Datenbanken gespeichert. Diese Sequenzinformationen werden analysiert, um Gene zu bestimmen, die für Proteine, RNA-Gene, regulatorische Sequenzen, Strukturmotive und repetitive Sequenzen kodieren. Ein Vergleich von Genen innerhalb einer Art oder zwischen verschiedenen Arten kann Ähnlichkeiten zwischen Proteinfunktionen oder Beziehungen zwischen Arten zeigen (Verwendung molekularer Systematik zur Konstruktion phylogenetischer Bäume). Mit der wachsenden Datenmenge wurde es längst unpraktisch, DNA-Sequenzen manuell zu analysieren. Computerprogramme wie BLAST werden routinemäßig zum Suchen von Sequenzen verwendet – ab 2008 von mehr als 260.000 Organismen, die über 190 Milliarden Nukleotide enthalten.[20]
DNA-Sequenzierung[edit]
Bevor Sequenzen analysiert werden können, müssen sie aus dem Beispiel der Datenbank der Genbank bezogen werden. Die DNA-Sequenzierung ist immer noch ein nicht triviales Problem, da die Rohdaten verrauscht sein oder von schwachen Signalen beeinträchtigt werden können. Es wurden Algorithmen für die Basis entwickelt, die die verschiedenen experimentellen Ansätze zur DNA-Sequenzierung erfordern.
Sequenzassemblierung[edit]
Die meisten DNA-Sequenzierungstechniken produzieren kurze Sequenzfragmente, die zusammengesetzt werden müssen, um vollständige Gen- oder Genomsequenzen zu erhalten. Die sogenannte Shotgun-Sequenzierungstechnik (die beispielsweise vom Institut für Genomforschung (TIGR) zur Sequenzierung des ersten Bakteriengenoms verwendet wurde, Haemophilus influenzae)[21] erzeugt die Sequenzen von vielen tausend kleinen DNA-Fragmenten (von 35 bis 900 Nukleotiden lang, abhängig von der Sequenzierungstechnologie). Die Enden dieser Fragmente überlappen sich und können, wenn sie durch ein Genomassemblierungsprogramm richtig ausgerichtet werden, verwendet werden, um das gesamte Genom zu rekonstruieren. Die Shotgun-Sequenzierung liefert schnell Sequenzdaten, aber die Aufgabe, die Fragmente zusammenzusetzen, kann für größere Genome ziemlich kompliziert sein. Bei einem Genom, das so groß ist wie das menschliche Genom, kann es auf Multiprozessor-Computern mit großem Speicher viele Tage dauern, bis die Fragmente zusammengesetzt sind. Die resultierende Baugruppe enthält normalerweise zahlreiche Lücken, die später ausgefüllt werden müssen. Die Shotgun-Sequenzierung ist die Methode der Wahl für praktisch alle heute sequenzierten Genome[when?]und Genomassemblierungsalgorithmen sind ein kritischer Bereich der Bioinformatikforschung.
Annotation des Genoms[edit]
Annotation ist im Kontext der Genomik der Prozess der Markierung der Gene und anderer biologischer Merkmale in einer DNA-Sequenz. Dieser Prozess muss automatisiert werden, da die meisten Genome zu groß sind, um von Hand annotiert zu werden, ganz zu schweigen von dem Wunsch, so viele Genome wie möglich zu annotieren, da die Sequenzierungsrate keinen Engpass mehr darstellt. Die Annotation wird durch die Tatsache ermöglicht, dass Gene erkennbare Start- und Stoppregionen aufweisen, obwohl die genaue Sequenz, die in diesen Regionen gefunden wird, zwischen den Genen variieren kann.
Die erste Beschreibung eines umfassenden Genom-Annotationssystems wurde 1995 veröffentlicht[21] vom Team des Instituts für Genomforschung, das die erste vollständige Sequenzierung und Analyse des Genoms eines frei lebenden Organismus, des Bakteriums, durchführte Haemophilus influenzae.[21]Owen White entwarf und baute ein Softwaresystem, um die Gene zu identifizieren, die für alle Proteine kodieren, RNAs, ribosomale RNAs (und andere Stellen) zu übertragen und erste funktionelle Zuordnungen vorzunehmen. Die meisten aktuellen Genom-Annotationssysteme funktionieren ähnlich, aber die für die Analyse genomischer DNA verfügbaren Programme, wie das GeneMark-Programm, wurden trainiert und verwendet, um proteinkodierende Gene in zu finden Haemophilus influenzae, ändern und verbessern sich ständig.
Nach den Zielen, die das Humangenomprojekt nach seiner Schließung im Jahr 2003 erreichen wollte, erschien ein neues Projekt, das vom National Human Genome Research Institute in den USA entwickelt wurde. Das sogenannte ENCODE-Projekt ist eine kollaborative Datenerfassung der Funktionselemente des menschlichen Genoms, die DNA-Sequenzierungstechnologien der nächsten Generation und Genom-Tiling-Arrays verwendet. Diese Technologien können automatisch große Datenmengen zu drastisch reduzierten Kosten pro Basis generieren aber mit der gleichen Genauigkeit (Basisaufruffehler) und Wiedergabetreue (Montagefehler).
Computergestützte Evolutionsbiologie[edit]
Die Evolutionsbiologie ist die Untersuchung der Herkunft und Abstammung von Arten sowie ihrer Veränderung im Laufe der Zeit. Die Informatik hat Evolutionsbiologen dabei unterstützt, Forschern Folgendes zu ermöglichen:
- Verfolgen Sie die Entwicklung einer großen Anzahl von Organismen, indem Sie Änderungen in ihrer DNA messen und nicht nur durch physikalische Taxonomie oder physiologische Beobachtungen.
- Vergleichen Sie ganze Genome, um komplexere evolutionäre Ereignisse wie Genduplikation, horizontalen Gentransfer und die Vorhersage von Faktoren zu untersuchen, die für die Bakterienspeziation wichtig sind.
- Erstellen Sie komplexe Modelle zur rechnergestützten Populationsgenetik, um das Ergebnis des Systems im Zeitverlauf vorherzusagen[22]
- Informationen über eine immer größere Anzahl von Arten und Organismen verfolgen und austauschen
Zukünftige Arbeiten zielen darauf ab, den jetzt komplexeren Baum des Lebens zu rekonstruieren.[according to whom?]
Der Forschungsbereich der Informatik, der genetische Algorithmen verwendet, wird manchmal mit der rechnergestützten Evolutionsbiologie verwechselt, aber die beiden Bereiche sind nicht unbedingt miteinander verbunden.
Vergleichende Genomik[edit]
Der Kern der vergleichenden Genomanalyse ist die Herstellung der Korrespondenz zwischen Genen (Orthologieanalyse) oder anderen genomischen Merkmalen in verschiedenen Organismen. Es sind diese intergenomischen Karten, die es ermöglichen, die Evolutionsprozesse zu verfolgen, die für die Divergenz zweier Genome verantwortlich sind. Eine Vielzahl von Evolutionsereignissen, die auf verschiedenen Organisationsebenen wirken, prägen die Genomentwicklung. Auf der niedrigsten Ebene wirken sich Punktmutationen auf einzelne Nukleotide aus. Auf einer höheren Ebene werden große chromosomale Segmente dupliziert, lateral übertragen, inversiert, transpositioniert, gelöscht und inseriert.[23] Letztendlich sind ganze Genome an Prozessen der Hybridisierung, Polyploidisierung und Endosymbiose beteiligt, was häufig zu einer schnellen Speziation führt. Die Komplexität der Genomentwicklung stellt Entwickler mathematischer Modelle und Algorithmen vor viele spannende Herausforderungen, die auf ein Spektrum algorithmischer, statistischer und mathematischer Techniken zurückgreifen können, das von exakten, heuristischen, festen Parameter- und Approximationsalgorithmen für Probleme, die auf Sparsamkeitsmodellen basieren, bis hin zu Markov reicht Ketten-Monte-Carlo-Algorithmen zur Bayes’schen Analyse von Problemen basierend auf probabilistischen Modellen.
Viele dieser Studien basieren auf dem Nachweis von Sequenzhomologie, um Sequenzen Proteinfamilien zuzuordnen.[24]
Pan-Genomik[edit]
Pan Genomics ist ein 2005 von Tettelin und Medini eingeführtes Konzept, das schließlich in der Bioinformatik Fuß fasst. Das Pan-Genom ist das vollständige Genrepertoire einer bestimmten taxonomischen Gruppe: Obwohl es ursprünglich auf eng verwandte Stämme einer Art angewendet wurde, kann es auf einen größeren Kontext wie Gattung, Stamm usw. angewendet werden. Es ist in zwei Teile unterteilt: Das Kerngenom: Set von Genen, die allen untersuchten Genomen gemeinsam sind (dies sind häufig überlebenswichtige Housekeeping-Gene) und The Dispensable / Flexible Genome: Satz von Genen, die nur in einem oder einigen untersuchten Genomen vorhanden sind. Ein Bioinformatik-Tool BPGA kann verwendet werden, um das Pan-Genom von Bakterienspezies zu charakterisieren.[25]
Genetik der Krankheit[edit]
Mit dem Aufkommen der Sequenzierung der nächsten Generation erhalten wir genügend Sequenzdaten, um die Gene der Unfruchtbarkeit komplexer Krankheiten abzubilden.[26]Brustkrebs[27] oder Alzheimer-Krankheit.[28] Genomweite Assoziationsstudien sind ein nützlicher Ansatz, um die für solche komplexen Krankheiten verantwortlichen Mutationen zu lokalisieren.[29] Durch diese Studien wurden Tausende von DNA-Varianten identifiziert, die mit ähnlichen Krankheiten und Merkmalen assoziiert sind.[30] Darüber hinaus ist die Möglichkeit, Gene bei Prognose, Diagnose oder Behandlung zu verwenden, eine der wichtigsten Anwendungen. In vielen Studien werden sowohl die vielversprechenden Möglichkeiten zur Auswahl der zu verwendenden Gene als auch die Probleme und Fallstricke bei der Verwendung von Genen zur Vorhersage des Vorhandenseins oder der Prognose von Krankheiten erörtert.[31]
Analyse von Mutationen bei Krebs[edit]
Bei Krebs werden die Genome betroffener Zellen auf komplexe oder sogar unvorhersehbare Weise neu angeordnet. Massive Sequenzierungsbemühungen werden verwendet, um bisher unbekannte Punktmutationen in einer Vielzahl von Genen bei Krebs zu identifizieren. Bioinformatiker stellen weiterhin spezialisierte automatisierte Systeme her, um das schiere Volumen der erzeugten Sequenzdaten zu verwalten, und sie entwickeln neue Algorithmen und Software, um die Sequenzierungsergebnisse mit der wachsenden Sammlung menschlicher Genomsequenzen und Keimbahnpolymorphismen zu vergleichen. Neue physikalische Detektionstechnologien werden eingesetzt, wie Oligonukleotid-Mikroarrays zur Identifizierung chromosomaler Gewinne und Verluste (als vergleichende genomische Hybridisierung bezeichnet) und Einzelnukleotid-Polymorphismus-Arrays zum Nachweis bekannter Punktmutationen. Diese Nachweismethoden messen gleichzeitig mehrere hunderttausend Stellen im gesamten Genom und erzeugen bei hohem Durchsatz zur Messung von Tausenden von Proben Terabyte an Daten pro Experiment. Wiederum eröffnen die enormen Mengen und neuen Datentypen neue Möglichkeiten für Bioinformatiker. Es wird häufig festgestellt, dass die Daten erhebliche Variabilität oder Rauschen enthalten. Daher werden Hidden-Markov-Modell- und Änderungspunkt-Analysemethoden entwickelt, um auf Änderungen der tatsächlichen Kopienzahl zu schließen.
Bei der bioinformatischen Analyse von Krebsgenomen im Zusammenhang mit der Identifizierung von Mutationen im Exom können zwei wichtige Prinzipien verwendet werden. Erstens ist Krebs eine Krankheit mit akkumulierten somatischen Mutationen in Genen. Zweiter Krebs enthält Fahrermutationen, die von Passagieren unterschieden werden müssen.[32]
Mit den Durchbrüchen, die diese Sequenzierungstechnologie der nächsten Generation auf dem Gebiet der Bioinformatik bietet, könnte sich die Krebsgenomik drastisch verändern. Mit diesen neuen Methoden und Software können Bioinformatiker viele Krebsgenome schnell und kostengünstig sequenzieren. Dies könnte einen flexibleren Prozess zur Klassifizierung von Krebsarten durch Analyse krebsbedingter Mutationen im Genom schaffen. Darüber hinaus kann die Verfolgung von Patienten während des Fortschreitens der Krankheit in Zukunft mit der Sequenz von Krebsproben möglich sein.[33]
Eine andere Art von Daten, die eine neuartige Entwicklung der Informatik erfordern, ist die Analyse von Läsionen, die bei vielen Tumoren als wiederkehrend befunden werden.
Gen- und Proteinexpression[edit]
Analyse der Genexpression[edit]
Die Expression vieler Gene kann durch Messen der mRNA-Spiegel mit mehreren Techniken bestimmt werden, einschließlich Microarrays, Expressed cDNA Sequence Tag (EST) -Sequenzierung, serielle Analyse der Genexpressions (SAGE) -Tag-Sequenzierung, Massively Parallel Signature Sequencing (MPSS), RNA-Seq, auch bekannt als “Whole Transcriptome Shotgun Sequencing” (WTSS) oder verschiedene Anwendungen der multiplexierten In-situ-Hybridisierung. Alle diese Techniken sind extrem rauschanfällig und / oder unterliegen Verzerrungen bei der biologischen Messung, und ein Hauptforschungsgebiet in der Computerbiologie umfasst die Entwicklung statistischer Werkzeuge zur Trennung von Signal und Rauschen in Hochdurchsatz-Genexpressionsstudien.[34] Solche Studien werden häufig verwendet, um die Gene zu bestimmen, die an einer Störung beteiligt sind: Man könnte Microarray-Daten von krebsartigen Epithelzellen mit Daten von nicht krebsartigen Zellen vergleichen, um die Transkripte zu bestimmen, die in einer bestimmten Population von Krebszellen hoch- und herunterreguliert sind .
Analyse der Proteinexpression[edit]
Protein-Microarrays und Massenspektrometrie (MS) mit hohem Durchsatz (HT) können eine Momentaufnahme der in einer biologischen Probe vorhandenen Proteine liefern. Die Bioinformatik ist sehr wichtig, um Protein-Microarray- und HT-MS-Daten zu verstehen. Der erstere Ansatz steht vor ähnlichen Problemen wie bei auf mRNA gerichteten Microarrays, der letztere beinhaltet das Problem des Abgleichs großer Mengen von Massendaten mit vorhergesagten Massen aus Proteinsequenzdatenbanken und die komplizierte statistische Analyse von Proben, bei denen mehrere, aber unvollständige Peptide von jedem Protein vorhanden sind erkannt. Die Lokalisierung zellulärer Proteine in einem Gewebekontext kann durch Affinitätsproteomik erreicht werden, die als räumliche Daten basierend auf Immunhistochemie und Gewebemikroarrays angezeigt wird.[35]
Analyse der Regulierung[edit]
Die Genregulation ist die komplexe Orchestrierung von Ereignissen, durch die ein Signal, möglicherweise ein extrazelluläres Signal wie ein Hormon, schließlich zu einer Zunahme oder Abnahme der Aktivität eines oder mehrerer Proteine führt. Bioinformatik-Techniken wurden angewendet, um verschiedene Schritte in diesem Prozess zu untersuchen.
Beispielsweise kann die Genexpression durch nahegelegene Elemente im Genom reguliert werden. Die Promotoranalyse beinhaltet die Identifizierung und Untersuchung von Sequenzmotiven in der DNA, die die kodierende Region eines Gens umgibt. Diese Motive beeinflussen das Ausmaß, in dem diese Region in mRNA transkribiert wird. Enhancer-Elemente, die weit vom Promotor entfernt sind, können auch die Genexpression durch dreidimensionale Schleifenwechselwirkungen regulieren. Diese Wechselwirkungen können durch bioinformatische Analyse von Experimenten zur Erfassung der Chromosomenkonformation bestimmt werden.
Expressionsdaten können verwendet werden, um auf die Genregulation zu schließen: Man könnte Microarray-Daten aus einer Vielzahl von Zuständen eines Organismus vergleichen, um Hypothesen über die an jedem Zustand beteiligten Gene zu bilden. In einem einzelligen Organismus kann man Stadien des Zellzyklus zusammen mit verschiedenen Stressbedingungen (Hitzeschock, Hunger usw.) vergleichen. Man kann dann Clustering-Algorithmen auf diese Expressionsdaten anwenden, um zu bestimmen, welche Gene coexprimiert werden. Beispielsweise können die stromaufwärts gelegenen Regionen (Promotoren) von coexprimierten Genen nach überrepräsentierten regulatorischen Elementen durchsucht werden. Beispiele für Clustering-Algorithmen, die beim Gen-Clustering angewendet werden, sind k-Means-Clustering, selbstorganisierende Karten (SOMs), hierarchisches Clustering und Consensus-Clustering-Methoden.
Analyse der zellulären Organisation[edit]
Es wurden verschiedene Ansätze entwickelt, um die Position von Organellen, Genen, Proteinen und anderen Komponenten in Zellen zu analysieren. Dies ist relevant, da der Ort dieser Komponenten die Ereignisse innerhalb einer Zelle beeinflusst und uns somit hilft, das Verhalten biologischer Systeme vorherzusagen. Eine Kategorie der Genontologie, zelluläre Komponentewurde entwickelt, um die subzelluläre Lokalisation in vielen biologischen Datenbanken zu erfassen.
Mikroskopie und Bildanalyse[edit]
Mikroskopische Bilder ermöglichen es uns, sowohl Organellen als auch Moleküle zu lokalisieren. Es kann uns auch helfen, zwischen normalen und abnormalen Zellen zu unterscheiden, z. B. bei Krebs.
Proteinlokalisierung[edit]
Die Lokalisierung von Proteinen hilft uns, die Rolle eines Proteins zu bewerten. Wenn zum Beispiel ein Protein im Kern gefunden wird, kann es an der Genregulation oder dem Spleißen beteiligt sein. Wenn ein Protein in Mitochondrien gefunden wird, kann es dagegen an der Atmung oder anderen Stoffwechselprozessen beteiligt sein. Die Proteinlokalisierung ist daher ein wichtiger Bestandteil der Vorhersage der Proteinfunktion. Es sind gut entwickelte Ressourcen zur Vorhersage der subzellulären Lokalisierung von Proteinen verfügbar, einschließlich Datenbanken zur subzellulären Lokalisierung von Proteinen und Vorhersagewerkzeugen.[36][37]
Kernorganisation von Chromatin[edit]
Daten aus Hochdurchsatz-Chromosomenkonformationserfassungsexperimenten wie Hi-C (Experiment) und ChIA-PET können Informationen über die räumliche Nähe von DNA-Loci liefern. Die Analyse dieser Experimente kann die dreidimensionale Struktur und Kernorganisation von Chromatin bestimmen. Zu den bioinformatischen Herausforderungen in diesem Bereich gehört die Aufteilung des Genoms in Domänen wie Topologisch assoziierende Domänen (TADs), die zusammen im dreidimensionalen Raum organisiert sind.[38]
Strukturelle Bioinformatik[edit]

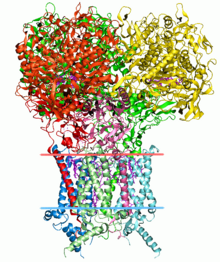
Die Vorhersage der Proteinstruktur ist eine weitere wichtige Anwendung der Bioinformatik. Die Aminosäuresequenz eines Proteins, die sogenannte Primärstruktur, kann leicht aus der Sequenz auf dem Gen bestimmt werden, das dafür kodiert. In den allermeisten Fällen bestimmt diese Primärstruktur eine Struktur in ihrer ursprünglichen Umgebung eindeutig. (Natürlich gibt es Ausnahmen wie das Prion der spongiformen Rinderenzephalopathie (Rinderwahnsinn).) Die Kenntnis dieser Struktur ist für das Verständnis der Funktion des Proteins von entscheidender Bedeutung. Strukturinformationen werden normalerweise als eine von klassifiziert sekundär, Tertiär- und Quartär Struktur. Eine praktikable allgemeine Lösung für solche Vorhersagen bleibt ein offenes Problem. Die meisten Bemühungen waren bisher auf Heuristiken gerichtet, die die meiste Zeit funktionieren.[citation needed]
Eine der Schlüsselideen in der Bioinformatik ist der Begriff der Homologie. Im genomischen Zweig der Bioinformatik wird Homologie verwendet, um die Funktion eines Gens vorherzusagen: wenn die Sequenz des Gens EIN, dessen Funktion bekannt ist, ist homolog zur Gensequenz B, deren Funktion unbekannt ist, könnte man schließen, dass B die Funktion von A teilen kann. Im strukturellen Zweig der Bioinformatik wird anhand der Homologie bestimmt, welche Teile eines Proteins für die Strukturbildung und Interaktion mit anderen Proteinen wichtig sind. In einer als Homologiemodellierung bezeichneten Technik wird diese Information verwendet, um die Struktur eines Proteins vorherzusagen, sobald die Struktur eines homologen Proteins bekannt ist. Dies ist derzeit die einzige Möglichkeit, Proteinstrukturen zuverlässig vorherzusagen.
Ein Beispiel hierfür ist Hämoglobin beim Menschen und Hämoglobin bei Hülsenfrüchten (Leghemoglobin), die entfernte Verwandte derselben Protein-Superfamilie sind. Beide dienen dem gleichen Zweck, Sauerstoff im Organismus zu transportieren. Obwohl diese beiden Proteine völlig unterschiedliche Aminosäuresequenzen aufweisen, sind ihre Proteinstrukturen praktisch identisch, was ihre nahezu identischen Zwecke und gemeinsamen Vorfahren widerspiegelt.[39]
Andere Techniken zur Vorhersage der Proteinstruktur umfassen Protein-Threading und de novo (von Grund auf neu) Physikbasierte Modellierung.
Ein weiterer Aspekt der strukturellen Bioinformatik umfasst die Verwendung von Proteinstrukturen für virtuelle Screening-Modelle wie quantitative Struktur-Aktivitäts-Beziehungsmodelle und proteochemometrische Modelle (PCM). Darüber hinaus kann die Kristallstruktur eines Proteins zur Simulation von beispielsweise Ligandenbindungsstudien und verwendet werden in silico Mutagenesestudien.
Netzwerk- und Systembiologie[edit]
Netzwerkanalyse versucht, die Beziehungen innerhalb biologischer Netzwerke wie metabolischer oder Protein-Protein-Interaktionsnetzwerke zu verstehen. Obwohl biologische Netzwerke aus einem einzigen Molekül- oder Entitätstyp (z. B. Genen) aufgebaut werden können, versucht die Netzwerkbiologie häufig, viele verschiedene Datentypen wie Proteine, kleine Moleküle, Genexpressionsdaten und andere zu integrieren, die alle physikalisch miteinander verbunden sind funktional oder beides.
Systembiologie beinhaltet die Verwendung von Computersimulationen von zellulären Subsystemen (wie den Netzwerken von Metaboliten und Enzymen, die Metabolismus, Signaltransduktionswege und Genregulationsnetzwerke umfassen), um die komplexen Zusammenhänge dieser zellulären Prozesse zu analysieren und zu visualisieren. Künstliches Leben oder virtuelle Evolution versucht, evolutionäre Prozesse durch die Computersimulation einfacher (künstlicher) Lebensformen zu verstehen.
Molekulare Interaktionsnetzwerke[edit]


Zehntausende dreidimensionaler Proteinstrukturen wurden durch Röntgenkristallographie und Protein-Kernspinresonanzspektroskopie (Protein-NMR) bestimmt. Eine zentrale Frage in der strukturellen Bioinformatik ist, ob es praktisch ist, mögliche Protein-Protein-Wechselwirkungen nur auf dieser Grundlage vorherzusagen 3D-Formen ohne Durchführung von Protein-Protein-Interaktionsexperimenten. Es wurde eine Vielzahl von Methoden entwickelt, um das Protein-Protein-Docking-Problem anzugehen, obwohl es auf diesem Gebiet anscheinend noch viel zu tun gibt.
Andere auf diesem Gebiet auftretende Wechselwirkungen umfassen Protein-Ligand (einschließlich Arzneimittel) und Protein-Peptid. Die molekulardynamische Simulation der Bewegung von Atomen um drehbare Bindungen ist das Grundprinzip von Berechnungsalgorithmen, sogenannten Docking-Algorithmen, zur Untersuchung molekularer Wechselwirkungen.
Literaturanalyse[edit]
Die zunehmende Anzahl veröffentlichter Literatur macht es praktisch unmöglich, jede Arbeit zu lesen, was zu unzusammenhängenden Teilbereichen der Forschung führt. Die Literaturanalyse zielt darauf ab, diese wachsende Bibliothek von Textressourcen mithilfe rechnerischer und statistischer Linguistik abzubauen. Zum Beispiel:
- Abkürzungserkennung – Identifizieren Sie die Langform und Abkürzung von biologischen Begriffen
- Erkennung benannter Entitäten – Erkennen biologischer Begriffe wie Gennamen
- Protein-Protein-Interaktion – Identifizieren Sie aus Text, welche Proteine mit welchen Proteinen interagieren
Der Forschungsbereich stützt sich auf Statistik und Computerlinguistik.
Bildanalyse mit hohem Durchsatz[edit]
Computertechnologien werden verwendet, um die Verarbeitung, Quantifizierung und Analyse großer Mengen biomedizinischer Bilder mit hohem Informationsgehalt zu beschleunigen oder vollständig zu automatisieren. Moderne Bildanalysesysteme erweitern die Fähigkeit eines Beobachters, Messungen aus einem großen oder komplexen Satz von Bildern durchzuführen, indem sie Genauigkeit, Objektivität oder Geschwindigkeit verbessern. Ein voll entwickeltes Analysesystem kann den Beobachter vollständig ersetzen. Obwohl diese Systeme nicht nur für biomedizinische Bilder gelten, wird die biomedizinische Bildgebung sowohl für die Diagnostik als auch für die Forschung immer wichtiger. Einige Beispiele sind:
- Quantifizierung mit hohem Durchsatz und hoher Wiedergabetreue sowie subzelluläre Lokalisierung (High-Content-Screening, Zytohistopathologie, Bioimage-Informatik)
- Morphometrie
- klinische Bildanalyse und Visualisierung
- Bestimmen der Echtzeit-Luftströmungsmuster in der Atemlunge lebender Tiere
- Quantifizierung der Okklusionsgröße in Echtzeitbildern anhand der Entwicklung und Wiederherstellung während einer arteriellen Verletzung
- Verhaltensbeobachtungen anhand erweiterter Videoaufnahmen von Labortieren
- Infrarotmessungen zur Bestimmung der Stoffwechselaktivität
- Ableiten von Klonüberlappungen bei der DNA-Kartierung, z. B. der Sulston-Score
Einzelzelldatenanalyse mit hohem Durchsatz[edit]
Computertechniken werden verwendet, um Einzelzelldaten mit hohem Durchsatz und geringer Messung zu analysieren, wie sie beispielsweise durch Durchflusszytometrie erhalten werden. Diese Verfahren umfassen typischerweise das Auffinden von Populationen von Zellen, die für einen bestimmten Krankheitszustand oder experimentellen Zustand relevant sind.
Biodiversitätsinformatik[edit]
Die Biodiversitätsinformatik befasst sich mit der Erfassung und Analyse von Biodiversitätsdaten wie taxonomischen Datenbanken oder Mikrobiomdaten. Beispiele für solche Analysen umfassen Phylogenetik, Nischenmodellierung, Kartierung des Artenreichtums, DNA-Barcodierung oder Tools zur Identifizierung von Arten.
Ontologien und Datenintegration[edit]
Biologische Ontologien sind gerichtete azyklische Graphen kontrollierter Vokabulare. Sie sollen biologische Konzepte und Beschreibungen auf eine Weise erfassen, die mit Computern leicht kategorisiert und analysiert werden kann. Auf diese Weise kategorisiert, kann durch ganzheitliche und integrierte Analyse ein Mehrwert erzielt werden.
Die OBO-Gießerei war ein Versuch, bestimmte Ontologien zu standardisieren. Eine der am weitesten verbreiteten ist die Genontologie, die die Genfunktion beschreibt. Es gibt auch Ontologien, die Phänotypen beschreiben.
Datenbanken[edit]
Datenbanken sind für die Forschung und Anwendung in der Bioinformatik von wesentlicher Bedeutung. Es gibt viele Datenbanken, die verschiedene Informationstypen abdecken: zum Beispiel DNA- und Proteinsequenzen, molekulare Strukturen, Phänotypen und Biodiversität. Datenbanken können empirische Daten (direkt aus Experimenten erhalten), vorhergesagte Daten (aus Analysen erhalten) oder am häufigsten beides enthalten. Sie können spezifisch für einen bestimmten Organismus, Weg oder Molekül von Interesse sein. Alternativ können sie Daten enthalten, die aus mehreren anderen Datenbanken zusammengestellt wurden. Diese Datenbanken unterscheiden sich in Format, Zugriffsmechanismus und ob sie öffentlich sind oder nicht.
Einige der am häufigsten verwendeten Datenbanken sind unten aufgeführt. Eine umfassendere Liste finden Sie unter dem Link am Anfang des Unterabschnitts.
Software und Tools[edit]
Die Softwaretools für die Bioinformatik reichen von einfachen Befehlszeilentools bis hin zu komplexeren Grafikprogrammen und eigenständigen Webdiensten, die von verschiedenen Bioinformatikunternehmen oder öffentlichen Institutionen angeboten werden.
Open-Source-Bioinformatik-Software[edit]
Viele kostenlose und Open-Source-Softwaretools existieren seit den 1980er Jahren und sind weiter gewachsen.[40] Die Kombination des anhaltenden Bedarfs an neuen Algorithmen für die Analyse neu auftretender Arten von biologischen Auslesungen, das Potenzial für Innovationen in silico Experimente und frei verfügbare Open-Code-Basen haben dazu beigetragen, dass alle Forschungsgruppen unabhängig von ihrer Finanzierungsvereinbarung einen Beitrag zur Bioinformatik und zum Angebot an Open-Source-Software leisten können. Die Open-Source-Tools fungieren häufig als Inkubatoren von Ideen oder als Community-unterstützte Plug-Ins in kommerziellen Anwendungen. Sie können auch zur Verfügung stellen de facto Standards und gemeinsame Objektmodelle zur Unterstützung bei der Herausforderung der Integration von Bioinformationen.
Das Angebot an Open-Source-Softwarepaketen umfasst Titel wie Bioconductor, BioPerl, Biopython, BioJava, BioJS, BioRuby, Bioclipse, EMBOSS, .NET Bio, Orange mit seinem Bioinformatik-Add-On, Apache Taverna, UGENE und GenoCAD. Um diese Tradition aufrechtzuerhalten und weitere Möglichkeiten zu schaffen, hat die gemeinnützige Open Bioinformatics Foundation[40] unterstützen seit 2000 die jährliche Bioinformatics Open Source Conference (BOSC).[41]
Eine alternative Methode zum Erstellen öffentlicher Bioinformatik-Datenbanken ist die Verwendung der MediaWiki-Engine mit dem WikiOpener Erweiterung. Mit diesem System können alle Experten auf dem Gebiet auf die Datenbank zugreifen und diese aktualisieren.[42]
Webdienste in der Bioinformatik[edit]
SOAP- und REST-basierte Schnittstellen wurden für eine Vielzahl von Bioinformatik-Anwendungen entwickelt, mit denen eine Anwendung, die auf einem Computer in einem Teil der Welt ausgeführt wird, Algorithmen, Daten und Computerressourcen auf Servern in anderen Teilen der Welt verwenden kann. Die Hauptvorteile ergeben sich aus der Tatsache, dass Endbenutzer sich nicht mit dem Aufwand für die Software- und Datenbankwartung befassen müssen.
Grundlegende Bioinformatikdienste werden vom EBI in drei Kategorien eingeteilt: SSS (Sequence Search Services), MSA (Multiple Sequence Alignment) und BSA (Biological Sequence Analysis).[43] Die Verfügbarkeit dieser serviceorientierten Bioinformatik-Ressourcen zeigt die Anwendbarkeit von webbasierten Bioinformatik-Lösungen und reicht von einer Sammlung eigenständiger Tools mit einem gemeinsamen Datenformat unter einer einzigen, eigenständigen oder webbasierten Schnittstelle bis hin zu integrativer, verteilter und erweiterbarer Bioinformatik Workflow-Management-Systeme.
Bioinformatik-Workflow-Management-Systeme[edit]
Ein Bioinformatik-Workflow-Management-System ist eine spezielle Form eines Workflow-Management-Systems, das speziell zum Erstellen und Ausführen einer Reihe von Rechen- oder Datenmanipulationsschritten oder eines Workflows in einer Bioinformatik-Anwendung entwickelt wurde. Solche Systeme sind darauf ausgelegt
- Bereitstellung einer benutzerfreundlichen Umgebung für einzelne Anwendungswissenschaftler, um ihre eigenen Workflows zu erstellen.
- Bereitstellung interaktiver Tools für die Wissenschaftler, mit denen sie ihre Workflows ausführen und ihre Ergebnisse in Echtzeit anzeigen können.
- Vereinfachen Sie den Prozess des Teilens und Wiederverwendens von Workflows zwischen den Wissenschaftlern und
- Ermöglichen Sie Wissenschaftlern, die Herkunft der Workflow-Ausführungsergebnisse und die Schritte zur Workflow-Erstellung zu verfolgen.
Einige der Plattformen, die diesen Service anbieten: Galaxy, Kepler, Taverna, UGENE, Anduril, HIVE.
BioCompute- und BioCompute-Objekte[edit]
2014 sponserte die US-amerikanische Food and Drug Administration eine Konferenz am Bethesda Campus der National Institutes of Health, um die Reproduzierbarkeit in der Bioinformatik zu erörtern.[44] In den nächsten drei Jahren traf sich regelmäßig ein Konsortium von Interessengruppen, um zu erörtern, was zum BioCompute-Paradigma werden würde.[45] Zu diesen Stakeholdern gehörten Vertreter von Regierung, Industrie und akademischen Einrichtungen. Die Sitzungsleiter vertraten zahlreiche Zweigstellen der Institute und Zentren der FDA und des NIH, gemeinnützige Organisationen wie das Human Variome Project und die Europäische Föderation für medizinische Informatik sowie Forschungseinrichtungen wie Stanford, das New York Genome Center und die George Washington University.
Es wurde beschlossen, dass das BioCompute-Paradigma in Form von digitalen „Laborbüchern“ vorliegt, die die Reproduzierbarkeit, Replikation, Überprüfung und Wiederverwendung von Bioinformatikprotokollen ermöglichen. Dies wurde vorgeschlagen, um eine größere Kontinuität innerhalb einer Forschungsgruppe im Verlauf des normalen Personalflusses zu ermöglichen und gleichzeitig den Gedankenaustausch zwischen Gruppen zu fördern. Die US-amerikanische FDA hat diese Arbeit finanziert, damit Informationen über Pipelines transparenter und für ihre Aufsichtsbehörden zugänglicher werden.[46]
2016 trat die Gruppe am NIH in Bethesda zusammen und diskutierte das Potenzial für ein BioCompute-Objekt, eine Instanz des BioCompute-Paradigmas. Diese Arbeit wurde sowohl als “Standard-Testversion” -Dokument als auch als auf bioRxiv hochgeladenes Preprint-Papier kopiert. Mit dem BioCompute-Objekt kann der JSON-basierte Datensatz von Mitarbeitern, Mitarbeitern und Aufsichtsbehörden gemeinsam genutzt werden.[47][48]
Bildungsplattformen[edit]
Zu den Softwareplattformen für die Vermittlung von Konzepten und Methoden der Bioinformatik gehören Rosalind und Online-Kurse, die über das Schulungsportal des Schweizerischen Instituts für Bioinformatik angeboten werden. Die kanadischen Bioinformatik-Workshops bieten Videos und Folien von Schulungsworkshops auf ihrer Website unter einer Creative Commons-Lizenz an. Das 4273π-Projekt oder das 4273pi-Projekt[49] bietet auch kostenlose Open-Source-Lehrmaterialien an. Der Kurs läuft auf kostengünstigen Raspberry Pi-Computern und wurde verwendet, um Erwachsene und Schüler zu unterrichten.[50][51] 4273π wird aktiv von einem Konsortium aus Wissenschaftlern und Forschungsmitarbeitern entwickelt, die Bioinformatik auf Forschungsebene mit Raspberry Pi-Computern und dem Betriebssystem 4273π betrieben haben.[52][53]
MOOC-Plattformen bieten auch Online-Zertifizierungen in Bioinformatik und verwandten Disziplinen, einschließlich Courseras Bioinformatik-Spezialisierung (UC San Diego) und Genomic Data Science-Spezialisierung (Johns Hopkins) sowie EdXs Datenanalyse für Life Sciences XSeries (Harvard). University of Southern California bietet eine Master in translationaler Bioinformatik Schwerpunkt auf biomedizinischen Anwendungen.
Konferenzen[edit]
Es gibt mehrere große Konferenzen, die sich mit Bioinformatik befassen. Einige der bemerkenswertesten Beispiele sind Intelligente Systeme für die Molekularbiologie (ISMB), die Europäische Konferenz für Computational Biology (ECCB) und Research in Computational Molecular Biology (RECOMB).
Siehe auch[edit]
Verweise[edit]
- ^ Lesk, AM (26. Juli 2013). “Bioinformatik”. Encyclopaedia Britannica.
- ^ ein b Sim, AYL; Minary, P.; Levitt, M. (2012). “Modellierung von Nukleinsäuren”. Aktuelle Meinung in der Strukturbiologie. 22 (3): 273–78. doi:10.1016 / j.sbi.2012.03.012. PMC 4028509. PMID 22538125.
- ^ Dawson, WK; Maciejczyk, M.; Jankowska, EJ; Bujnicki, JM (2016). “Grobkörnige Modellierung der RNA-3D-Struktur”. Methoden. 103: 138–56. doi:10.1016 / j.ymeth.2016.04.026. PMID 27125734.
- ^ Kmiecik, S.; Gront, D.; Kolinski, M.; Wieteska, L.; Dawid, AE; Kolinski, A. (2016). “Grobkörnige Proteinmodelle und ihre Anwendungen”. Chemische Bewertungen. 116 (14): 7898–936. doi:10.1021 / acs.chemrev.6b00163. PMID 27333362.
- ^ Wong, KC (2016). Computational Biology and Bioinformatics: Genregulation. CRC Press / Taylor & Francis Group. ISBN 9781498724975.
- ^ Joyce, AP; Zhang, C.; Bradley, P.; Havranek, JJ (2015). “Strukturbasierte Modellierung von Protein: DNA-Spezifität”. Briefings in Functional Genomics. 14 (1): 39–49. doi:10.1093 / bfgp / elu044. PMC 4366589. PMID 25414269.
- ^ Spiga, E.; Degiacomi, MT; Dal Peraro, M. (2014). “Neue Strategien zur integrativen dynamischen Modellierung makromolekularer Assemblierung”. In Karabencheva-Christova, T. (Hrsg.). Biomolekulare Modellierung und Simulationen. Fortschritte in der Proteinchemie und Strukturbiologie. 96. Akademische Presse. S. 77–111. doi:10.1016 / bs.apcsb.2014.06.008. ISBN 9780128000137. PMID 25443955.
- ^ Ciemny, Maciej; Kurcinski, Mateusz; Kamel, Karol; Kolinski, Andrzej; Alam, Nawsad; Schueler-Furman, Ora; Kmiecik, Sebastian (4. Mai 2018). “Protein-Peptid-Docking: Chancen und Herausforderungen”. Drug Discovery Today. 23 (8): 1530–37. doi:10.1016 / j.drudis.2018.05.006. ISSN 1359-6446. PMID 29733895.
- ^ ein b Hogeweg P (2011). Searls, David B. (Hrsg.). “Die Wurzeln der Bioinformatik in der theoretischen Biologie”. PLOS Computational Biology. 7 (3): e1002021. Bibcode:2011PLSCB … 7E2021H. doi:10.1371 / journal.pcbi.1002021. PMC 3068925. PMID 21483479.
- ^ Hesper B, Hogeweg P (1970). “Bioinformatica: een werkconcept”. 1 (6). Kameleon: 28–29.
- ^ Hogeweg P (1978). “Simulation des Wachstums zellulärer Formen”. Simulation. 31 (3): 90–96. doi:10.1177 / 003754977803100305. S2CID 61206099.
- ^ Moody, Glyn (2004). Digitaler Lebenskodex: Wie die Bioinformatik Wissenschaft, Medizin und Wirtschaft revolutioniert. ISBN 978-0-471-32788-2.
- ^ Dayhoff, MO (1966) Atlas der Proteinsequenz und -struktur. National Biomedical Research Foundation, 215 Seiten
- ^ Eck RV, Dayhoff MO (1966). “Entwicklung der Struktur von Ferredoxin basierend auf lebenden Relikten primitiver Aminosäuresequenzen”. Wissenschaft. 152 (3720): 363–66. Bibcode:1966Sci … 152..363E. doi:10.1126 / science.152.3720.363. PMID 17775169. S2CID 23208558.
- ^ Johnson G, Wu TT (Januar 2000). “Kabat-Datenbank und ihre Anwendungen: 30 Jahre nach dem ersten Variabilitätsdiagramm”. Nucleic Acids Res. 28 (1): 214–18. doi:10.1093 / nar / 28.1.214. PMC 102431. PMID 10592229.
- ^ Erickson, JW; Altman, GG (1979). “Eine Suche nach Mustern in der Nukleotidsequenz des MS2-Genoms”. Zeitschrift für Mathematische Biologie. 7 (3): 219–230. doi:10.1007 / BF00275725. S2CID 85199492.
- ^ Shulman, MJ; Steinberg, CM; Westmoreland, N. (1981). “Die Codierungsfunktion von Nukleotidsequenzen kann durch statistische Analyse erkannt werden”. Zeitschrift für Theoretische Biologie. 88 (3): 409–420. doi:10.1016 / 0022-5193 (81) 90274-5. PMID 6456380.
- ^ Xiong, Jin (2006). Grundlegende Bioinformatik. Cambridge, Großbritannien: Cambridge University Press. pp. 4. ISBN 978-0-511-16815-4 – über das Internetarchiv.
- ^ Sanger F, Luft-GM, Barrell BG, Brown NL, Coulson AR, Fiddes CA, Hutchison CA, Slocombe PM, Smith M (Februar 1977). “Nukleotidsequenz der Bakteriophagen-Phi-X174-DNA”. Natur. 265 (5596): 687–95. Bibcode:1977Natur.265..687S. doi:10.1038 / 265687a0. PMID 870828. S2CID 4206886.
- ^ Benson DA, Karsch-Mizrachi I, Lipman DJ, Ostell J, Wheeler DL (Januar 2008). “GenBank”. Nucleic Acids Res. 36 (Datenbankproblem): D25–30. doi:10.1093 / nar / gkm929. PMC 2238942. PMID 18073190.
- ^ ein b c Fleischmann RD, Adams MD, White O, Clayton RA, Kirkness EF, Kerlavage AR, Bult CJ, Tomb JF, Dougherty BA, Merrick JM (Juli 1995). “Zufällige Sequenzierung und Assemblierung des gesamten Genoms von Haemophilus influenzae Rd”. Wissenschaft. 269 (5223): 496–512. Bibcode:1995Sci … 269..496F. doi:10.1126 / science.7542800. PMID 7542800.
- ^ Carvajal-Rodríguez A (2012). “Simulation von Genen und Genomen in der Zeit vorwärts”. Aktuelle Genomik. 11 (1): 58–61. doi:10.2174 / 138920210790218007. PMC 2851118. PMID 20808525.
- ^ Brown, TA (2002). “Mutation, Reparatur und Rekombination”. Genome (2. Aufl.). Manchester (Großbritannien): Oxford.
- ^ Carter, NP; Fiegler, H.; Piper, J. (2002). “Vergleichende Analyse vergleichender genomischer Hybridisierungs-Microarray-Technologien: Bericht über einen vom Wellcome Trust gesponserten Workshop”. Zytometrie Teil A.. 49 (2): 43–48. doi:10.1002 / cyto.10153. PMID 12357458.
- ^ Chaudhari Narendrakumar M., Kumar Gupta Vinod, Dutta Chitra (2016). “BPGA – eine ultraschnelle Pan-Genom-Analyse-Pipeline”. Wissenschaftliche Berichte. 6: 24373. Bibcode:2016NatSR … 624373C. doi:10.1038 / srep24373. PMC 4829868. PMID 27071527.CS1-Wartung: mehrere Namen: Autorenliste (Link)
- ^ Aston KI (2014). “Genetische Anfälligkeit für männliche Unfruchtbarkeit: Nachrichten aus genomweiten Assoziationsstudien”. Andrologie. 2 (3): 315–21. doi:10.1111 / j.2047-2927.2014.00188.x. PMID 24574159. S2CID 206007180.
- ^ Véron A, Blein S., DG DG (2014). “Genomweite Assoziationsstudien und die Klinik: Ein Schwerpunkt auf Brustkrebs”. Biomarker in der Medizin. 8 (2): 287–96. doi:10.2217 / bmm.13.121. PMID 24521025.
- ^ Tosto G, Reitz C (2013). “Genomweite Assoziationsstudien bei Alzheimer: Ein Rückblick”. Aktuelle neurologische und neurowissenschaftliche Berichte. 13 (10): 381. doi:10.1007 / s11910-013-0381-0. PMC 3809844. PMID 23954969.
- ^ Londin E., Yadav P., Surrey S., Kricka LJ, Fortina P. (2013). “Verwendung von Verknüpfungsanalysen, genomweiten Assoziationsstudien und Sequenzierung der nächsten Generation bei der Identifizierung krankheitsverursachender Mutationen”. Pharmakogenomik. Methoden der Molekularbiologie. 1015. S. 127–46. doi:10.1007 / 978-1-62703-435-7_8. ISBN 978-1-62703-434-0. PMID 23824853.
- ^ Hindorff, LA; et al. (2009). “Mögliche ätiologische und funktionelle Auswirkungen genomweiter Assoziationsorte auf menschliche Krankheiten und Merkmale”. Proc. Natl. Acad. Sci. Vereinigte Staaten von Amerika. 106 (23): 9362–67. Bibcode:2009PNAS..106.9362H. doi:10.1073 / pnas.0903103106. PMC 2687147. PMID 19474294.
- ^ Hall, LO (2010). “Die richtigen Gene für die Vorhersage von Krankheiten und Prognosen finden”. 2010 Internationale Konferenz für Systemwissenschaft und Systemtechnik. System Science and Engineering (ICSSE), Internationale Konferenz 2010. S. 1–2. doi:10.1109 / ICSSE.2010.5551766. ISBN 978-1-4244-6472-2. S2CID 21622726.
- ^ Vazquez, Miguel; Torre, Victor de la; Valencia, Alfonso (27. Dezember 2012). “Kapitel 14: Krebsgenomanalyse”. PLOS Computational Biology. 8 (12): e1002824. Bibcode:2012PLSCB … 8E2824V. doi:10.1371 / journal.pcbi.1002824. ISSN 1553-7358. PMC 3531315. PMID 23300415.
- ^ Hye-Jung, EC; Jaswinder, K.; Martin, K.; Samuel, AA; Marco, AM (2014). “Sequenzierung der zweiten Generation für die Krebsgenomanalyse”. In Dellaire, Graham; Berman, Jason N.; Arceci, Robert J. (Hrsg.). Krebsgenomik. Boston (USA): Akademische Presse. S. 13–30. doi:10.1016 / B978-0-12-396967-5.00002-5. ISBN 9780123969675.
- ^ Grau, J.; Ben-Gal, I.; Posch, S.; Grosse, I. (1. Juli 2006). “VOMBAT: Vorhersage von Transkriptionsfaktor-Bindungsstellen unter Verwendung von Bayes’schen Bäumen variabler Ordnung” (PDF). Nukleinsäureforschung. 34 (Webserver): W529 – W533. doi:10.1093 / nar / gkl212. PMC 1538886. PMID 16845064.
- ^ “Der menschliche Proteinatlas”. www.proteinatlas.org. Abgerufen 2. Oktober 2017.
- ^ “Die menschliche Zelle”. www.proteinatlas.org. Abgerufen 2. Oktober 2017.
- ^ Thul, Peter J.; Åkesson, Lovisa; Wiking, Mikaela; Mahdessian, Diana; Geladaki, Aikaterini; Blal, Hammou Ait; Alm, Tove; Asplund, Anna; Björk, Lars (26. Mai 2017). “Eine subzelluläre Karte des menschlichen Proteoms”. Wissenschaft. 356 (6340): eaal3321. doi:10.1126 / science.aal3321. PMID 28495876. S2CID 10744558.
- ^ Ja, Ferhat; Noble, William S. (2. September 2015). “Analysemethoden zur Untersuchung der 3D-Architektur des Genoms”. Genombiologie. 16 (1): 183. doi:10.1186 / s13059-015-0745-7. PMC 4556012. PMID 26328929.
- ^ Hoy, JA; Robinson, H; Trent JT, 3 .; Kakar, S; Smagghe, BJ; Hargrove, MS (3. August 2007). “Pflanzenhämoglobine: ein molekularer Fossilienbestand für die Entwicklung des Sauerstofftransports”. Journal of Molecular Biology. 371 (1): 168–79. doi:10.1016 / j.jmb.2007.05.029. PMID 17560601.
- ^ ein b “Open Bioinformatics Foundation: Über uns”. Offizielle Website. Öffnen Sie die Bioinformatics Foundation. Abgerufen 10. Mai 2011.
- ^ “Open Bioinformatics Foundation: BOSC”. Offizielle Website. Öffnen Sie die Bioinformatics Foundation. Abgerufen 10. Mai 2011.
- ^ Brohée, Sylvain; Barriot, Roland; Moreau, Yves (2010). “Biologische Wissensdatenbanken mit Wikis: Kombination der Flexibilität von Wikis mit der Struktur von Datenbanken”. Bioinformatik. 26 (17): 2210–11. doi:10.1093 / bioinformatics / btq348. PMID 20591906.
- ^ Nisbet, Robert (2009). “Bioinformatik”. Handbuch für statistische Analysen und Data Mining-Anwendungen. John Elder IV, Gary Miner. Akademische Presse. p. 328. ISBN 978-0080912035.
- ^ Kommissar, Büro der. “Advancing Regulatory Science – 24. bis 25. September 2014 Öffentlicher Workshop: Sequenzierungsstandards der nächsten Generation”. www.fda.gov. Abgerufen 30. November 2017.
- ^ Simonyan, Vahan; Goecks, Jeremy; Mazumder, Raja (2017). “Biocompute-Objekte – Ein Schritt zur Bewertung und Validierung biomedizinischer wissenschaftlicher Berechnungen”. PDA Journal of Pharmaceutical Science and Technology. 71 (2): 136–46. doi:10.5731 / pdajpst.2016.006734. ISSN 1079-7440. PMC 5510742. PMID 27974626.
- ^ Kommissar, Büro der. “Advancing Regulatory Science – Community-basierte Entwicklung von HTS-Standards zur Validierung von Daten und Berechnungen und zur Förderung der Interoperabilität”. www.fda.gov. Abgerufen 30. November 2017.
- ^ Alterovitz, Gil; Dean, Dennis A.; Goble, Carole; Crusoe, Michael R.; Soiland-Reyes, Stian; Bell, Amanda; Hayes, Anais; König, Charles Hadley S.; Johanson, Elaine (4. Oktober 2017). “Aktivierung der Präzisionsmedizin durch Standardkommunikation der Herkunft, Analyse und Ergebnisse von NGS”. bioRxiv 10.1101 / 191783.
- ^ Das BioCompute Object (BCO) -Projekt ist ein kollaboratives und Community-gesteuertes Framework zur Standardisierung von HTS-Computerdaten. 1. BCO-Spezifikationsdokument: Benutzerhandbuch zum Verständnis und Erstellen von B., Biocompute-Objekte, 3. September 2017
- ^ Barker, D; Ferrier, DEK; Holland, PW; Mitchell, JBO; Plaisier, H; Ritchie, MG; Smart, SD (2013). “4273π: Bioinformatik-Ausbildung zu kostengünstiger ARM-Hardware”. BMC Bioinformatik. 14: 243. doi:10.1186 / 1471-2105-14-243. PMC 3751261. PMID 23937194.
- ^ Barker, D; Alderson, RG; McDonagh, JL; Plaisier, H; Comrie, MM; Duncan, L; Muirhead, GTP; Sweeny, SD (2015). “Praktische Aktivitäten auf Universitätsniveau in der Bioinformatik kommen freiwilligen Schülergruppen in den letzten zwei Schuljahren zugute.”. Internationale Zeitschrift für MINT-Bildung. 2 (17). doi:10.1186 / s40594-015-0030-z.
- ^ McDonagh, JL; Barker, D; Alderson, RG (2016). “Informatik der Öffentlichkeit zugänglich machen”. SpringerPlus. 5 (259): 259. doi:10.1186 / s40064-016-1856-7. PMC 4775721. PMID 27006868.
- ^ Robson, JF; Barker, D (2015). “Vergleich des proteinkodierenden Gengehalts von Chlamydia trachomatis und Protochlamydia amoebophila unter Verwendung eines Raspberry Pi-Computers”. BMC Research Notes. 8 (561): 561. doi:10.1186 / s13104-015-1476-2. PMC 4604092. PMID 26462790.
- ^ Wregglesworth, KM; Barker, D (2015). “Ein Vergleich der Protein-kodierenden Genome von zwei grünen Schwefelbakterien, Chlorobium tepidum TLS und Pelodictyon phaeoclathratiforme BU-1”. BMC Research Notes. 8 (565): 565. doi:10.1186 / s13104-015-1535-8. PMC 4606965. PMID 26467441.
Weiterführende Literatur[edit]
- Sehgal et al. : Strukturelle, phylogenetische und Docking-Studien des D-Aminosäureoxidase-Aktivators (DAOA), eines Kandidaten-Schizophrenie-Gens. Theoretische Biologie und medizinische Modellierung 2013 10: 3.
- Raul Isea Die heutige Bedeutung des Wortes Bioinformatik, Global Journal of Advanced Research, 2015
- Achuthsankar S Nair Computational Biology & Bioinformatics – Ein sanfter Überblick, Mitteilungen der Computer Society of India, Januar 2007
- Aluru, Srinivas, hrsg. Handbuch der Computational Molecular Biology. Chapman & Hall / Crc, 2006. ISBN 1-58488-406-1 (Chapman & Hall / Crc Computer- und Informationswissenschaftliche Reihe)
- Baldi, P und Brunak, S, Bioinformatik: Der Ansatz des maschinellen Lernens, 2. Auflage. MIT Press, 2001. ISBN 0-262-02506-X
- Barnes, MR und Gray, IC, Hrsg., Bioinformatik für Genetiker, erste Ausgabe. Wiley, 2003. ISBN 0-470-84394-2
- Baxevanis, AD und Ouellette, BFF, Hrsg., Bioinformatik: Ein praktischer Leitfaden zur Analyse von Genen und Proteinen, dritte Edition. Wiley, 2005. ISBN 0-471-47878-4
- Baxevanis, AD, Petsko, GA, Stein, LD und Stormo, GD, Hrsg., Aktuelle Protokolle in der Bioinformatik. Wiley, 2007. ISBN 0-471-25093-7
- Cristianini, N. und Hahn, M. Einführung in die Computational Genomics, Cambridge University Press, 2006. (ISBN 9780521671910 |ISBN 0-521-67191-4)
- Durbin, R., S. Eddy, A. Krogh und G. Mitchison, Biologische Sequenzanalyse. Cambridge University Press, 1998. ISBN 0-521-62971-3
- Gilbert D (2004). “Bioinformatik-Softwareressourcen”. Briefings in Bioinformatik. 5 (3): 300–304. doi:10.1093 / bib / 5.3.300. PMID 15383216.
- Keedwell, E., Intelligente Bioinformatik: Die Anwendung künstlicher Intelligenztechniken auf Bioinformatikprobleme. Wiley, 2005. ISBN 0-470-02175-6
- Kohane et al. Microarrays für eine integrative Genomik. The MIT Press, 2002. ISBN 0-262-11271-X
- Lund, O. et al. Immunologische Bioinformatik. The MIT Press, 2005. ISBN 0-262-12280-4
- Pachter, Lior und Sturmfels, Bernd. “Algebraische Statistik für Computational Biology” Cambridge University Press, 2005. ISBN 0-521-85700-7
- Pevzner, Pavel A. Computational Molecular Biology: Ein algorithmischer Ansatz The MIT Press, 2000. ISBN 0-262-16197-4
- Soinov, L. Bioinformatik und Mustererkennung kommen zusammen Journal of Pattern Recognition Research (JPRR), Vol 1 (1) 2006 p. 37–41
- Stevens, Hallam, Leben außerhalb der Sequenz: Eine datengetriebene Geschichte der Bioinformatik, Chicago: Die University of Chicago Press, 2013, ISBN 9780226080208
- Tisdall, James. “Perl für Bioinformatik beginnen” O’Reilly, 2001. ISBN 0-596-00080-4
- Katalyse der Untersuchung an der Schnittstelle von Computer und Biologie (2005) CSTB-Bericht
- Berechnung der Geheimnisse des Lebens: Beiträge der mathematischen Wissenschaften und des Rechnens zur Molekularbiologie (1995)
- Grundlagen der Computer- und Systembiologie MIT-Kurs
- Computational Biology: Genome, Netzwerke, Evolution Free MIT-Kurs
Externe Links[edit]

Recent Comments