Turbo-Code – Wikipedia
Hochleistungs-Vorwärtsfehlerkorrekturcodes
In der Informationstheorie Turbocodes (ursprünglich auf Französisch Turbocodes) sind eine Klasse von Hochleistungs-Vorwärtsfehlerkorrekturcodes (FEC), die zwischen 1990 und 1991 entwickelt wurden, aber erstmals 1993 veröffentlicht wurden. Sie waren die ersten praktischen Codes, die sich der maximalen Kanalkapazität oder der Shannon-Grenze, einem theoretischen Maximum für den Code, annäherten Rate, mit der bei einem bestimmten Geräuschpegel noch eine zuverlässige Kommunikation möglich ist. Turbo-Codes werden in der 3G / 4G-Mobilkommunikation (z. B. in UMTS und LTE) und in der (Weltraum-) Satellitenkommunikation sowie in anderen Anwendungen verwendet, in denen Entwickler eine zuverlässige Informationsübertragung über Kommunikationsverbindungen mit eingeschränkter Bandbreite oder Latenz in der USA anstreben Vorhandensein von datenverfälschendem Rauschen. Turbo-Codes konkurrieren mit LDPC-Codes (“Parity-Check mit niedriger Dichte”), die eine ähnliche Leistung bieten.
Der Name “Turbocode” entstand aus der Rückkopplungsschleife, die während der normalen Turbocode-Decodierung verwendet wurde, analog zu der Abgasrückkopplung, die für die Turboaufladung des Motors verwendet wurde. Hagenauer hat argumentiert, dass der Begriff Turbocode eine Fehlbezeichnung ist, da keine Rückkopplung in den Codierungsprozess involviert ist.[1]
Geschichte[edit]
Die grundlegende Patentanmeldung für Turbocodes wurde am 23. April 1991 eingereicht. In der Patentanmeldung wird Claude Berrou als einziger Erfinder von Turbocodes aufgeführt. Die Patentanmeldung führte zu mehreren Patenten, darunter US-Patent 5,446,747, die am 29. August 2013 abgelaufen ist.
Die erste öffentliche Zeitung über Turbocodes war “Near Shannon Limit Fehlerkorrektur Codierung und Decodierung: Turbo-Codes“.[2] Dieses Papier wurde 1993 in der Proceedings of IEEE International Communications Conference veröffentlicht. Das Papier von 1993 wurde aus drei separaten Einreichungen gebildet, die aus Platzgründen kombiniert wurden. Die Fusion veranlasste das Papier, drei Autoren aufzulisten: Berrou, Glavieux und Thitimajshima (von Télécom Bretagne, ehemalige ENST Bretagne, Frankreich). Aus der ursprünglichen Patentanmeldung geht jedoch hervor, dass Berrou der einzige Erfinder von Turbocodes ist und dass die anderen Autoren des Papiers anderes Material als die Kernkonzepte beigesteuert haben.
Turbo-Codes waren zum Zeitpunkt ihrer Einführung so revolutionär, dass viele Experten auf dem Gebiet der Codierung den gemeldeten Ergebnissen nicht glaubten. Als die Leistung bestätigt wurde, fand eine kleine Revolution in der Welt der Codierung statt, die zur Untersuchung vieler anderer Arten der iterativen Signalverarbeitung führte.
Die erste Klasse von Turbocode war der parallele verkettete Faltungscode (PCCC). Seit der Einführung der ursprünglichen parallelen Turbocodes im Jahr 1993 wurden viele andere Klassen von Turbocodes entdeckt, einschließlich serieller Versionen von seriell verketteten Faltungscodes und Wiederholungsakkumulationscodes. Iterative Turbodecodierungsverfahren wurden auch auf konventionellere FEC-Systeme angewendet, einschließlich Reed-Solomon-korrigierter Faltungscodes, obwohl diese Systeme für praktische Implementierungen iterativer Decodierer zu komplex sind. Der Turboausgleich ergab sich auch aus dem Konzept der Turbocodierung.
Neben Turbocodes erfand Berrou auch rekursive systematische Faltungscodes (RSC), die bei der beispielhaften Implementierung der im Patent beschriebenen Turbocodes verwendet werden. Turbocodes, die RSC-Codes verwenden, scheinen eine bessere Leistung zu erzielen als Turbocodes, die keine RSC-Codes verwenden.
Vor Turbocodes waren die besten Konstruktionen seriell verkettete Codes, die auf einem äußeren Reed-Solomon-Fehlerkorrekturcode in Kombination mit einem inneren Viterbi-decodierten Faltungscode mit kurzer Einschränkungslänge, auch als RSV-Codes bekannt, basierten.
In einem späteren Artikel würdigte Berrou die Intuition von “G. Battail, J. Hagenauer und P. Hoeher, die Ende der 80er Jahre das Interesse an probabilistischer Verarbeitung hervorhoben”. Er fügt hinzu, “R. Gallager und M. Tanner hatten sich bereits Codierungs- und Decodierungstechniken vorgestellt, deren allgemeine Prinzipien eng miteinander verbunden sind”, obwohl die notwendigen Berechnungen zu dieser Zeit unpraktisch waren.[3]
Ein Beispiel-Encoder[edit]
Es gibt viele verschiedene Fälle von Turbocodes, bei denen unterschiedliche Komponentencodierer, Eingangs- / Ausgangsverhältnisse, Interleaver und Punktionsmuster verwendet werden. Diese beispielhafte Encoder-Implementierung beschreibt einen klassischen Turbo-Encoder und demonstriert den allgemeinen Aufbau paralleler Turbo-Codes.
Diese Codiererimplementierung sendet drei Teilblöcke von Bits. Der erste Unterblock ist der m-bit Block von Nutzdaten. Der zweite Unterblock ist n / 2 Paritätsbits für die Nutzdaten, berechnet unter Verwendung eines rekursiven systematischen Faltungscodes (RSC-Code). Der dritte Unterblock ist n / 2 Paritätsbits für eine bekannte Permutation der Nutzdaten, die wiederum unter Verwendung eines RSC-Codes berechnet werden. Somit werden zwei redundante, aber unterschiedliche Unterblöcke von Paritätsbits mit der Nutzlast gesendet. Der komplette Block hat m + n Datenbits mit einer Coderate von m/ ((m + n). Die Permutation der Nutzdaten wird von einem Gerät durchgeführt, das als Interleaver bezeichnet wird.
In Bezug auf die Hardware besteht dieser Turbocode-Encoder aus zwei identischen RSC-Codierern, С1 und C2, wie in der Figur dargestellt, die über ein Verkettungsschema miteinander verbunden sind, genannt parallele Verkettung::

In der Figur, M. ist ein Speicherregister. Die Verzögerungsleitung und die Interleaver-Kraft-Eingangsbits dk in verschiedenen Sequenzen erscheinen. Bei der ersten Iteration die Eingabesequenz dk erscheint an beiden Ausgängen des Encoders, xk und y1k oder y2k aufgrund der systematischen Natur des Encoders. Wenn die Encoder C.1 und C.2 werden in verwendet n1 und n2 Iterationen sind ihre Raten jeweils gleich

Der Decoder[edit]
Der Decoder ist ähnlich wie der obige Encoder aufgebaut. Zwei Elementardecoder sind miteinander verbunden, jedoch in Reihe und nicht parallel. Das
Decoder arbeitet mit niedrigerer Geschwindigkeit (dh
 Decoder arbeitet mit niedrigerer Geschwindigkeit (dh
Decoder arbeitet mit niedrigerer Geschwindigkeit (dh ), also ist es für die
 ), also ist es für die
), also ist es für die Encoder und
 Encoder und
Encoder und ist für
 ist für
ist für entsprechend.
 entsprechend.
entsprechend. ergibt eine weiche Entscheidung, die verursacht
verzögern. Die gleiche Verzögerung wird durch die Verzögerungsleitung im Encoder verursacht. Das
 verzögern. Die gleiche Verzögerung wird durch die Verzögerungsleitung im Encoder verursacht. Das
verzögern. Die gleiche Verzögerung wird durch die Verzögerungsleitung im Encoder verursacht. Das ‘s Betrieb verursacht
verzögern.
 verzögern.
verzögern.
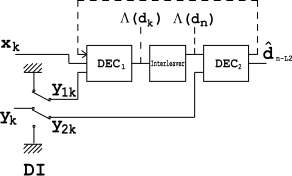
Ein zwischen den beiden Decodern installierter Interleaver wird hier verwendet, um Fehlerbursts zu streuen, die von kommen
Ausgabe. DI Block ist ein Demultiplex- und Einfügemodul. Es funktioniert als Schalter und leitet Eingangsbits an um
in einem Moment und zu
bei einem anderen. Im AUS-Zustand werden beide gespeist
und
 und
und Eingänge mit Füllbits (Nullen).
 Eingänge mit Füllbits (Nullen).
Eingänge mit Füllbits (Nullen).
Betrachten Sie einen speicherlosen AWGN-Kanal und nehmen Sie an, dass bei k-th Iteration, der Decoder empfängt ein Paar von Zufallsvariablen:

wo
und
 und
und sind unabhängige Rauschkomponenten mit der gleichen Varianz
 sind unabhängige Rauschkomponenten mit der gleichen Varianz
sind unabhängige Rauschkomponenten mit der gleichen Varianz .
 .
. ist ein k-th Bit von
 ist ein k-th Bit von
ist ein k-th Bit von Geberausgang.
 Geberausgang.
Geberausgang.
Redundante Informationen werden demultiplext und gesendet DI zu
(wann
) und zu
 ) und zu
) und zu (wann
).
 ).
).
ergibt eine weiche Entscheidung; dh:

und liefert es an
.
heißt das Logarithmus des Wahrscheinlichkeitsverhältnisses (LLR).
 heißt das Logarithmus des Wahrscheinlichkeitsverhältnisses (LLR).
heißt das Logarithmus des Wahrscheinlichkeitsverhältnisses (LLR). ist der a posteriori Wahrscheinlichkeit (APP) der
 ist der a posteriori Wahrscheinlichkeit (APP) der
ist der a posteriori Wahrscheinlichkeit (APP) der Datenbit, das die Wahrscheinlichkeit der Interpretation eines empfangenen anzeigt
 Datenbit, das die Wahrscheinlichkeit der Interpretation eines empfangenen anzeigt
Datenbit, das die Wahrscheinlichkeit der Interpretation eines empfangenen anzeigt bisschen wie
. Nehmen Sie die LLR berücksichtigen,
 . Nehmen Sie die LLR berücksichtigen,
. Nehmen Sie die LLR berücksichtigen, ergibt eine schwere Entscheidung; dh ein dekodiertes Bit.
Es ist bekannt, dass der Viterbi-Algorithmus APP nicht berechnen kann und daher nicht in verwendet werden kann
. Stattdessen wird ein modifizierter BCJR-Algorithmus verwendet. Zum
ist der Viterbi-Algorithmus geeignet.
Die dargestellte Struktur ist jedoch nicht optimal, weil
verwendet nur einen angemessenen Bruchteil der verfügbaren redundanten Informationen. Um die Struktur zu verbessern, wird eine Rückkopplungsschleife verwendet (siehe die gepunktete Linie in der Abbildung).
Weicher Entscheidungsansatz[edit]
Das Decoder-Front-End erzeugt für jedes Bit im Datenstrom eine Ganzzahl. Diese Ganzzahl ist ein Maß dafür, wie wahrscheinlich es ist, dass das Bit eine 0 oder 1 ist und auch aufgerufen wird weiches Stück. Die Ganzzahl könnte aus dem Bereich gezogen werden [−127, 127], wo:
- −127 bedeutet “sicherlich 0”
- −100 bedeutet “sehr wahrscheinlich 0”
- 0 bedeutet “es könnte entweder 0 oder 1 sein”
- 100 bedeutet “sehr wahrscheinlich 1”
- 127 bedeutet “sicherlich 1”
Dies führt einen probabilistischen Aspekt in den Datenstrom vom Front-End ein, vermittelt jedoch mehr Informationen über jedes Bit als nur 0 oder 1.
Beispielsweise muss das Front-End eines herkömmlichen Funkempfängers für jedes Bit entscheiden, ob eine interne analoge Spannung über oder unter einem bestimmten Schwellenspannungspegel liegt. Für einen Turbocode-Decoder würde das Front-End ein ganzzahliges Maß dafür liefern, wie weit die interne Spannung von dem gegebenen Schwellenwert entfernt ist.
Um die zu entschlüsseln m + n-Bit-Datenblock, das Decoder-Front-End erstellt einen Block von Wahrscheinlichkeitsmaßen mit einem Wahrscheinlichkeitsmaß für jedes Bit im Datenstrom. Es gibt zwei parallele Decoder, einen für jeden dern⁄2-bit Paritätsunterblöcke. Beide Decoder verwenden den Unterblock von m Wahrscheinlichkeiten für die Nutzdaten. Der Decoder, der an dem zweiten Paritätsunterblock arbeitet, kennt die Permutation, die der Codierer für diesen Unterblock verwendet hat.
Hypothesen lösen, um Bits zu finden[edit]
Die Schlüsselinnovation von Turbocodes besteht darin, wie sie die Wahrscheinlichkeitsdaten verwenden, um Unterschiede zwischen den beiden Decodern auszugleichen. Jeder der beiden Faltungsdecoder generiert eine Hypothese (mit abgeleiteten Wahrscheinlichkeiten) für das Muster von m Bits im Nutzlast-Unterblock. Die Hypothesenbitmuster werden verglichen, und wenn sie sich unterscheiden, tauschen die Decoder die abgeleiteten Wahrscheinlichkeiten aus, die sie für jedes Bit in den Hypothesen haben. Jeder Decodierer enthält die vom anderen Decodierer abgeleiteten Wahrscheinlichkeitsschätzungen, um eine neue Hypothese für die Bits in der Nutzlast zu generieren. Dann vergleichen sie diese neuen Hypothesen. Dieser iterative Prozess wird fortgesetzt, bis die beiden Decoder dieselbe Hypothese für die m-Bit-Muster der Nutzlast, typischerweise in 15 bis 18 Zyklen.
Es kann eine Analogie zwischen diesem Prozess und dem Lösen von Querverweisrätseln wie Kreuzworträtsel oder Sudoku gezogen werden. Betrachten Sie ein teilweise abgeschlossenes, möglicherweise verstümmeltes Kreuzworträtsel. Zwei Rätsellöser (Decoder) versuchen es zu lösen: einer besitzt nur die “Ab” -Hinweise (Paritätsbits) und der andere nur die “Über” -Hinweise. Zu Beginn erraten beide Löser die Antworten (Hypothesen) auf ihre eigenen Hinweise und notieren, wie sicher sie in jedem Buchstaben sind (Nutzlastbit). Anschließend vergleichen sie Notizen, indem sie Antworten und Vertrauensbewertungen miteinander austauschen und feststellen, wo und wie sie sich unterscheiden. Basierend auf diesem neuen Wissen liefern beide aktualisierte Antworten und Vertrauensbewertungen und wiederholen den gesamten Prozess, bis sie zur gleichen Lösung konvergieren.
Performance[edit]
Turbo-Codes weisen aufgrund der attraktiven Kombination des zufälligen Auftretens des Codes auf dem Kanal zusammen mit der physikalisch realisierbaren Decodierungsstruktur eine gute Leistung auf. Turbo-Codes sind von einer Fehleruntergrenze betroffen.
Praktische Anwendungen mit Turbocodes[edit]
Telekommunikation:
Bayesianische Formulierung[edit]
Unter dem Gesichtspunkt der künstlichen Intelligenz können Turbocodes als ein Beispiel für die Verbreitung von schleifenhaften Überzeugungen in Bayes’schen Netzwerken betrachtet werden.[5]
Siehe auch[edit]
Verweise[edit]
- ^ Joachim Hagenauer, Joachim; et al. “Iterative Decodierung von Binärblock- und Faltungscodes” (PDF). Archiviert von das Original (PDF) am 11. Juni 2013. Abgerufen 20. März 2014.
- ^ Berrou, Claude; Glavieux, Alain; Thitimajshima, Punya, Near Shannon Limit Error – Korrekturabgerufen 11. Februar 2010
- ^ Berrou, Claude, Die zehn Jahre alten Turbocodes werden in Betrieb genommen, Bretagne, Frankreichabgerufen 11. Februar 2010
- ^ Digital Video Broadcasting (DVB); Interaktionskanal für Satellitenverteilungssysteme, ETSI EN 301 790, V1.5.1, Mai 2009.
- ^ McEliece, Robert J.; MacKay, David JC; Cheng, Jung-Fu (1998), “Turbo-Decodierung als Instanz von Perles” Glaubensausbreitungs “-Algorithmus” (PDF), IEEE Journal zu ausgewählten Bereichen der Kommunikation, 16 (2): 140–152, doi:10.1109 / 49.661103, ISSN 0733-8716.
Externe Links[edit]
- “Den perfekten Code schließen”, IEEE Spectrum, März 2004
- “Der UMTS-Turbo-Code und eine effiziente Decoder-Implementierung, die für softwaredefinierte Funkgeräte geeignet ist” ((Internationales Journal für drahtlose Informationsnetzwerke)
- Dana Mackenzie (2005), “Bring es an die Grenzen”, Neuer Wissenschaftler, 187 (2507): 38–41, ISSN 0262-4079. ((Vorschau, Kopieren)
- “Das Limit überschreiten”, ein Wissenschaftsnachrichten Feature über die Entwicklung und Entstehung von Turbocodes
- Internationales Symposium über Turbocodes
- Codierte Modulationsbibliothek, eine Open-Source-Bibliothek zur Simulation von Turbocodes in Matlab
- “Turbo Equalization: Prinzipien und neue Ergebnisse”, ein IEEE-Transaktionen zur Kommunikation Artikel über die Verwendung von Faltungscodes zusammen mit dem Kanalausgleich.
- IT ++ Homepage IT ++ ist eine leistungsstarke C ++ – Bibliothek, die insbesondere Turbocodes unterstützt
- Turbo-Code-Veröffentlichungen von David MacKay
- AFF3CT-Homepage (A Fast Forward Error Correction Toolbox) für Hochgeschwindigkeits-Turbocodesimulationen in Software
- Turbo-Code von Dr. Sylvie Kerouédan und Dr. Claude Berrou (Scholarpedia.org).
- 3GPP LTE Turbo Referenzdesign.
- Schätzen Sie die Turbo Code BER-Leistung in AWGN (MatLab).
- Parallele verkettete Faltungscodierung: Turbo-Codes (MatLab Simulink)
Weiterführende Literatur[edit]
Veröffentlichungen[edit]
- Battail, Gérard. “Ein konzeptioneller Rahmen für das Verständnis von Turbocodes.” IEEE Journal on Selected Areas in Communications 16.2 (1998): 245–254.
- Brejza, Matthew F. et al. “20 Jahre Turbo-Codierung und energiebewusste Designrichtlinien für drahtlose Anwendungen mit eingeschränkter Energieversorgung.” IEEE Communications Surveys & Tutorials 18.1 (2016): 8–28.
- Garzón-Bohórquez, Ronald, Charbel Abdel Nour und Catherine Douillard. “Verbesserung der Turbo-Codes für 5G mit Interleavern mit eingeschränkter Paritätspunktion.” Turbocodes und iterative Informationsverarbeitung (ISTC), 9. Internationales Symposium 2016 über. IEEE, 2016.
Recent Comments