Hilbert-Kurve – Wikipedia

Das Hilbert-Kurve (auch bekannt als die Hilbert raumfüllende Kurve) ist eine kontinuierliche fraktale raumfüllende Kurve, die erstmals 1891 vom deutschen Mathematiker David Hilbert beschrieben wurde.[1] als Variante der raumfüllenden Peano-Kurven, die 1890 von Giuseppe Peano entdeckt wurden.[2]
Da es raumfüllend ist, ist seine Hausdorff-Dimension 2 (genau sein Bild ist das Einheitsquadrat, dessen Dimension in jeder Definition der Dimension 2 ist; sein Diagramm ist eine kompakte Menge, die homöomorph zum geschlossenen Einheitsintervall mit Hausdorff-Dimension 2 ist). .
Die Hilbert-Kurve ist als Grenze stückweise linearer Kurven konstruiert. Die Länge der
Die Kurve ist
 Die Kurve ist
Die Kurve ist dh die Länge wächst exponentiell mit
 dh die Länge wächst exponentiell mit
dh die Länge wächst exponentiell mit , obwohl jede Kurve in einem Quadrat mit Fläche enthalten ist
.
 .
.
-

Hilbert-Kurve erster Ordnung
-

Hilbert-Kurven erster und zweiter Ordnung
-

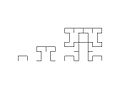
Hilbert-Kurven erster bis dritter Ordnung
-
-

Hilbert-Kurve, Konstruktion farbcodiert
-

Eine 3-D-Hilbert-Kurve mit Farbverlauf
-
Variante, erste drei Iterationen[3]
-

Foto eines David Hilbert mit der siebten Ordnung einer Hilbert-Kurve.
Anwendungen und Mapping-Algorithmen[edit]
Sowohl die wahre Hilbert-Kurve als auch ihre diskreten Näherungen sind nützlich, da sie eine Abbildung zwischen 1D- und 2D-Raum ergeben, bei der die Lokalität ziemlich gut erhalten bleibt.[4] Dies bedeutet, dass zwei Datenpunkte, die im eindimensionalen Raum nahe beieinander liegen, nach dem Falten ebenfalls nahe beieinander liegen. Das Gegenteil kann nicht immer wahr sein.
Aufgrund dieser Lokalitätseigenschaft ist die Hilbert-Kurve in der Informatik weit verbreitet. Beispielsweise kann der von Computern verwendete IP-Adressbereich mithilfe der Hilbert-Kurve in ein Bild abgebildet werden. Code zum Erzeugen des Bildes wird von 2D auf 1D abgebildet, um die Farbe jedes Pixels zu ermitteln, und die Hilbert-Kurve wird manchmal verwendet, weil sie nahegelegene IP-Adressen im Bild nahe beieinander hält.
Ein Graustufenfoto kann mithilfe von Schwellenwerten in ein gedithertes Schwarzweißbild konvertiert werden, wobei der verbleibende Betrag von jedem Pixel zum nächsten Pixel entlang der Hilbert-Kurve addiert wird. Code, um dies zu tun, würde von 1D nach 2D abgebildet, und die Hilbert-Kurve wird manchmal verwendet, weil sie nicht die ablenkenden Muster erzeugt, die für das Auge sichtbar wären, wenn die Reihenfolge einfach von links nach rechts über jede Pixelreihe wäre. Hilbert-Kurven in höheren Dimensionen sind ein Beispiel für eine Verallgemeinerung von Gray-Codes und werden manchmal aus ähnlichen Gründen für ähnliche Zwecke verwendet. Für mehrdimensionale Datenbanken wurde vorgeschlagen, die Hilbert-Reihenfolge anstelle der Z-Reihenfolge zu verwenden, da sie ein besseres lokalitätserhaltendes Verhalten aufweist. Beispielsweise wurden Hilbert-Kurven verwendet, um R-Baum-Indizes zu komprimieren und zu beschleunigen[5] (siehe Hilbert R-Baum). Sie wurden auch verwendet, um Data Warehouses zu komprimieren.[6][7]
Angesichts der Vielzahl von Anwendungen ist es nützlich, Algorithmen zu haben, um in beide Richtungen abzubilden. In vielen Sprachen sind diese besser, wenn sie eher mit Iteration als mit Rekursion implementiert werden. Der folgende C-Code führt die Zuordnungen in beide Richtungen aus, wobei Iterations- und Bitoperationen anstelle von Rekursion verwendet werden. Es wird ein Quadrat angenommen, das in unterteilt ist n durch n Zellen, z n eine Potenz von 2 mit ganzzahligen Koordinaten mit (0,0) in der unteren linken Ecke, (n – 1, n – 1) in der oberen rechten Ecke und in einiger Entfernung d das beginnt bei 0 in der unteren linken Ecke und geht zu
in der unteren rechten Ecke. Dies unterscheidet sich von der oben gezeigten Animation, bei der die Kurve in der oberen linken Ecke beginnt und in der oberen rechten Ecke endet.
 in der unteren rechten Ecke. Dies unterscheidet sich von der oben gezeigten Animation, bei der die Kurve in der oberen linken Ecke beginnt und in der oberen rechten Ecke endet.
in der unteren rechten Ecke. Dies unterscheidet sich von der oben gezeigten Animation, bei der die Kurve in der oberen linken Ecke beginnt und in der oberen rechten Ecke endet.
//convert (x,y) to d
int xy2d (int n, int x, int y) {
int rx, ry, s, d=0;
for (s=n/2; s>0; s/=2) {
rx = (x & s) > 0;
ry = (y & s) > 0;
d += s * s * ((3 * rx) ^ ry);
rot(n, &x, &y, rx, ry);
}
return d;
}
//convert d to (x,y)
void d2xy(int n, int d, int *x, int *y) {
int rx, ry, s, t=d;
*x = *y = 0;
for (s=1; s<n; s*=2) {
rx = 1 & (t/2);
ry = 1 & (t ^ rx);
rot(s, x, y, rx, ry);
*x += s * rx;
*y += s * ry;
t /= 4;
}
}
//rotate/flip a quadrant appropriately
void rot(int n, int *x, int *y, int rx, int ry) {
if (ry == 0) {
if (rx == 1) {
*x = n-1 - *x;
*y = n-1 - *y;
}
//Swap x and y
int t = *x;
*x = *y;
*y = t;
}
}
Diese verwenden die C-Konventionen: Das & -Symbol ist ein bitweises UND, das ^ -Symbol ist ein bitweises XOR, der Operator + = fügt einer Variablen hinzu und der Operator / = teilt eine Variable. Die Behandlung von Booleschen Werten in C bedeutet, dass in xy2d die Variable rx wird auf 0 oder 1 gesetzt, um mit dem Bit übereinzustimmen s von xund ähnlich für ry.
Die xy2d-Funktion arbeitet von oben nach unten und beginnt mit den höchstwertigen Bits von x und yund Aufbau der wichtigsten Teile von d zuerst. Die Funktion d2xy arbeitet in umgekehrter Reihenfolge, beginnend mit den niedrigstwertigen Bits von dund aufbauen x und y beginnend mit den niedrigstwertigen Bits. Beide Funktionen verwenden die Rotationsfunktion, um die (x,y) Koordinatensystem entsprechend.
Die beiden Mapping-Algorithmen arbeiten auf ähnliche Weise. Das gesamte Quadrat besteht aus 4 Regionen, die 2 mal 2 angeordnet sind. Jede Region besteht aus 4 kleineren Regionen usw. für eine Reihe von Ebenen. Auf Ebene sist jede Region s durch s Zellen. Es gibt eine einzelne FOR-Schleife, die durch Ebenen iteriert. Bei jeder Iteration wird ein Betrag hinzugefügt d oder zu x und y, bestimmt durch welche der 4 Regionen es sich auf dem aktuellen Niveau befindet. Die aktuelle Region von den 4 ist (rx,ry), wo rx und ry sind jeweils 0 oder 1. Es werden also 2 Eingangsbits verbraucht (entweder 2 von d oder je 1 von x und y) und erzeugt zwei Ausgangsbits. Es ruft auch die Rotationsfunktion auf, so dass (x,y) wird für die nächste Ebene bei der nächsten Iteration geeignet sein. Bei xy2d beginnt es auf der obersten Ebene des gesamten Quadrats und arbeitet sich bis zur untersten Ebene einzelner Zellen vor. Bei d2xy beginnt es unten mit Zellen und schließt das gesamte Quadrat ein.
Hilbert-Kurven können auch dann effizient implementiert werden, wenn der Datenraum kein Quadrat bildet.[8] Darüber hinaus gibt es mehrere mögliche Verallgemeinerungen von Hilbert-Kurven auf höhere Dimensionen.[9][10]
Darstellung als Lindenmayer-System[edit]
Die Hilbert-Kurve kann durch ein Umschreibesystem (L-System) ausgedrückt werden.
- Alphabet : A, B.
- Konstanten : F + –
- Axiom : EIN
- Produktionsregeln::
- A → + BF – AFA – FB +
- B → −AF + BFB + FA−
Hier bedeutet “F” “vorwärts ziehen”, “+” bedeutet “um 90 ° nach links drehen”, “-” bedeutet “um 90 ° nach rechts drehen” (siehe Schildkrötengrafiken) und “A” und “B” werden beim Zeichnen ignoriert .
Andere Implementierungen[edit]
Graphics Gems II[11] diskutiert die Hilbert-Kurvenkohärenz und stellt die Implementierung bereit.
Die Hilbert-Kurve wird häufig beim Rendern von Bildern oder Videos verwendet. Gängige Programme wie Blender und Cinema 4D verwenden die Hilbert-Kurve, um die Objekte zu verfolgen und die Szene zu rendern.
Siehe auch[edit]
- ^ D. Hilbert: Über die stetige Abbildung einer Linie auf ein Flächenstück. Mathematische Annalen 38 (1891), 459–460.
- ^ G.Peano: Sur une courbe, qui remplit toute une aire plane. Mathematische Annalen 36 (1890), 157–160.
- ^ Bourges, Pascale. “”Kapitel 1: Fraktale“, Fractales et Chaos. Zugriff: 9. Februar 2019.
- ^ Moon, B.; Jagadish, HV; Faloutsos, C.; Saltz, JH (2001), “Analyse der Clustering-Eigenschaften der Hilbert-Raumfüllungskurve”, IEEE-Transaktionen zu Knowledge and Data Engineering, 13 (1): 124–141, CiteSeerX 10.1.1.552.6697, doi:10.1109 / 69.908985.
- ^ I. Kamel, C. Faloutsos, Hilbert R-Baum: Ein verbesserter R-Baum unter Verwendung von Fraktalen, in: Proceedings der 20. Internationalen Konferenz über sehr große Datenbanken, Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 1994, S. 500–509.
- ^ Eavis, T.; Cueva, D. (2007). Eine Hilbert-Space-Compression-Architektur für Data Warehouse-Umgebungen. Vorlesungsunterlagen in Informatik. 4654. S. 1–12. doi:10.1007 / 978-3-540-74553-2_1. ISBN 978-3-540-74552-5.
- ^ Lemire, Daniel; Kaser, Owen (2011). “Spalten für kleinere Indizes neu anordnen”. Informationswissenschaften. 181 (12): 2550–2570. arXiv:0909.1346. doi:10.1016 / j.ins.2011.02.002. S2CID 15253857.
- ^ Hamilton, CH; Rau-Chaplin, A. (2007). “Kompakte Hilbert-Indizes: Raumfüllende Kurven für Domänen mit ungleichen Seitenlängen”. Informationsverarbeitungsbriefe. 105 (5): 155–163. doi:10.1016 / j.ipl.2007.08.034.
- ^ Alber, J.; Niedermeier, R. (2000). “Auf mehrdimensionalen Kurven mit Hilbert-Eigenschaft”. Theorie der Computersysteme. 33 (4): 295–312. CiteSeerX 10.1.1.7.2039. doi:10.1007 / s002240010003. S2CID 788382.
- ^ HJ Haverkort, F. van Walderveen, Vierdimensionale Hilbert-Kurven für R-Bäume, in: Proceedings of the Eleventh Workshop on Algorithm Engineering and Experiments, 2009, S. 63–73.
- ^ Voorhies, Douglas: Raumfüllende Kurven und ein Maß für die Kohärenz, S. 26–30, Graphics Gems II.
Weiterführende Literatur[edit]
Externe Links[edit]
Recent Comments