Externer Speicheralgorithmus – Wikipedia
Beim Rechnen, externe Speicheralgorithmen oder Out-of-Core-Algorithmen sind Algorithmen, die darauf ausgelegt sind, Daten zu verarbeiten, die zu groß sind, um auf einmal in den Hauptspeicher eines Computers zu passen. Solche Algorithmen müssen optimiert werden, um effizient Daten abzurufen und darauf zuzugreifen, die in langsamen Massenspeichern (Hilfsspeicher) wie Festplatten oder Bandlaufwerken gespeichert sind, oder wenn sich der Speicher in einem Computernetzwerk befindet.[1][2] Externe Speicheralgorithmen werden in der externes Speichermodell.
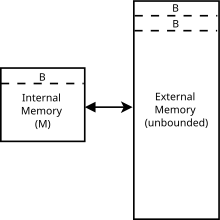


Externe Speicheralgorithmen werden in einem idealisierten Berechnungsmodell analysiert, das als externes Speichermodell (oder E/A-Modell, oder Festplattenzugriffsmodell). Das externe Speichermodell ist eine abstrakte Maschine ähnlich dem RAM-Maschinenmodell, jedoch mit einem Cache zusätzlich zum Hauptspeicher. Das Modell erfasst die Tatsache, dass Lese- und Schreibvorgänge in einem Cache viel schneller sind als im Hauptspeicher, und dass das Lesen langer zusammenhängender Blöcke schneller ist als das zufällige Lesen mit einem Platten-Lese- und Schreibkopf. Die Laufzeit eines Algorithmus im externen Speichermodell wird durch die Anzahl der erforderlichen Lese- und Schreibvorgänge im Speicher definiert.[3] Das Modell wurde 1988 von Alok Aggarwal und Jeffrey Vitter vorgestellt.[4] Das externe Speichermodell bezieht sich auf das Cache-Oblivious-Modell, aber Algorithmen im externen Speichermodell können sowohl die Blockgröße als auch die Cachegröße kennen. Aus diesem Grund wird das Modell manchmal als bezeichnet Cache-fähiges Modell.[5]
Das Modell besteht aus einem Prozessor mit einem internen Speicher oder Cache der Größe m, verbunden mit einem unbegrenzten externen Speicher. Sowohl der interne als auch der externe Speicher sind in Größenblöcke unterteilt B. Eine Eingabe/Ausgabe- oder Speicherübertragungsoperation besteht darin, einen Block von B zusammenhängende Elemente vom externen zum internen Speicher, und die Laufzeit eines Algorithmus wird durch die Anzahl dieser Ein-/Ausgabeoperationen bestimmt.[4]
Algorithmen[edit]
Algorithmen im externen Speichermodell nutzen die Tatsache, dass beim Abrufen eines Objekts aus dem externen Speicher ein ganzer Block der Größe abgerufen wird
. Diese Eigenschaft wird manchmal als Lokalität bezeichnet.
Auf der Suche nach einem Element unter
Objekte ist im externen Speichermodell über einen B-Baum mit Verzweigungsfaktor möglich
 Objekte ist im externen Speichermodell über einen B-Baum mit Verzweigungsfaktor möglich
Objekte ist im externen Speichermodell über einen B-Baum mit Verzweigungsfaktor möglich . Mit einem B-Baum können Suchen, Einfügen und Löschen in . erreicht werden
Zeit (in Big O-Notation). Information Theoretisch ist dies die minimal mögliche Laufzeit für diese Operationen, so dass die Verwendung eines B-Baums asymptotisch optimal ist.[4]
 Zeit (in Big O-Notation). Information Theoretisch ist dies die minimal mögliche Laufzeit für diese Operationen, so dass die Verwendung eines B-Baums asymptotisch optimal ist.[4]
Zeit (in Big O-Notation). Information Theoretisch ist dies die minimal mögliche Laufzeit für diese Operationen, so dass die Verwendung eines B-Baums asymptotisch optimal ist.[4]Externes Sortieren ist das Sortieren in einer externen Speichereinstellung. Die externe Sortierung kann über die Verteilungssortierung, ähnlich wie bei Quicksort, oder über a . erfolgen
-way Merge sortieren. Beide Varianten erreichen die asymptotisch optimale Laufzeit von
Sortieren n Objekte. Diese Schranke gilt auch für die schnelle Fourier-Transformation im externen Speichermodell.[2]
 Sortieren
Sortieren Das Permutationsproblem besteht darin, neu anzuordnen
Elemente in eine bestimmte Permutation. Dies kann entweder durch Sortieren erfolgen, was die obige Sortierlaufzeit erfordert, oder indem jedes Element der Reihe nach eingefügt wird und der Vorteil der Lokalität ignoriert wird. Somit kann die Permutation in erfolgen
Zeit.
 Zeit.
Zeit.
Anwendungen[edit]
Das externe Speichermodell erfasst die Speicherhierarchie, die in anderen gängigen Modellen, die beim Analysieren von Datenstrukturen verwendet werden, wie etwa der Direktzugriffsmaschine, nicht modelliert wird, und ist nützlich, um untere Grenzen für Datenstrukturen zu beweisen. Das Modell ist auch nützlich für die Analyse von Algorithmen, die mit Datensätzen arbeiten, die zu groß sind, um in den internen Speicher zu passen.[4]
Ein typisches Beispiel sind geografische Informationssysteme, insbesondere digitale Höhenmodelle, bei denen der vollständige Datensatz leicht mehrere Gigabyte oder sogar Terabyte an Daten überschreitet.
Diese Methodik geht über Allzweck-CPUs hinaus und umfasst auch GPU-Computing sowie klassische digitale Signalverarbeitung. Im Allzweck-Computing auf Grafikprozessoren (GPGPU) werden leistungsstarke Grafikkarten (GPUs) mit wenig Speicher (im Vergleich zum bekannteren Systemspeicher, der meist einfach als RAM bezeichnet wird) mit relativ langsamer CPU-zu- GPU-Speichertransfer (im Vergleich zur Rechenbandbreite).
Geschichte[edit]
Eine frühe Verwendung des Begriffs “out-of-core” als Adjektiv bezieht sich 1962 auf Geräte die nicht der Kernspeicher einer IBM 360 sind.[6] Eine frühe Verwendung des Begriffs “out-of-core” in Bezug auf Algorithmen erscheint 1971.[7]
Siehe auch[edit]
Verweise[edit]
- ^ Vitter, JS (2001). „Externe Speicheralgorithmen und Datenstrukturen: Umgang mit MASSIVE DATA“. ACM-Computing-Umfragen. 33 (2): 209–271. CiteSeerX 10.1.1.42.7064. mach:10.1145/384192.384193.
- ^ ein B Vitter, JS (2008). Algorithmen und Datenstrukturen für externen Speicher (PDF). Grundlagen und Trends in der Theoretischen Informatik. Reihe zu Grundlagen und Trends in der Theoretischen Informatik. 2. Hannover, MA: Jetzt Verlage. S. 305–474. CiteSeerX 10.1.1.140.3731. mach:10.1561/0400000014. ISBN 978-1-60198-106-6.
- ^ Zhang, Donghui; Tsotras, Vassilis J.; Levialdi, Stefano; Grinstein, Georges; Berry, Damon Andrew; Gouet-Brunet, Valerie; Kosch, Harald; Döller, Mario; Döller, Mario; Kosch, Harald; Maier, Paul; Bhattacharya, Arnab; Ljosa, Vebjörn; Nack, Frank; Bartolini, Ilaria; Gouet-Brunet, Valerie; Mei, Tao; Rui, Yong; Crucianu, Michel; Shih, Frank Y.; Fan, Wenfei; Ullman-Cullere, Mollie; Clark, Eugen; Aronson, Samuel; Mellin, Jonas; Berndtsson, Mikael; Grahne, Gösta; Bertossi, Leopoldo; Dong, Guozhu; et al. (2009). “I/O-Modell der Berechnung”. Enzyklopädie der Datenbanksysteme. Springer Wissenschaft+Wirtschaftsmedien. S. 1333–1334. mach:10.1007/978-0-387-39940-9_752. ISBN 978-0-387-35544-3.
- ^ ein B C D Aggarwal, Alok; Vitter, Jeffrey (1988). “Die Eingabe-/Ausgabekomplexität der Sortierung und damit verbundene Probleme”. Mitteilungen des ACM. 31 (9): 1116-1127. mach:10.1145/48529.48535.
- ^ Demaine, Erik (2002). Cache-Oblivious Algorithmen und Datenstrukturen (PDF). Vorlesungsnotizen der EEF Summer School zu Massive Data Sets. Arhus: BRICS.
- ^ NASA SP. NASA. 1962. p. 276.
- ^ Computer in der Krise. ACM. 1971. p. 296.
Externe Links[edit]
Recent Comments