情報検索 – ウィキペディア
情報検索 [ ˌɪnfɚmeɪʃanɹɪtɹif ]( と )主にデータベースから電話をかけることにより、情報の回復に関するものです。スペシャリストエリアは、コンピューターが複雑なコンテンツの検索を扱っています(つまり、個々の単語についてはそうではありません)。 [初め] 。
大規模なデータベースに保存されている複雑なテキストまたは画像データは、最初はアクセスできないか、部外者が利用できます。言葉 検索 ドイツ語での手段 電話 また。 解決 。だから、irはについてです 既存 もう一度情報を見つける。何か他のものが発見されます ニュース 構造:これは、データマイニングとテキストマイニングを備えたデータベースの知識発見に属します。
ドキュメント検索は密接に関連しており、これは主に(テキスト)ドキュメントを決定すべき情報として目指しています。
IRメソッドは、たとえば、インターネット検索エンジン(Googleなど)で使用されます。また、デジタルライブラリ(文学の検索など)や画像検索エンジンでも使用されます。または、テクニックは応答システムまたはスパムフィルターも使用します。
複雑な情報を開くことは困難です。
- 不確実性:データベースでは、含まれるドキュメントの内容に関する情報が保存されていない可能性があります(テキスト、画像、映画、音楽など)。システムに尋ねると、貧弱になり、正しくなく、回答がなくなります。テキストには不足がありますB.ホモグラファーの説明(すぐに書かれた言葉;例:銀行 – 金融機関、座席)および同義語(銀行および金融機関)。
- gagheit:ユーザーは、探している情報の種類を正確でターゲットを絞った検索用語(リレーショナルデータベースのSQLなど)で配置することはできません。したがって、彼の検索クエリには曖昧な条件が含まれています。
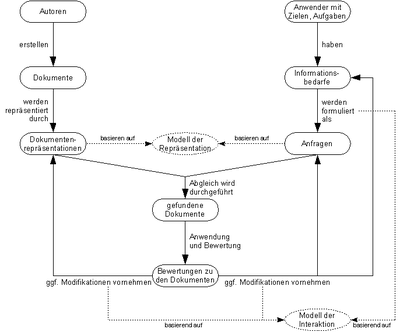
一般に、2つの(おそらく重複する)個人グループがIRに関与しています(右の図を参照)。
人々の最初のグループは、IRシステムに保存されている情報の著者であり、自分自身を保存するか、他の情報システムに読み上げてもらうことができます(インターネット検索エンジンを練習できます)。システムに設定されたドキュメントは、ドキュメントをフォーム(ドキュメント表現)に表現するシステム内モデルに従って、IRシステムによって変換されます。これは、処理に有利です)。
2番目のユーザーグループであるユーザーは、IRシステムで作業した時点で特定の目標またはタスクを持っています。ユーザーは、システムの助けを借りてこれらの情報のニーズをカバーしたいと考えています。これを行うには、お問い合わせとして十分な形式で情報のニーズを策定する必要があります。
情報のニーズを策定する必要があるフォームは、ドキュメントの表現で使用されるモデルによって異なります。相互作用のモデルは、システムとの相互作用として情報をモデル化するプロセス(たとえば、検索用語を入力しやすい方法として)を決定します。
問い合わせが策定されている場合、IRシステムのタスクは、ドキュメント表現を使用してシステムに設定されたドキュメントと問い合わせを比較し、問い合わせに一致するドキュメントのリストを返すことです。ユーザーは、ソリューションの関連性に対するタスクに従って見られるドキュメントを評価するタスクに直面しています。結果は、ドキュメントのレビューです。
次に、ユーザーには3つのオプションがあります。
- ドキュメントの表現を(通常は緊密なフレームでのみ)変更できます(たとえば、ドキュメントのインデックス作成の新しいキーワードを定義することにより)。
- 彼らは定式化された問い合わせを改良します(主に検索結果をさらに制限するため)
- 調査を実施した後、タスクを解決するために関連するものとして分類されていない他の情報が必要であることがわかるため、情報のニーズを変更します。
3つの変更フォームの正確なプロセスは、相互作用のモデルによって決定されます。たとえば、明示的な(つまり、あらゆる形式のユーザーのシステム)を使用してリクエストを自動的に改革することにより、リクエストの再定式化にユーザーをサポートするシステムがあります。
「情報検索」という用語は、1950年にCalvin N. Mooersによって最初に使用されました。 1945年にエッセイで説明されたヴァンネヴァーブッシュ 私たちが考えるかもしれないように アトランティックマンスリーでは、知識ストレージを使用して既存の知識の使用にどのように革命をもたらすことができますか。彼のビジョンはMemexと呼ばれていました。このシステムは、あらゆる種類の知識を保存し、ターゲットを絞った検索を有効にし、左を使用してドキュメントを閲覧できるようにする必要があります。ブッシュはすでに検索エンジンの使用と検索ツールの使用を考えていました。
情報科学は、Sputnikschocksから重要な後押しを受けました。一方では、ロシアの衛星には、宇宙研究における独自の後方性が含まれていました。これは、アポロプログラムによって正常に排除されました。一方、それが情報科学の重要なポイントでした – Sputnik信号コードをクラックするのに半年かかりました。ロシアの雑誌の復号化コードは長い間読まれてきましたが、すでにアメリカの図書館にありました。
したがって、より多くの情報がより多くの情報につながることはありません。それどころか。いわゆるブドウ園レポートは、この問題について大統領から委託された専門家の意見です。 Vineyardの報告書は、「情報爆発」に関する報告であり、この情報爆発に対処するために専門家が必要であると説明しています。だから情報科学者。
Hans Peter Luhnは、1950年代にテキスト統計的手順に取り組みました。これは、自動要約とインデックス作成の基礎でした。彼の目標は、個々の情報プロファイルを作成し、中毒を強調することでした。プッシュサービスのアイデアが生まれました。
ユージン・ガーフィールドは、雑誌に情報のさまざまな伝達方法を反映するために、1950年代に引用に取り組みました。これを行うために、彼は内容をコピーしました。 1960年、彼は最初の商業回収システムの1つである科学情報研究所(ISI)を設立しました。
サルトン、ジェラルド。 McGill、Michael J.現代情報検索の紹介。 McGraw-Hill、1983年。
ドイツ [ 編集 | ソーステキストを編集します ]
ドイツでは、シーメンスは2つのシステム、ゴーレム(大規模なストーリー指向、リスト主導の調査方法)とPassat(テキストからキーワードの自動選択のためのプログラム)を開発しました。 Passatは、ストップワードを除外し、辞書を使用して単語の茎を形成し、依存症に重み付けします。
情報科学は1960年代から確立されていると考えられてきました。
初期の商業情報サービス [ 編集 | ソーステキストを編集します ]
ダイアログは、Roger K. Summitによって開発されたManとMachineの間のインタラクティブなシステムです。それは経済的に指向されており、1972年に政府のデータベースエリックとNTISを通じてオンラインになります。
Oribitプロジェクト(今日のQuestel-Orbit)は、Carlos A. Cuadraの指示の下で研究開発によって促進されました。 1962年、検索システムはオンラインでCIRCとさまざまなテストの実行がコード名Colexで行われました。コレックスは軌道の直接的な先駆者であり、1967年には米国空軍によるオンラインの研究に焦点を当てています。後に医療情報に焦点を当てます。 Medline Search Systemは、1974年に書誌メディックデータベースMedlarsのオンラインになりました。
OBARは、1965年にオハイオ州の法律室によって開始されたプロジェクトです。 LexisNexisシステムで終了し、法的情報に焦点を当てています。このシステムは、オハイオ州の判断に最適に機能する全文検索に基づいています。
World Wide Webでツールを検索します [ 編集 | ソーステキストを編集します ]
インターネットを使用すると、情報検索は質量現象になります。先駆者はWAISシステムであり、1991年から広く普及していたため、インターネット上での分散検索を可能にしました。初期のWebブラウザNCSAモザイクとNetscape Navigatorは、インターネット検索エンジンがオープンし、後に非HTMLドキュメントにインデックスを作成する前にWAISプロトコルをサポートしています。 GoogleとBingは現在、最も有名で最も人気のある検索エンジンの1つです。イントラネットの拡散検索エンジンは、自律性、コンバラ、高速、真vity、およびオープンソースのソフトウェアApache Luceneです。
情報要件 [ 編集 | ソーステキストを編集します ]
情報の必要性は、アクションに関連する知識の必要性であり、具体的で問題指向になる可能性があります。特定の情報のニーズに関しては、事実情報が必要です。たとえば、「フランスの首都は何ですか?」答え「パリ」は、情報の必要性を完全にカバーしています。問題指向の情報とは異なります。ここでは、必要性を母乳で育てるためにいくつかの文書が必要です。さらに、情報指向の情報の必要性は、完全にカバーされることはありません。必要に応じて、得られた情報は、新しいニーズまたは元のニーズの変更をもたらします。
情報に関しては、ユーザーは抽象化されます。これは、客観的な事実が考慮されることを意味します。
情報のニーズ [ 編集 | ソーステキストを編集します ]
情報の必要性は、リクエストユーザーの特定のニーズを反映しています。それはユーザーの主観的なニーズについてです。
情報インデックス作成と情報検索 [ 編集 | ソーステキストを編集します ]
可能な限り正確に検索クエリを策定できるようにするには、実際にあなたが知らないことを知る必要があります。したがって、適切な検索クエリを作成するための基本的な知識が必要です。さらに、自然言語検索クエリは、検索システムで読み取ることができるバリアントに変換する必要があります。
さまざまなデータベースでの検索問い合わせの例をいくつか紹介します。映画「ショコラ」の俳優「ジョニー・デップ」に関する情報を探しています。
lexisnexis:
見出し:(„ジョニー・デップ「w/5„ショコラ」)
ダイアログ:
(ジョニー・インド・デップとショコラ)の
グーグル:
「ショコラ」「ジョニー・デップ」
ユーザーは、検索プロセスの仕組みを指定します。これは、使用されるシステムでの検索質問者の定式化の方法によるものです。単語指向のシステムと任期指向のシステムを区別する必要があります。用語指向のシステムは、単語のあいまいさを認識できます(たとえば、Java = The Island、Java = The CoffeeまたはJava =プログラミング言語)。
ドキュメントユニット(DE)は、検索クエリを介してアドレス指定されます。 DEは、ドキュメントの情報付加価値を表します。これは、著者、生まれなどに関する情報が再現されていることを意味します。データベースに応じて、完全なドキュメントまたはその一部のみが記録されます。
ドキュメンタリーリファレンスユニットとドキュメントユニット [ 編集 | ソーステキストを編集します ]
ドキュメンタリーリファレンスユニット(DBE)もドキュメントユニット(DE)も元のドキュメントではありません。どちらもデータベースで同じ代表者のみです。
まず、ドキュメントに値するドキュメントがチェックされます。これは、正式およびコンテンツ関連の基準のカタログを通じて行われます。オブジェクトがそれだけの価値があることがわかった場合、DBEが作成されます。ここでは、ドキュメントが保存される形式で決定されます。個々の章やページは、DBEまたはドキュメント全体として撮影されていますか?
実用的なプロセスが続きます。 DBEは正式に記述され、コンテンツが圧縮されます。この情報付加価値は、DEのDEの代理人として機能するDEで見つけることができます。 DEはDBEを表すため、ドキュメントプロセスの最後にあります。
DEは、ユーザーにDBEを使用して要求できるかどうかを決定するようにサービスを提供します。
情報の検索と情報のインデックス作成が調整されます。
認知モデル [ 編集 | ソーステキストを編集します ]
これらは、以前の知識、社会経済的背景、言語スキルなどを参照しているため、経験的情報科学の一部です。ユーザーとそれらを使用して情報、ユーザー、ユーザーの分析を提供します。
サービスをプルとプッシュします [ 編集 | ソーステキストを編集します ]
Marcia J. Batesは、情報の検索をBerrypicking(ドイツ語)として説明しています。 ベリーピッキング )。バスケットがいっぱいになるように、低木やデータベースのベリーや情報のみを検索するだけでは十分ではありません。いくつかのデータベースを要求する必要があり、新しい情報に基づいて検索クエリを常に変更する必要があります。
ユーザーが情報を積極的に検索できる場所では、どこでもプルサービスが利用可能になります。
プッシュサービスは、保存された情報プロファイルのためにユーザーに情報を提供します。これらのプロファイルサービスは、警告されたアラートで、正常に処方された検索クエリを保存し、新しい関連ドキュメントの到着についてユーザーに通知します。
情報障壁 [ 編集 | ソーステキストを編集します ]
さまざまな要因が情報の流れを妨げます。このような要因は、たとえば、時間、場所、言語、法律、資金調達です。
リコールと精度 [ 編集 | ソーステキストを編集します ]
リコールは、表示されたスコアの完全性を示します。一方、精度は、ヒット数量から検索クエリまでのドキュメントの精度を計算します。
精度とは、検索クエリの選択されたドキュメントのすべての関連ドキュメントの割合を指し、したがって、意味のあるドキュメントのタスクに関するヒットリストに含まれる範囲の範囲です。一方、リコールは、ドキュメントコレクションの関連文書の総数におけるすべての関連ドキュメントの割合を説明しています。これは、ヒットリストの完全性の尺度です。両方の寸法は、情報検索システムの重要なキー図を形成します。理想的なシステムは、適用されないドキュメントを除外して、検索クエリでドキュメントコレクションのすべての関連ドキュメントを選択します。
想起:

精度:

A =見つかった、関連するヒット
b =発見された、非関連性DE /バラスト
c =発見されていなかった関連DE /損失
「C」は、データベースまたはDEのコンテンツがわからない場合、検索クエリに基づいて報告されるべきDEのコンテンツを知らない場合、「C」は直接測定できません。
リコールは、精度を犠牲にして拡大することができ、その逆も同様です。ただし、これは事実の質問には当てはまりません。ここにリコールと精度があります。
知識は関連する場合がありますが、誤っている必要はありません。関連性とは、策定された検索クエリに基づくドキュメントが試合に発行されたことを意味します。ユーザーが既にテキストを知っている場合、または著者が好きではないか、別の言語で記事を読みたくないために読みたくない場合、ドキュメントは該当しません。適切なのは、ユーザーの主観的なビューが含まれます。
| 客観的な情報要件 | 情報の主観的なニーズ(=情報のリクエスト) |
| →関連性 | →Pedinen |
| ドキュメントは、客観的に情報要件を満たすために関連しています。 | ドキュメントは、主観的に以下の場合、情報の必要性を満たすことです。 |
| 決定を準備するのに役立ちます | 決定を準備するのに役立ちます |
| 知識のギャップが閉じます | 知識のギャップが閉じます |
| 早期警告機能が満たされました | 早期警告機能が満たされました |
情報検索を成功させるための前提条件は、適切なタイミングで、適切な場所、右側、適切な形で適切な品質を備えた適切な知識です。 「正しく」ということは、この知識が適切または関連性のいずれかを持っていることを意味します。
使いやすさ [ 編集 | ソーステキストを編集します ]
知識は、ユーザーが新しい知識に関連する知識を作成し、それを実践する場合に役立ちます。
関連性の側面 [ 編集 | ソーステキストを編集します ]
関連性とは、トピックに関連する検索クエリ(クエリ)とシステムの側面との関係です。
バイナリアプローチ [ 編集 | ソーステキストを編集します ]
バイナリアプローチでは、ドキュメントは関連性があるか関連していないと述べています。実際には、これは必ずしも正しいとは限りません。ここでは、「関連性領域」をもっと話します。
関連性分布 [ 編集 | ソーステキストを編集します ]
たとえば、トピックチェーンを形成できます。 1つのトピックがいくつかのチェーンで発生する可能性があります。問題が発生することが多いほど、その重みの値が大きくなります。トピックがすべてのチェーンで発生する場合、その値は100です。 0のチェーンでは発生しません。
調査では3つの異なる分布が現れています。これらの分布は、大量のドキュメントでのみ発生することに注意する必要があります。少量のドキュメントでは、規則性がない場合があります。
バイナリ分布 [ 編集 | ソーステキストを編集します ]
バイナリ分布に関連性のある食堂はありません。
インバーロジー科の分布 [ 編集 | ソーステキストを編集します ]

- :Rangplatz
- :Eulersche番号
- :永続的に




情報配信 [ 編集 | ソーステキストを編集します ]

- :Rangplatz
- :永続的に
- :1〜2の間の具体的な値

有益な分布による:最初の配置されたドキュメントが1つの関連性を持っている場合(で
)、2番目の配置ドキュメントの関連性は0.5です(
 )、2番目の配置ドキュメントの関連性は0.5です(
)、2番目の配置ドキュメントの関連性は0.5です( または0.25から(at
 または0.25から(at
または0.25から(at )。
 )。
)。 開始ドキュメント、DBEとDEの間に区別が行われることを再度指摘する必要があります。
しかし、「何か」が実際にドキュメントであるのはいつですか?これは、4つの基準が決定するものです。重要性(デジタル存在を含む)、意図性(ドキュメントには一定の感覚、意味があります)、開発、認識があります。
- 「彼らは文書にしなければならない」 マイケル・K・バックランド
テキストおよび非テキストオブジェクト [ 編集 | ソーステキストを編集します ]
オブジェクトはテキスト形式で発生する可能性がありますが、そうする必要はありません。画像と映画は、非テキスト文書の例です。テキストおよび非テキストオブジェクトは、デジタルおよび非デジタルの形で発生する可能性があります。それらがデジタルであり、3つ以上のメディアフォームを満たしている場合(ドキュメントは、たとえば、ビデオシーケンス、オーディオシーケンス、写真など)、マルチメディアと呼ばれます。非デジタルオブジェクトには、写真などのデータベースにデジタル代表が必要です。
正式に公開されたテキストドキュメント [ 編集 | ソーステキストを編集します ]
正式に公開されたテキストドキュメントはすべて、正式な出版プロセスを経た文書です。これは、ドキュメントが公開前(例:編集者によって)チェックされたことを意味します。 SO -CALLEDの「灰色の文学」は問題です。これはチェックされていますが、公開されていません。
正式に公開された文書にはいくつかのレベルがあります。最初は作品、著者の創造があります。この作業の表現、具体的な実装(例:異なる翻訳)。この実装は明らかにされています(例:本で)。このチェーンの下部には、個々の標本がアイテムです。原則として、DBEは症状に依存します。例外が可能です。
非公式に公開されたテキスト [ 編集 | ソーステキストを編集します ]
非公式に公開されたテキストには、インターネットで公開されたドキュメントが含まれています。これらのドキュメントは公開されていますが、チェックされていません。
たとえば、正式および非公式に公開されたテキストの中間レベルは、Wikisです。これらは公開され、協力的にチェックされます。
公開されていないテキスト [ 編集 | ソーステキストを編集します ]
これには、文字、請求書、内部レポート、イントラネットまたはエクストラネットに関するドキュメントが含まれます。公開されたことのないすべての文書。
非テキスト文書 [ 編集 | ソーステキストを編集します ]
非テキスト文書の2つのグループ間で区別が行われます。一方では、映画、写真、音楽などのデジタルで入手可能またはデジタル化可能なドキュメント、そして非デジタルおよび非桁のドキュメント。後者には、化学物質とその特性や反応、患者とその症状と博物館のオブジェクトなどの事実が含まれます。非誘導性文書のほとんどは、化学、医学、ビジネスの分野に由来しています。それらはデータベースのDEで表され、多くの場合、写真、ビデオ、オーディオファイルによっても表示されます。
テキストの構造 [ 編集 | ソーステキストを編集します ]
構造化された、弱く構造化されたテキストと非構造化されたテキストを区別します。弱く構造化されたテキストには、特定の構造を持つあらゆる種類のテキストドキュメントが含まれています。これには、章番号、タイトル、サブヘディング、イラスト、ページ番号などが含まれます。テキストは、テキスト構造データに追加できます。
非構造化されたテキストは、実際にはほとんど発生しません。情報科学では、主に弱く構造化されたテキストを扱っています。
構文構造ではなく、形式的なものであることに注意する必要があります。コンテンツのコンテキストには問題があります。
「男は望遠鏡で丘の上のピラミッドを見ました。」この文は4回解釈できます。したがって、一部のプロバイダーは、コンテキストを認識し、それを正しく処理できるため、人間のインデクサーを好みます。
情報検索システムは、用語制御の有無にかかわらず動作することができます。用語制御を使用すると、可能性は知的かつ自動的に発生します。用語制御なしで動作する検索システムは、純粋なテキストを処理するか、プロセスを自動処理で実行します。
検索システムと用語制御 [ 編集 | ソーステキストを編集します ]
用語制御とは、制御された語彙の使用にすぎないことを意味します。これは、ドキュメント言語(分類、キーワードメソッド、シソーリ、オントロジー)を介して行われます。利点は、研究者とインデクサーが同じ表現とオプションを持っていることです。したがって、同義語や同音異義語に問題はありません。制御された語彙の欠点は、たとえば、言語開発の考慮事項の欠如と、これらのアート言語がすべてのユーザーによって正しく適用されないという問題です。
価格は自然に別の役割を果たします。知的インデックスは、自動よりもはるかに高価です。
合計4つのケースを区別できます。
| 探偵 | インデクサー |
|---|---|
| 制御された語彙→専門家 | 制御された語彙 |
| 自然に→アッパーおよびサブタムを使用した検索リクエストの拡張を通じてバックグラウンドで制御された語彙 | 自然に→アッパーおよびサブタムを使用した検索リクエストの拡張を通じてバックグラウンドで制御された語彙 |
| 当然言語→システムは翻訳が機能します | 制御された語彙 |
| 制御された語彙 | 自然言語語彙 |
用語制御のないバリアントを使用すると、全文を操作するのが最善です。ただし、これは非常に小さなデータベースでのみ機能します。ドキュメントの用語は、ユーザーによって正確に知られている必要があります。
用語制御を備えたプロセスには、ドキュメントの情報言語処理(Natural Language Processing = NLP)が必要です。
情報言語テキスト処理 [ 編集 | ソーステキストを編集します ]
情報の言語テキスト処理は次のとおりです。ライティングシステムが最初に認識されます。たとえば、ラテン語またはアラビア語の執筆システムです。これに続いて、音声認識が続きます。これで、テキスト、レイアウト、ナビゲーションが互いに分離されます。この時点では2つのオプションがあります。一方では、単語のn-gramsまたは単語への分解。選択した方法に関係なく、単語マーキングを停止し、入力エラー検出と修正、独自の名前と基本的または通常のフォームの形成が続きます。 Compositaは分解され、同音異義語と同義語が認識され、比較され、類似性に応じて検査された意味環境または環境が比較されます。最後の2つの手順は、ドキュメントの翻訳とanaphora解像度です。
プロセス中にシステムがユーザーに接続する必要がある場合があります。
いくつかの競合する検索モデルがありますが、排除する必要はありません。これらのモデルには、ブールと拡張ブールモデルが含まれます。ベクトル空間モデルと確率モデルは、テキスト統計に基づいたモデルです。左翼モデルには、KleinbergアルゴリズムとPagerankが含まれます。最後に、特定の場所でテキストとユーザーの使用を調べるネットワークモデルとユーザー/使用モデルがあります。
BOOLESCHES Modell [ 編集 | ソーステキストを編集します ]
ジョージ・ブールは、1854年に彼の「ブールシュ・ロジック」と物事のバイナリビューを公開しました。彼のシステムには、3つの機能または演算子があります。このシステムでは、関連性の後にソートは不可能です。関連性のランキングを有効にするために、ブールモデルを拡張して重み付け値を含めるように拡張され、演算子を再解釈する必要がありました。
テキスト統計 [ 編集 | ソーステキストを編集します ]
テキスト統計では、ドキュメントで発生する用語が分析されます。重み係数は、WDFとIDFと呼ばれます。
ドキュメント内周波数(WDF):発生するすべての単語の用語/数の数
WDFは、ドキュメント内の単語の頻度について説明します。ドキュメントに単語が頻繁に表示されるほど、より大きなwdf
逆のドキュメント頻度 英語 逆ドキュメント周波数重量 (IDF) データベース内のドキュメントの総数/用語のドキュメントの数
IDFは、特定の用語のドキュメントがデータベースで発生する頻度を説明します。特定の用語を持つドキュメントがデータベースで発生することが多いほど、それは小さくなります。
テキスト統計の2つの古典的なモデルは、ベクタールームモデルと確率モデルです。
ベクターのモデルでは、nワード張力とn次元空間。互いに単語の類似性は、それらのベクトルの角度を介して計算されます。
確率モデルは、ドキュメントが検索クエリに適用される確率を計算します。追加情報がなければ、確率モデルはIDFに似ています。
左足モデル [ 編集 | ソーステキストを編集します ]
ドキュメントは、wwwで互いにリンクされています。それらは左から空間を形成します。
Kleinberg Algorithmは、これらのリンクを「ハブ」(発信リンク)と「権限」(着信リンク)と呼びます。加重値は、ハブが「良い」ハブからの「良い」当局の会議や当局にリンクされている範囲から生じます。
別の左足モデルは、セルゲイ・ブリンとローレンスのページのページランクです。サーフェンダーの側がページを見つける確率を説明します。
ClusterModell [ 編集 | ソーステキストを編集します ]
クラスターメソッドは、一般的なドキュメントプールに類似または関連するドキュメントが要約されるように、ドキュメントを分類しようとします。その結果、すべての関連ドキュメントを最良の場合に単一のアクセスで選択できるため、検索手順の加速が発生します。ドキュメントの類似点に加えて、同義語は意味的に類似した単語として重要な役割を果たします。 「単語」という用語の検索には、コメント、発言、請求、用語のヒットリストも提示する必要があります。
問題は、ドキュメントの概要の種類から発生します。
- クラスターは安定して完全でなければなりません。
- クラスター内のドキュメントの数、したがって結果のヒットリストは、均質なドキュメントを使用した特別なドキュメントで非常に高い場合があります。反対の場合、クラスターの数は極端なケースに成長する可能性があります。この場合、クラスターは1つのドキュメントのみで構成されています。
- 複数のクラスターにあるドキュメントのオーバーラップレートは、ほとんど制御できません。
ユーザー使用モデル [ 編集 | ソーステキストを編集します ]
ユーザーを使用すると、Webサイトを使用する頻度はランクの基準です。さらに、地理的問い合わせのために、背景情報がユーザーの場所に含まれています。
体系的な検索に関しては、フィードバックループがあります。これらは自動的に実行されるか、ユーザーが検索クエリが変更されて繰り返される前に、関連性または関連性がないとマークするように繰り返し求められます。
Surface WebとDeep Web [ 編集 | ソーステキストを編集します ]
Surface WebはWeb上にあり、すべてのユーザーに無料でアクセスできます。ディープウェブにはデータベースがあり、その検索表面はSurface Webを介して到達できます。ただし、情報は一般的に課金されます。
3種類の検索エンジンを区別できます。 Googleワークアルゴリズムなどの検索エンジンでは、Open Directoryプロジェクトは知的に作成されたWebカタログであり、Metasucheはコンテンツを対処している他のいくつかの検索エンジンから移動します。原則として、知的に作成されたWebカタログは、DBEの供給源としてWebサイトのエントリページのみを使用します。各Webサイトは、アルゴリズム的に動作する検索エンジンに使用されます。
急勾配のマップ、ライブラリカタログ、ビジュアルカードなど、デジタルおよび非デジタルのストレージメディアがあります。デジタルストレージメディアはコンピューターサイエンスによって開発されており、情報科学の雇用分野です。
ファイル構造とその関数は区別されます。さらに、ドキュメントとユーザーを備えた検索システムのインターフェイスがあります。システムとドキュメントの間のインターフェースでは、3つの領域が再び区別されます。ドキュメントを見つける、rawったということ、更新で見つかったこれらのドキュメントの制御、およびフィールドスキームの分類。ドキュメントは、知的または自動的に記録され、さらに処理されます。 DEは2回保存されます。ドキュメントファイルとして、また倒立ファイルとして、ドキュメントファイルへのアクセスをレジスタまたはインデックスとして簡単にする必要があります。
ユーザーとシステムが次の方法で接触します。書かれたユーザー
- 問い合わせの定式化が受信されます
- ヒットリストは可能です
- ドキュメントユニットを表示および処理します
- 地元。
シンボル [ 編集 | ソーステキストを編集します ]
ASCIIコード(情報交換のためのアメリカ標準コード)は1963年に作成されました。彼の7ビットコードは、128文字を記録およびマッピングすることができました。後に8ビット(= 256文字)に拡張されました。最大の文字セットUnicodeは、以前は4バイト、つまり32ビットで構成されており、世界で使用されているすべての標識をマッピングすることになっています。
ISO 8859(国際標準化機関)は、ドイツ語の「ß」などの言語固有のバリアントも規制しています。
データベース内の新しいドキュメントの受け入れ [ 編集 | ソーステキストを編集します ]
新しいドキュメントは、知的および自動的にデータベースに追加できます。新しい文書の知的入場では、インデクサーが責任を負い、どのドキュメントが記録されるかを決定します。自動プロセスは、「ロボット」または「クローラー」によって実行されます。基礎は、よく知られている量のWebドキュメントであり、そのような「シードリスト」です。このリストを含むすべてのWebサイトのリンクは、クローラーのタスクになりました。それぞれのページのURLは、データベースで既に利用可能かどうかを確認します。さらに、ミラーと複製は認識され、削除されます。
昇降補助具 [ 編集 | ソーステキストを編集します ]
ベストファーストクローラー [ 編集 | ソーステキストを編集します ]
最も優れたクロールの1つは、ページランククローラーです。リンクは、着信ページの数と人気によって並べ替えます。他の2つは、魚の探索とサメの探索クローラーです。前者は、関連ページが集中するウェブ上のエリアに彼の作品を制限しています。 Shark-Search-Crawlerは、関連する判断を下すために、アンカーテキストから追加情報を描画することにより、この方法を洗練します。
各ページオペレーターには、クローラーに対してページを閉じる機会があります。
Im Deep Webをrawう [ 編集 | ソーステキストを編集します ]
クローラーが深いウェブでもうまく機能できるように、彼はさまざまな要件を満たす必要があります。一方では、適切な検索クエリを策定できるように、データベースの検索マスクを「理解」する必要があります。さらに、彼はヒットリストを理解し、ドキュメントを表示できる必要があります。ただし、これは無料のデータベースでのみ機能します。 Deep Web Crawlerにとって、データベースからのすべてのドキュメントが表示されるように検索を策定できることが重要です。検索マスクに1年がある場合、クローラーはすべてのドキュメントに到達するためにすべての年齢を問い合わせなければなりません。キーワードフィールドの場合、適応戦略が理にかなっています。
データが記録されると、クローラーは見つかったページの更新を記録するだけで済みます。 DEを可能な限り局所に保つためのいくつかのオプションがあります。ページは同じ距離で定期的に訪問されるため、リソースを超えて不可能であるか、偶然に訪問することは、かなり最適ではありません。 3番目のオプションは、優先順位の訪問です。たとえば、変更のビート(サイド中心)または通話またはダウンロードの頻度(ユーザー中心)の後。
クローラーのさらなるタスクは、スパム、重複、ミラーを認識することです。重複の検出は、通常、パスを比較することによって行われます。スパムを避けることは、しばしば隠されているため、少し難しいです。
FIFO(最初は最初) – クローラー [ 編集 | ソーステキストを編集します ]
FIFOクローラーには、片側のすべての左にたどり、それらを処理し、見つかったページの左側と深さの最初のクローラーに続く幅の最初のクローラーが含まれています。最初のステップでは、これは幅広いクローラーのように機能しますが、2番目のステップでは、選択により左側の選択が行われ、それは続きません。
テーマのクローラー [ 編集 | ソーステキストを編集します ]
テーマのクローラーは規律に特化しているため、専門家に適しています。関連するページが識別され、「トンネル化」されていません。それにもかかわらず、これらのトンネルされたページのリンクは、他の関連するページを見つけるために引き続き継続されます。 蒸留器 一方、分類法とサンプル文書を使用して、クローラーの安価な出発点を見つけます。 分類器 これらのページは、関連性のために直立します。分類法とサンプルドキュメントを定期的に更新する必要があるため、プロセス全体が半自動的に実行されます。さらに、概念的な順序が必要です。
保存とインデックス [ 編集 | ソーステキストを編集します ]
見つかったドキュメントはデータベースにコピーされます。この目的のために、2つのファイルが作成され、一方でドキュメントファイルが、一方で倒立ファイルが作成されます。逆ファイルでは、すべての単語またはフレーズがAlphabetまたは別のソート基準に従って配置およびリストされています。単語インデックスを使用するかフレーズインデックスを使用するかは、フィールドに依存します。たとえば、フレーズインデックスは単語インデックスよりもはるかに優れています。逆ファイルには、ドキュメントおよび構造情報の単語またはフレーズの位置に関する情報が含まれています。構造情報は、関連性に役立ちます。たとえば、単語が大きく書かれていると言われている場合、重みを重ねることもできます。単語とフレーズは、正しい順序で書かれ、後方に保存されます。これにより、オープンリンク構造が可能になります。反転ファイルは、データベースインデックスに保存されます。
次の図は、IRモデルの2次元分類を示しています。マトリックスの分類に応じて、さまざまなモデルで次の特性を観察できます。

- 寸法: 数学的基礎
- 代数モデル ドキュメントと問い合わせは、ベクトル、マトリックス、またはTupeとしての文書を表します。これらは、有限数の代数算術演算を介して類似性のペアを計算するために1次元の類似性測定に転送されます。
- Mengent理論モデル それは、彼らが数量で自然に言語文書を再現し、文書の類似性の決定を(主に)数量操作の使用に起因するという事実によって特徴付けられます。
- 確率モデル ドキュメント検索のプロセスまたはマルチステージランダム実験としてのドキュメントの類似性の決定を参照してください。したがって、ドキュメントの類似点を説明するために、確率と確率論(特にベイズ)に使用されます。
- 寸法: モデルのプロパティ
- 固有の予定のモデル それは、彼らが用語間の既存の相互依存関係を考慮し、したがって、日付のないモデルとは対照的に、暗黙的な仮定は、用語が直交または独立しているという事実に基づいていないという事実によって特徴付けられます。日付の固有の日付を持つモデルは、2つの用語間の相互依存の範囲がドキュメントインベントリから派生し、モデルによって決定される方法、つまりモデルが固有(固有)から派生しているという事実のモデルから限られています。このクラスでは、2つの用語間の相互依存性は、2つの用語の調理戦から直接的または間接的に導き出されます。クックバトルは、ドキュメント内の2つの用語の一般的な外観を意味すると理解されています。したがって、このモデルクラスは、ドキュメントで頻繁に一緒に発生する場合、2つの用語が相互依存するという仮定に基づいています。
- 日付のないモデル それは、2つの異なる用語がそれぞれ完全に異なるものとして区別され、互いに接続されないという事実によって特徴付けられます。この事実は、文献では、用語の直交性または用語の独立性と呼ばれることがよくあります。
- 固有の予定を持つモデルと同様に、 超越的な予定のモデル 条件の直交または独立についての仮定はありません。固有の予定を持つモデルとは対照的に、超越的な予定を持つモデルの用語間の相互依存性は、ドキュメントインベントリとモデルからのみ導き出すことはできません。これは、モデルに基づいているロジックが基礎として(超越的)であることを意味します。これは、超越的な任命を伴うモデルでは、期限の存在が明示的にモデル化されているが、2つの用語間の予約の具体的な表現を直接または間接的に外部から指定する必要があることを意味します。
情報検索には、他のさまざまな領域と相互参照があります。 B.コンピューター言語学の確率理論。
- ジェラルド・サルトン;マイケル・J・マクギル、現代の情報検索の紹介。 McGraw-Hill、1983年。
- ジェームズ・D・アンダーソン、J。ペレス・カーバロ: 情報検索設計:情報検索データベース、デジタルライブラリ、インデックスにおける情報の説明、組織、表示、アクセスの原則とオプション ( 記念 2008年12月31日から インターネットアーカイブ )大学出版ソリューション、2005年。
- マイケルC.アンダーソン: 検索。 In:A。D. Baddeley、M。W. Eysenck、M。C. Anderson。 メモリー。 Psychology Press、Hove、New York 2009、ISBN 978-1-84872-001-5、S。163–189。
- R. Baeza-Yates、B。Ribeiro-neto: 現代の情報検索。 ACM Press、Addison-Wesley、ニューヨーク1999年。
- レジナルド・ファーバー: 情報検索 。 Point.val.in、2003、ISBN 3-89864-213-5。
- ドミニク・クロプカ: 自然言語文書の表現のモデル。オントロジーベースの情報フィルタリングとリレーショナルデータベースによる検索 。 ISBN 3-8325-0514-8。
- クリストファー・D・マニング、プラバカル・ラガヴァン、ヒンリッヒ・シュッツェ: 情報検索の紹介 。ケンブリッジ:ケンブリッジ大学出版局、2008年、ISBN 978-0-521-86571-5。
- Dirk Lewandowski: 検索エンジンを理解します。 Springer、Heidelberg 2015、ISBN 978-3-662-44013-1。
- Dirk Lewandowski: Web情報検索 。 の: 情報:科学と実践(NFD)。 56(2005)1、S。5–12、 ISSN 1434-4653
- Dirk Lewandowski: Web情報検索、インターネット上で情報検索のためのテクノロジー 。 (=情報科学。7)。 DGI聖書。 Frankfurt Am Main 2005、ISBN 3-925474-55-2。
- Electonore Poetschlots: 情報検索 – 基本と方法の紹介。 E. Poetsch Publishension、Berlin 2006、ISBN 3-938945-01 X.
- ジェラルド・サルトン、マイケル・J・マギル: 最新の情報検索の紹介。 McGraw-Hill、ニューヨーク1983。
- Wolfgang G.ストック: 情報検索。情報を見つけて見つけます。 オルデンブール、ミュンヘン/ウィーン2007、ISBN 978-3-486-58172-0。
- アレクサンダー・マルテンス: 情報検索の視覚化 – セマンティックWebに代わるものとしてWikisで適用される理論と実践。 bod、norderstedt、ISBN 978-3-8391-2064-4。
- Matthias Nagelschmidt、Klaus Lepsky、WinfriedGödert: 情報の閉鎖と自動インデックス:教育とワークブック。 Springer、Berlin、Heidelberg 2012、ISBN 978-3-642-23512-2。
- 情報検索の情報グループ コンピューターサイエンス協会の
- Norbert Fuhr:2006年のDuisburg-Essen大学での講義「情報検索」、 材料
- Karin Hasten: セミナー「情報検索」 ハイデルベルク大学、2015年
- ハインツ・ディーク・ラックハート: 情報検索 、ザールランド大学、 仮想マニュアル情報業界で ( 記念 2001年11月30日から インターネットアーカイブ ))
- アップグレード、情報学の専門家のための欧州ジャーナル、 情報検索とWeb バンドIII、nr。 3、2002年6月。
- C. J. van Rijsbergen: 情報検索、1979年
- 情報検索施設(IRF)
- ↑ 情報検索1、基本、モデル、およびアプリケーション 、Andreas Henrich、バージョン:1.2(Rev:5727、2008年1月7日現在)、Otto-Friedrich University Bamberg、Media Informaticsの議長、2001-2008
Recent Comments