インドの作家 – ウィキペディア


下 インドの作家 Brahmiスクリプトの子孫を理解してください。たとえインド以外でも、それらの一部がネイティブであっても、彼らはしばしば「インドの著作」と呼ばれます。
その後、その後その後続く南東アジアと東南アジアが世界地域であり、今日では最も異なるフォントが使用されています。これは、何よりもバングラデシュ、ブータン、インド、モルディブ、ネパール、パキスタン、スリランカの国々とのインド亜大陸に適用されます。
インドや他の南アジア諸国では、とりわけ、以下のインドの著作が関連しています:ベンガルシェ聖書、デヴァナガリ、グジャラティスクリプト、グルムキスクリプト、カンナダスクリプト、マラヤラムスクリプト、オリヤスクリプト、シンハラ人スクリプト、タミルスクリプト、テルグ語のスクリプト。たとえば、インドの亜大陸の外では、バリの脚本、バーマニッシュ(ミャンマー)聖書、クメールスクリプト、ラオスの台本、タイの脚本、チベットの脚本が使用されています。
インドの作家の流通エリアでは、次のグループからのフォントが発生します。
Brahmi AbbotsとOl ChikiとThaana Autochthonがそうである間、アラブとラテンのスクリプトがインポートされています。
Brahmiスクリプトの子孫は、プロトセミックから派生したアルファベットの主要な記事の系図によると(表示についてはそこにある情報を参照):
ブラフミ – 紀元前250年。 (場合、スリランカ)
インドの著作のさまざまな形式は、同じ文(ここではサンスクリット文の文章)を異なる著作で再現すると、特に明確になります。

インドの気候は、古い著作やテキストの保存を助長しません。このようにして、典型的な執筆素材、手のひらの葉、木の樹皮は、倒れる数年前にしか残っていません。したがって、主にコイン、岩、建物のフォントに引き渡されます。最古の原稿は、11世紀の広告のみを使用しています。伝統的に、インドの書かれた伝統は口頭と見なされています もっと確信が持てます 。
使用される執筆資料は、文字の形状に部分的に影響を与えました。
インドの著作は正しいものであり、大規模で小さな執筆を知りません。
すべてのインドの著作(他のいくつか、たとえばエチオピアのスクリプトなど)は、音節の著作とアルファブスクリプトの間にあるフォントタイプに属します。
- 母音は音節でのみ完全に書かれています。子音によると、ボーカリアの批評家だけがいます。ただし、それらの使用は不可欠です(アラビア語やヘブライ語などの子音とは対照的です)。
- 「ショートA」は子音に従って書かれていません(「固有の母音」とも呼ばれるゼログラフ)。
- 代わりに、子音の母音は、追加のジアクリティクス(「virama」または「halant」)によって表示されます。 Halantは、いくつかの新しい界面的な言語(ヒンディー語やベンガルなど)で一貫して使用されていません。ハラントはパンジャブ語ではまったく現れないため、「a」が子音の後に言われるかどうかはわかりません。
- ボーカリシス子音のセロンは、通常、結晶字にまとめられます。
これらの著作の名前は均一ではありません。多くの場合、音節の指定は単に選択されます。これには、この特別なタイプが含まれるだけではありません。最近のインプリントは、Abugidaと「Alphasyllabar」です。
最古のサンスクリット語のテキストは、最初は口頭で渡されました。紀元前400〜300年頃の期間のみ。 BC、Kharoshti、およびBrahmiは、話し言葉を提示するために開発されました。これらは中央の界面活性(MIA)の表現に適していましたが、古典的なサンスクリット語の音声表現には十分ではなく、この点で後に修正されました。サンスクリット語は、ブラフミの脚本のすべての子孫で提示され、提示されますが、デヴァナガリはサンスクリット語の表現のための書面による形として勝ちました。 19世紀の言語研究者は、デヴァナガリでサンスクリット語を示しています。 Friedrich MaxMüllerが発行 版 リグヴェーダはデヴァナガリにありました。デヴァナガリは、類型書記官が最初に文を作成しなければならなかった当時の行為でした。

それ以来、哲学者はサンスクリット語をラテン文字で見せる必要性を見てきました。 1816年、フランツ・ボップは、母音の長さが逆曲(â、î、行き来)を通る最初の音訳スキームを開発しました。 ブレスラフ (例:bʽbʽ)。シビランテンシャとśは通り抜けました ブレスラフ と 優しい (sʽ、s」。彼の辞書ṡで使用されているモニエ・ウィリアムは、śとṣのためにsh。 1877年に公開された彼のエディションで、テオドールユーザーはラテン系サンスクリット語でリグヴェーダを公開しました。アーサー・アンソニー・マクドネルも、デヴァナガリなしでヴェディッシュ(1917年)の文法で出てきました。現在の専門出版物は、IASTおよびNLACの音訳を使用しています。
Diakritikaを使用したスキーマ [ 編集 | ソーステキストを編集します ]
iast [ 編集 | ソーステキストを編集します ]
サンスクリット語の音訳(IAST)の国際アルファベットは、ラテン文字のサンスクリット語を表現するための最も一般的な学術基準を表しています。
NLAC [ 編集 | ソーステキストを編集します ]
カルカッタ(NLAC)の国立図書館は、サンスクリット語だけでなく、すべてのインドの著作に適用されるIASTに基づいた音訳基準を開発しました。
ISO 15919 [ 編集 | ソーステキストを編集します ]
ISO 15919は、南アジアのすべての言語の音訳標準を表しています。IASTとNLACは、ISO 159191/2001のサブセットです。 ISO 15919は、Unicodeのラテン表現を定義しています。
ISO 15919翻訳者はプラットフォームに依存しているため、すべてのオペレーティングシステムで同じように識別できます。 ISO 15919 DiakritikaはBrahmiの著作のグラフェメムを提示するために使用します
Ascii Schemata Ohne Diakritika [ 編集 | ソーステキストを編集します ]
ASCIIの音訳は、多くの場合、インターネットで見られます。すべてのASCIIスキームは、公式の翻訳条約ではありません。
ハーバード・キート [ 編集 | ソーステキストを編集します ]
ハーバード京都スキームは、ASCIIがDevanagariなどのインドの著作を表現するために使用する音訳システムです。 Diakritikaを使用せず、学術環境では使用されていません。アプリケーションの最も一般的な領域:電子メールとインターネット。
itrans [ 編集 | ソーステキストを編集します ]
「インド語の音訳」(itrans)は、インドの著作(devanāgarīなど)のASCIIスキームでもあります。 Avinash Chopdeによって開発されました。それはハーバード・キョトよりも広範であり、それはほぼ同じです。 Unicodeや他のASCIIスキームの拡散により、それは時代遅れですが、それでもインターネット上で広まっています。表は、サンスクリット語の音訳の国際アルファベットを参照してください。
比較表 [ 編集 | ソーステキストを編集します ]
キャラクターのアルファベット順の配置は厳密に音声であり、すべての言語で本質的に同じです。この体系的なプレゼンテーションは、2300年以上前に彼らの言語の音声学と音韻論を明確に認識し、体系的にそれらを体系的に説明した「旧インド人」の優れた言語スキルを証明しています。
インドの著作のアルファベット順の配置は、最初はラテン語の音訳のサンスクリット語で使用された兆候について説明されています(ISO 15919による)。発音に関する情報は、言語ごとに異なるため、分配されます。
キャラクターは音節(「母音」)と子音に分かれています。
- モディルキャリア(「母音」)
- サブグループとの子音:
音節は通常「母音」と呼ばれますが、銀の子音[R]と[L]も含まれています。
音節 [ 編集 | ソーステキストを編集します ]
| モノフソンジ | タップがあります |
| シルビアン子音 | ̥̥̥̥̄̄̄̄)) |
| 「diphthonge」 | e o au |
モニュションと銀の子音の場合、短い音と長い音を区別します。ただし、長いシルビアン「L」は、対称性のための古代インドの文法によって仮定された構造のみを表しています。彼の唯一の出来事は彼の名前です!
‹e› and ‹o›は常にサンスクリット語で長いです。それらはモニュトンですが、それらは「diphthonge」と呼ばれ、分類されます。これは、サンスクリット語の形態恐怖症の理由で理にかなっています。
アルファベットに従ってください サイン 母音用のdiakritikaとして使用されます。したがって、それらは母音にもリストされています。
| ṁ(anuswar) | M̐(アヌナシカ) | ḥ(Visarga) |
AnusvaraとAnunasikaは、鼻腔を指し、Visargaは声のない[h]のような母音のようなものです。
子音 [ 編集 | ソーステキストを編集します ]
クラッディング 5行と5列のあるテーブルに配置されています。線は、Velar -Palatal -Retroflex -Dental -Labial(つまり、話すときの空気の流れの方向)の順に関節部位に対応します。柱は、明確な型の声のない/声、装い/吸引、鼻腔の特性に対応しています。
| 声 吸引 鼻 |
– – – |
– + – |
+ – – |
+ + – |
+ – + |
|---|---|---|---|---|---|
| Velare | k | お客様 | g | gh | 作り |
| 口蓋 | c | ch | j | JH | ñ |
| Retroflexe | 最高の | 最高の | ḍ | ḍH | ニー |
| 歯科 | t | th | d | DH | n |
| リップ | p | ph | b | bh | m |
のシリーズ ソノラント 、「半球」とも呼ばれます。
今日の観点から見ると、€y›および‹v ‘半母音(より正確に:近似)のみです。また、それらを母音[i]および[u]の非ミルクの発生と見なすこともできます。音節と[l]を母音と呼ぶ場合、非感性の発生を「半球」と表現することは論理的です。しかし、現代の音声学では、[r]と[l]は、絹のようなものであるか非lungeであるかにかかわらず、常に子音の1つです。
最後の行にはそれが含まれています シビラント (口蓋の順序で – レトロフレックス – 歯科)と声門H:
閉鎖音の明確なポイントは、次のように古代インドの文法によって言及されていました。
- Velare:KantyaKaṇṭhya(
- パラタール:तततलव対tālavya(<ततear gaumen)
- retroflexe:मूमू左では、mūrdhanya(<मूमू原の最高点であるmūrdhanサミット、また:額の頭蓋骨、頭、レース)
- デンテール:ダンティアダンティア(<ダントダンタザーン)
- Labiale:失われたoṣṭhya(
今日でも、Velareまたは「Cockat。:Cacumen ‘Summit、High -dot’)および「Cerebrum ‘Brain」)の時代遅れの不正確な名前「Guttural」(guttural’ for cockat。:cacumen ‘summit、highbrum’ brain ‘)。
アルファベット [ 編集 | ソーステキストを編集します ]
インドのアルファベットの例として、サンスクリット語に使用された兆候と、国際的な音声アルファベット(IPA)(子音の固有の母音から除外された)によると、その可能性の高い発音を持つデヴァナガリスクリプトは:) :)::

vedicには、 /ɖ /ɖ /ɖ /ɖの異常形態としてvedicにळがあります。これは、新しいインド言語(マラーティーなど)でも使用されます。
Vokal-Diakritika [ 編集 | ソーステキストを編集します ]
母音の使用の使用は、子音の例を使用してここに示されています ‘k›:

特別ケース /r / [ 編集 | ソーステキストを編集します ]
「母音」および「半球」としてのRの特別な位置は、インドの著作で表現されています。 Devanagariについてはここで説明されています。
銀 / r/は母音のようにグラフィカルに扱われます。これは、音節でのみ完全に書かれていることを意味します。子音によると、関連する時代症のみです。

非シルビッシュ / r/は、単語の冒頭でのみ書かれ、「フルフォーム」で間隔的に書かれています。
![]()
子音クラスターで Diakritikaが使用されている場合、グループの最初のコンポーネントが音節端に移動し、母音の上にダニとして配置されるため、R。‹r›の位置に応じて子音グループに異なる形があります。このフォームはrephと呼ばれます。
![]()
‹r› r›グループの最後のコンポーネントは、以前の子音の下で小さなスラッシュまたは角度として設定されています。
![]()
一部のインドの著作では、そのような位置バリアントは他の「半球」にも適用されます。 Devanagariの例(v =母音; c =子音; v r = Vokal Mit reph; c r =下のr-diakritikumとの子音):

結紮 [ 編集 | ソーステキストを編集します ]
2つ以上の子音のグループは、最後の子音のみが母音(または二重母音)が続くだけで、結晶に統合されます。それらのコンポーネントは通常、まだ明らかに認識可能です。特別な場合には、完全に新しいキャラクターも形成できます。
次の例は、わずかな選択のみを表しています。Devanagariフォントには数百字字が発生します。
シンプルなデヴァナガリリーグ

複雑なデヴァナガリリーグ

シンボル [ 編集 | ソーステキストを編集します ]
文字列「子音(エンクラス) +母音±ボーカルの追加標識」は、インドの著作に執筆音節(Akshara)に要約されています。これはシンボルと同一である必要はありません。形態素の制限は、グラフィック子音クラスターの真ん中にあることもあります。 (以下も参照してください 固有の母音 ))
直線性 [ 編集 | ソーステキストを編集します ]
全体として、インドの著作グループの著作は直線的です。ただし、非線形性は、ライティング音節内で非常に頻繁に決定できます。
「学生」のヒンディー語の単語は例として与えられています:最初の音節では、下痢は短いものを表します。 前 関連する子音V›。 2番目の音節には、ligature ‘dy’、そのコンポーネントが含まれています 互いの上に 台。最後の音節の冒頭で話されたrは表示されるだけです 音節の端で 「reph」としての母音の上。
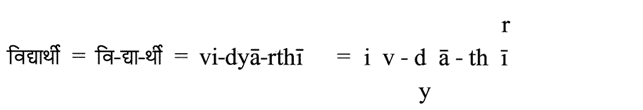
インドの著作のこれらの特別な特徴は、言語研究や教訓的な目的のために、ラテン語などの一貫した線形フォントへの翻訳を行います。
現代のインド語のほとんどは、上記のサンスクリット語で説明されている音よりも多く含まれているため、アルファベットは少数のキャラクターによって拡張されなければなりませんでした。タミル語の場合、声を上げたものとしての弾薬のみを声を上げたため、タミル語には願望がないため、キャラクターの数は大幅に減少しました。
追加の文字 [ 編集 | ソーステキストを編集します ]
北インドの著作では、Diakritikaはしばしば、下位ポイント(「Nukta」)やラインなどのキャラクター文を拡大するのに役立ちます。一部の文字も形成されています。
Devanagari、Tamil、Kannada、Singhalese、Tibetanの例は次のとおりです。
デヴァナガリ [ 編集 | ソーステキストを編集します ]

Rajasthaniでは、「母音キャリア」としてbocalia批評家を組み合わせることで、‹e›および‹ai›の完全な形式が書かれています。

また、このスペルは、執筆の学習を促進するためにしばらくヒンディー語のために伝播され、したがって、ヒンディー語の国語としての普及を促進しました。
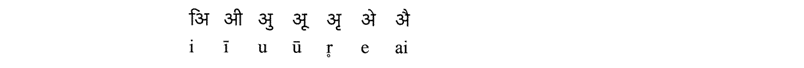
ドラビダル言語 [ 編集 | ソーステキストを編集します ]
長いeとoとoを区別する必要があります。これはもともと、南インドの著作でグラフィカルに言及されていませんでした。叔母と‹€の追加標識は、イタリアの宣教師コンスタンス(1680–1774)によって導入されました。
彼らのラテン語の翻訳に関しては、ドラヴィディックの著作では、長い母音、‹o› o›は常に短い母音を表している一方で、対応するデヴァナガリの兆候は‹ĕ›および‹ŏ››››› eを常に説明していることに注意する必要があります。

南インドのアルファベットには、特定のドラビディック音を再現するための追加の文字が含まれています(Retroflex近似、肺胞RおよびN)。ダイアクリティックスは、タミル語の[f]および[z]にも使用されます。

カンナダ 母音の長さのための独自の時代症があります。これは、ライティング音節の最後の兆候として表示されます。
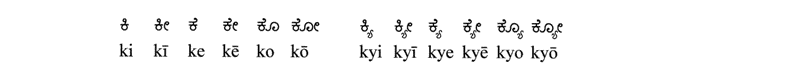
シンハレーゼ [ 編集 | ソーステキストを編集します ]
他の母音の標識、prenceled子音と[f]が作成されました。

プレンセル化された子音の兆候は、Diakarkumとして追加のアーチを追加することにより、関連する非抑制剤から出現しました。
チベット [ 編集 | ソーステキストを編集します ]
また、インドの台本からチベット人のスクリプトの開発において、チベットの音の兆候はありませんでした。歯の感情の兆候は、ジアクリティックを追加することにより、口蓋から形成されました。他のキャラクターは、既存の文字を反映して作成または受信されています。

その後、サンスクリット語のテキスト、特にレトロロフレクスの表現と吸引された声の積立性のために、サンスクリット語のテキストが音訳するためにさらなるキャラクターが紹介されました。
ビルマニッシュ、クメール、タイ [ 編集 | ソーステキストを編集します ]
これらの著作は、トンマークと多数のボーカルサインを含むように拡張されました。
インドの著作におけるVokaldiakritika [ 編集 | ソーステキストを編集します ]
Brahmiスクリプトでは、ボーカリアの批評家は子音に付着した小さなストロークとして示されました。フォントのさらなる開発により、Diakritikaはその形状、サイズ、および位置を変更しました。時々彼らも分裂しました。次の表は、選択を示しています。

シルビアの子音とrの特別な形態 [ 編集 | ソーステキストを編集します ]
新しいインドーリック言語には、これ以上のシルビアの子音はありません。シルビアンRの歴史的な綴りは保存されていますが、発音は一部の言語では、他の言語では[RI]が変化するように変化しました。
Gurmukhiスクリプトはここで最も一貫しています。銀Rの兆候もrephの兆候もありません。
ドラビダル言語(より正確には:これらの言語のドラビディックワード素材)には、銀の子音はありません。したがって、タミル語のスクリプトには銀rの兆候はありません。タミル語には、Rの他の出来事の特殊文字もありません。
カンナダ語、マラヤーラム語、テルグ語には、サンスクリット語のすべての銀の子音の兆候があります。カンナダにもrephがあります。しかし、これはマラヤラムとテルグの改革された綴りにはもはや使用されていません。
結紮 [ 編集 | ソーステキストを編集します ]
Devanagariの上記の原則は、本質的にすべての北インドの著作に適用されます。つまり、多くの場合、結紮の最後の子音が元の形を保持しています。南インド(ドラヴィッド)言語のカンナダ語とテルグ語の著作では、最初の子音が完全に書かれており、次の子音はその下または後ろの縮小されたやや修正された形で追加されます。関連する母音は、完全に書かれた子音と合併します。
例カンナダ:

Gurmukhi(Panjabi)、現代のSinghaleseとTamilの使用は、ほとんど結紮糸ではありません。
チベット、ビルマニック、クメール、および寛容な子音グループでは、互いに類似しているため、コンソン群はそれらを許可することによって提示されます。
現代のタイには結紮はありません。
オルトグラフィ [ 編集 | ソーステキストを編集します ]
インドリアン語 [ 編集 | ソーステキストを編集します ]
Devanagariスクリプトは、サンスクリット語の音素を非常によく再現しています。新しいインドーリック言語の音韻システムは、新しい発音の言葉の綴りが大幅に適応されることなく、異なって発展してきました。これにより、歴史的な正書法が生まれました。
最も印象的なのは、東部の新しいindoaricallicages Assamesian、Bengali、Oriyaの変化です。ここには重要な変更があります:
- 固有の母音は、ここで[ɔ]または[ɒ]として話されています。
- シビランテンシーは、ベンガル語、オリヤでアサメシシュで崩壊しました。
- パラタレスはアサメシア語でもあまりにもなり、レトロロフレクスは歯科と崩壊しました。
- 一部の子音クラスターのコンポーネントは、音声的に調整されています。
OriyaとSinhaleseを除く新しいindoaricallagesでは、固有の母音は、これがHalantまたはligature層の執筆で提示されないことなしに話されることはありません。 Alexisの例
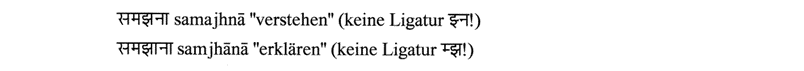
静かな固有の母音は、詩を暗唱して歌うときに明らかになります。 (アナログは、フランス語の「サイレントE」で観察できます。)
HalantはGurmukhiスクリプト(Panjabi)にはまったく表示されないため、固有の母音が子音の後に話されるかどうかはわかりません。
パンジャビのもう一つの特異性は、吸引された声を上げた弾力性の吸引と渦が失われたことです。これらの文字を含む単語の単語のアクセントを含む単語の音節は、高いトーンまたは低いトーンを受け取ります。吸引された声の弾丸はまだ書かれているので、単語に音があるかどうかがわかります。
ドラビダル言語 [ 編集 | ソーステキストを編集します ]
タミル語のフォントを使用すると、言語には吸引音がなく、花は異オリオンにのみ発生するため、文字の数は大幅に減少しました。タミル語のアルファベットとデヴァナガリのアルファベットを比較してください。


最後から2番目のシリーズの音(除く)は、ドラビダル言語でのみ発生します。最後の行のものは、場合によってはサンスクリット語の単語を正しく書くことができるように、グランサスクリプトから借用されます。しかし、ほとんどの場合、これらはタミルスクリプトではほとんど認識されていません。ただし、これは現代のタミル語の発音に対応しています。
サンスクリット語を声高にタミル語フォントに翻訳したい場合は、2つの方法を使用できます。

サンスクリット語とドラビダル言語の混合は「マニプラバラ」と呼ばれます。ドイツ語と英語の「Denglisch」ミキシングに匹敵します。英語の単語がDenglischで考慮される可能性があるため(例:Download EN)、Sanskwortはマニプラバラでタミル人のデートを受け取ることができます。古いタミル語のテキストや、サンスクリット語に特に強く向いた個々の現代の作家では、タミル語のタミル語プログラムで書かれているグランサスクリプトのサンスクリット語のコンポーネント(「ダウンロード」、「ダウンロード」の英語のオログラフィーでさえ)で書かれていることを観察できます。

残りのドラビディックの著作には、サンスクリット語の言葉を書くために必要なすべての兆候が含まれています。しかし、一方ではマラヤーラム語の正書法と、他方ではカンナダ/テルグ語に違いがあります。
マラヤーラム語では、スペルはタミル語と同様にドラヴィディックの言葉に使用され、サンスクリット語の正書法はサンスクリット語に当てはまります。
カンナダとテルグ語では、すべての言葉は、その起源に関係なく、音声で書かれています。
チベット [ 編集 | ソーステキストを編集します ]
チベットの正書法は非常に歴史的です。 1000年以上前の言語スタンドを反映しています。現代の言語に関連して、大量の「余分な」文字が並んでいます。これは、言語から姿を消してから長い間姿を消してきました。次の4つの単語はすべて[発音]です!それは動詞の主要な形式です。

辞書のチベット語の単語を再開しているのは、仲間の共犯を探しています。上記の4つの単語は「G」の下でフォローアップされます。これにより、「G」に関連する子音について追加のルールを遵守する必要があります。
クメール [ 編集 | ソーステキストを編集します ]
Khmerには非常に多くの音声音素があります(Diphthongeを含む30以上)。これのために追加の文字が作成されました。数字をできるだけ低く保つために、インドのアルファベットの像は2つのシリーズに分けられました。シリーズ1には、声のない子音のためのインドのアルファベットに立っていた兆候、声のシリーズ2が含まれています。これは、Khmerのシリーズ1のすべての子音が今日無視されていることを意味するものではなく、シリーズ2のすべてが今日発言されています。むしろ、同じ母音の記号は、シリーズ1または2の子音に接続されているかどうかに応じて、異なる母音を示します。これにより、必要な母音標識が半分になりました。 Khmerスクリプトには2つのDiakritikaも含まれており、シリーズ1の子音に立つVocaliaの批判は、シリーズ2に属する発音を受け取り、その逆も同様です。
さまざまなインドの著作の兆候がここにリストされています。碑文は、カルカッタの国立図書館の碑文として提示され、国際的な音声アルファベット(IPA)による発音です。一部の文字が表示されないため、このリストは不完全です。
注:表示されている言語の一部では、aspirataの発音は非照射音と同一です。
子音 [ 編集 | ソーステキストを編集します ]
| NLAC | 暴力 | デヴァナガリ | ベンガル語 | グルムキ | グジャラート語 | オリヤ | タミル語 | テルグ語 | カンナダ | マラヤーラム語 | シンハラ | チベット |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| k | k | k | a、a | どうやって | c | a | KA | 来て | s | カウンター | の | ཀ |
| お客様 | kʰ | b | b | なれ | バルク | b | – | kha | クォータ | cr | Khath | ཁ |
| g | � | g | csc。c | s | c | c | – | G. | ga | 消えた | グループ | ག |
| gh | �ʱ | d | c | 手に入れた | あえて | 家にいる | – | G. | ジュニア | ジョージ | d | – |
| 作り | nɔ | 4 | e | ਙ | 1 | 詳細については | どこ | ః | 借りている | はい | 食べ物 | ང |
| c | c | fと | f | の | コード | スクイー | c | ch | 含み笑い | 韻 | char | ཅ |
| ch | cʰ | は | g | 青 | 六 | 小さい | – | ch | 含み笑い | unr | バー | ཆ |
| j | ɟ | h | h | また | 同じ | j | 加入 | Ans | ジャオ | j | j | ཇ |
| JH | ɟʱ | jhoom | ぴくぴく動く | フット | z | ジャンプ | – | ఝ | ಝ | ഝഝ | ඣ | – |
| ñ | びっくりして | j | j | ਞ | 3 | クリング | wisp | కకకకకకక | p | n | または | ཉ |
| 最高の | ʈ | t | つま先 | に | 錫 | 牽引 | t | t | ta | t | に | ཊ |
| 最高の | ʈʰ | 雷 | 絶頂 | タキー | 舌 | 浮気 | – | తతతతతత | ti | ഠഠ | 40 | ཋ |
| ḍ | ɖ | d | d | d | d | 博士 | – | D. | da | ダット | d | ཌ |
| ḍH | ɖʱ | 二 | b | 描く | ペイント | 遠い | – | న | IDE | ദേഖ | ඪ | – |
| ニー | ɳ | n | o | に | n | レーニング | ve | నననననన | p | ക്ഷ | dise | ཎ |
| t | t | 生きている | t。 | から | ピュア | トリン | – | T. | 細い | t | 終えた | ཏ |
| th | t̺ʰ | 徹底的です | t | 30 | 泥棒 | th | tha | tha | 公平 | 情報 | ཐ | |
| d | D̺ | s | de- | 期限 | – | 男 | s | それも | ད | |||
| DH | D̺ʰ | din | ほこり | 分ける | 挨拶 | – | DHA | ダッシュ | ドレス | 白 | – | |
| n | n | いいえ | いいえ | いいえ | いいえ | しないでください | Na | の上 | の | n | もの | ན |
| ṉ | n | 私 | – | – | – | – | ノミネート | – | – | – | – | – |
| p | p | 音楽スケールの5番目のメモ | p | 置く | 午後 | s | b | p | PA | p | EMS | པ |
| ph | pʰ | f | F. F. | f | シナモン | 四 | – | f | fi | クソ | ඵ | ཕ |
| b | b | b | B b | b | バルク | 壊す | – | B. | ダンディ | b | b | བ |
| bh | bʱ | b | v | の上 | バルク | v | – | b | バクティ | バット | 明るい | – |
| m | m | 私 | s | 私 | 私 | マンド | m | m | うなずき | いいえ | と | མ |
| と | j | y | y A | Y. | ちょうど | ユダヤ人 | y | Y. | 昨日 | y | は | ཡ |
| r | r | と | r/ৰ | 右 | の | の | r | R. | の | fla | r | ར |
| ṟ | r | r | – | – | – | – | ごみ | ఱ | の中 | 走る | – | – |
| l | l | l | 好き | 取った | l | la | l | l | la | le | l | ལ |
| ḷ | 暗い | 刺します | – | 取った | ou | f | なめる | … | a | パー | の中に | – |
| ḻ | ɻ | 4 | – | – | – | – | ழ | – | ೞ | 千 | – | – |
| の | ʋ | と | うわーすごい | ベンド | – | d | th | VA | ca | の | ཝ | |
| ś | ɕ | 市 | s | sh | 小屋 | シャブ | ஶஶ | 来て | 叫ぶ | 言う | カード | ཤ |
| わたしは | ʂ | 縮む | s | – | トラウマ | コウモリ | ショット | sh | シャット | 短い | シャット | ཥ |
| s | s | s | s | si | c | 深刻 | s | A. | di | com | 測量 | ས |
| h | h | おい | h | はい | v | 人間 | h | ハ | ハ | ハ | ハ | ཧ |
ボーカル [ 編集 | ソーステキストを編集します ]
| NLAC | 暴力 | デヴァナガリ | ベンガル語 | グルムキ | グジャラート語 | オリヤ | タミル語 | テルグ語 | カンナダ | マラヤーラム語 | シンハラ | チベット | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| a | として | a | – | 非 | – | a | – | a | – | a | – | a | KA | A. | – | ae | – | それか | カウンター | a | の | ཨ | – |
| そしてau | ː | 来て | の | a | e | 来て | 発明 | これ | KA | a | お手入れ | 牛 | KA | それか | KA | それか | KA | それか | 車 | b | に | – | – |
| これまで | c | 切る | |||||||||||||||||||||
| ǣ | ඈ | 押しつぶされた | |||||||||||||||||||||
| 私 | 私 | 農業 | それか | e | 何 | 私 | それか | e | 親族 | e | どうにか | e | k | E. | kiに | e | km | e | ki | e | は | ཨི | ཀི |
| マック | 私 | e | した | イード | 鍵 | e | 何 | e | 鍵 | 。 | キーです | E. | 台所 | これ | キー | これ | 鍵 | これ | 鍵 | e | 言った | – | – |
| の | の | u | Ku | おお | 悪い | その上 | 多くの | n | 料理 | A. | に | u | Ku | そこには | に | ou | Ku | 元 | c | g | 泣き言 | ཨུ | ཀུ |
| 胸 | u ̃ | 彼 | Ku | 1 | クーク | O. | co | n | 良い | u | 最もキャスティー | fue | coooh | ఊ | Co. | 男 | KO | スキン | 芯 | ඌ | 王冠 | – | – |
| そうです | そうです | e | WHO | – | – | – | – | – | – | – | – | A. | u | A. | K. | a | k | a | k | それ | – | – | |
| なっている | e | a | の | これ | WHO | a | に | a | それか | er | k | A. | k | A. | K. | ae | ケイ | tr | 中央 | それ | k | ཨེ | ཀེ |
| WHO | WHO | aye | cai | 3 | に1000文字以上があります | a | ca | ઐ | カイ | 4 | kha | 私 | 手 | 私。 | カイ | 私 | 手 | ഐ | 手 | ඓ | カイ | – | – |
| o | o | o | 何 | – | – | – | – | – | – | – | – | 一 | 親族 | O. | KO | o | KO | o | rect | o | どこ | – | – |
| あなたの | oː | O! | に | o | 採石場 | おお | co | o | KO | と | co | おお | co | おお | Co. | おお | KO | おお | co | o | どこ | ཨོ | ཀོ |
| で | で | o | カウ | 1 | カウ | a | c | ઔ | カラス | 運転 | kha | 違法 | 牛 | A. | 牛 | au | ki | 送信済 | カウン | o | カウ | – | – |
| μ | r̩ | 行 | クリー | 1 | 恵み | – | – | n | 縁起の良い | コリン | 良い | – | – | OW | KR | ery | 恵み | ഋഋ | キリスト | から | 農業 | – | – |
| ṝ | r̩ː | r | KR | 1 | いいえ | – | – | ૠ | 頂点 | ୠ | – | – | – | ౠ | – | – | – | ൠൠ | – | ඎ | クルー | – | – |
| ḷ | あたり | L. | 契約 | ঌ | 採石場 | – | – | – | – | ଌ | – | – | – | ఌ | 来て | ಌ | – | ഌഌ | cഌ | (d) [初め] | – | – | – |
| それ | ing | ॡ | 何 | ৡ | 採石場 | – | – | – | – | ୡ | – | – | – | ౡ | – | ೡ | – | ൡൡ | cൡ | (ඐ) | – | – | – |
標識を支払う [ 編集 | ソーステキストを編集します ]
| 番号 | デヴァナガリ | ベンガル語 | グルムキ | グジャラート語 | タミル語 | テルグ語 | カンナダ | マラヤーラム語 |
|---|---|---|---|---|---|---|---|---|
| 0 | ० | ০ | ੦ | ૦ | ೦ | ౦ | ೦ | ൦ |
| 初め | १ | ১ | ੧ | ૧ | ௧ | ౧ | ೧ | ൧ |
| 2 | २ | ২ | ੨ | ૨ | ௨ | ౨ | ೨ | ൨ |
| 3 | ३ | ৩ | ੩ | ૩ | ௩ | ౩ | ೩ | ൩ |
| 4 | ४ | ৪ | ੪ | ૪ | ௪ | ౪ | ೪ | ൪ |
| 5 | ५ | ৫ | ੫ | ૫ | ௫ | ౫ | ೫ | ൫ |
| 6 | ६ | ৬ | ੬ | ૬ | ௬ | ౬ | ೬ | ൬ |
| 7 | ७ | ৭ | ੭ | ૭ | ௭ | ౭ | ೭ | ൭ |
| 8 | ८ | ৮ | ੮ | ૮ | ௮ | ౮ | ೮ | ൮ |
| 9 | ९ | ৯ | ੯ | ૯ | ௯ | ౯ | ೯ | ൯ |
インドの作家の次の著作には、データ処理についてはUnicodeバージョン5.1で遭遇します。
- インドシェ・シュリフテン:ベンガリッシュ、チャクマ、デヴァナガリ、グジャラティ、グルミュキ、カンナダ、レプチャ、リンブ、マラヤラム、オリヤ、サジャレシッチ、シロティ・ナガル、タミリシュ、テルグ。
- 東南アジアの著作:バリ、ブギネシアン、チャム、カヤリー、クメール、ラオス、ミャンマー、ノイタイ、レジャン、スンダネーゼ、タイレ、タイ。
- 中央アジアの著作:チベット語、ファグスパ
- フィリピンの著作:Buid、Hanunóo、Tagalog、Tagbanuwa
複雑な表現アルゴリズムは、Unicodeのインドの著作の正しい表現を目的としています。
参照: 碑文;コンピューターにインドの著作を入力するためのキーボードレイアウト
- ジョージL.キャンベル: 世界の言語の大要。 ロンドン1991、ISBN 0-415-02937-6。
- ハンスジェンセン: 過去と現在の執筆。 ベルリン1969。
- Colin P. Masica: インド・アーリア語。 Cabbrbidge 1991、ISS PM 0-51-23420-4。
- ↑ シンハラ、古いものでのみ書かれています
Recent Comments