MultinúcleProtection -Wikipedia、無料百科事典
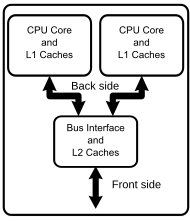


と Multinukプロセッサ これは、核と呼ばれる2つ以上の個別の処理ユニットを備えた単一の統合回路のマイクロプロセッサであり、それぞれがプログラム命令を読み取り、実行します。 [ 初め ] 命令は通常のCPU命令(追加、データの移動、分散型など)ですが、単一のプロセッサは同時に個別の核で命令を実行でき、複数のサブプロセスまたは他の並列コンピューティング手法を認めるプログラムの一般的な速度を向上させることができます。 [ 2 ] メーカーは通常、核を単一の統合回路チップ(マルチプロセッサまたはCMPチップと呼ばれる)または単一のチップパッケージのいくつかのチップに統合します。現在、ほぼすべてのパーソナルコンピューターで使用されているマイクロプロセッサは、マルチクロールです。
Multinukプロセッサは、単一の物理パッケージでマルチプロセシングを実装します。設計者は、調整された方法またはゆるい方法で、Multinukデバイスに核を取り付けることができます。たとえば、核はキャッシュを共有する場合と共有していない場合があり、共有メモリセンターまたはメッセージの間に通信方法を実装できます。核を相互接続するために使用される一般的なネットワークトポロジには、バス、リング、2次元メッシュ、横方向のバーが含まれます。複数の核の均一なシステムには、同一の核のみが含まれます。不均一なマルチクールシステムには同一ではない核があります(たとえば、big.littleには同じ一連の命令を共有する不均一な核がありますが、AMD加速処理ユニットには同じ命令セットを共有しない核があります)。単一のプロセッサシステムと同様に、いくつかの核システムの核は、VLIW、スーパースケール、ベクター、マルチプロセスなどのアーキテクチャを実装できます。
Multinukプロセッサは、一般、統合、ネットワーク、デジタル信号処理(DSP)およびグラフィックス(GPU)を含む多くのアプリケーションドメインで広く使用されています。コアカウントは数十になり、10,000以上の専門的なチップの場合もあります。 [ 3 ] また、スーパーコンピューター(つまり、チップのグループ)では、カウントは1,000万を超える可能性があります(ホストに加えて、合計で2,000万個の処理要素になる場合)。プロセッサ)。 [ 4 ]
Multinukプロセッサの使用によって得られたパフォーマンスの改善は、使用されるソフトウェアアルゴリズムとその実装に大きく依存します。特に、可能な利益は、複数の核で並行して同時に実行できるソフトウェアの割合によって制限されます。この効果は、Amdahlの法律によって説明されています。最良の場合には、So -Calededの恥ずべき並列問題は、核の数に近い加速係数を生成する可能性があります。これは、問題が各核のキャッシュに収まるほど十分に分割され、はるかに遅いメモリメモリの使用を回避することができます。ただし、プログラマーがリファクタリングに努力を投資しない限り、ほとんどのアプリケーションはあまり加速しません。 [ 5 ]
ソフトウェアの並列化は、継続的な重要な研究トピックです。マルチプロセッサアプリケーションの共和分は、ネットワークアーキテクチャ設計の柔軟性を提供します。並列モデル内の適応性は、これらのプロトコルを使用するシステムの追加特性です。 [ 6 ]
用語 [ 編集します ]
用語 マルチコア と デュアルコア それらは一般に何らかのタイプの中央処理ユニット(CPU)を参照しますが、時にはデジタル信号プロセッサ(DSP)とチップのシステムにも適用されます(SOC)。通常、この用語は、で製造されている複数の核のマイクロプロセッサを指すためにのみ使用されます。 同じ 積分回路メーター。同じパッケージの個別のマイクロプロセッサトロチャーは、通常、別の名前で呼ばれます。 複数のチップモジュール 。この記事では、で製造されたCPUに「マルチクロール」と「デュアルコア」という用語を使用しています。 同じ 特に示されない限り、統合回路。
Multinukシステムとは対照的に、用語 マルチCPU これは、複数の物理的に個別の処理ユニット(多くの場合、それらの間の通信を容易にする特別な回路が含まれている)を指します。
用語 多くの核 およびMultinuk 大規模 それらは、特に大量の核を持つさまざまな核からのアーキテクチャを説明するために時々使用されます(数十から何千もの核があります [ 7 ] )。 [ 8 ]
一部のシステムでは、単一のFPGAに配置された多くのソフトマイクロプロセッサコアを使用しています。各「核」は、「半導体の知的財産の中核」とCPU核と見なすことができます。
製造技術は改善され、個々のドアのサイズを縮小しますが、半導体ベースのマイクロエレクトロニクスの物理的限界が重要な設計上の懸念となっています。これらの物理的な制限は、熱放散とデータの同期の重大な問題を引き起こす可能性があります。 CPUのパフォーマンスを改善するために、他のいくつかの方法が使用されています。いくつかの方法 指導レベルでの並列性の (ILP)は、スーパースカラーチャネリングなど、多くのアプリケーションに適していますが、予測が難しいコードを含む他のアプリケーションには非効率的です。多くのアプリケーションは、方法によりよく適応します サブプロセスのレベルでの並列性の (TLP)、およびいくつかの独立したCPUは、システムの一般的なFTAを増加させるために一般的に使用されます。利用可能なより大きなスペース(洗練された製造プロセスによる)と、より大きなTLPの需要の組み合わせにより、Multinuk CPUが開発されました。
商業的なインセンティブ [ 編集します ]
いくつかの商業上の理由が、Multinukleアーキテクチャの開発を促進しています。何十年もの間、ICのデバイスあたりのコストを削減する統合回路領域(IC)を削減することにより、CPUのパフォーマンスを改善することができました。あるいは、同じ回路領域では、特に複雑な命令セット(CISC)のコンピューティングアーキテクチャに対して機能を向上させる設計でより多くのトランジスタを使用できます。また、1980年代のいくつかのメガヘルシオから2000年代初頭のいくつかのギガヘルシオまで、20世紀後半の数十年では数桁増加しました。
クロック速度の改善のリズムが低下するにつれて、一般的な処理パフォーマンスを改善するために、Multinukプロセッサの形での並列コンピューティングのより大きな使用が求められました。同じCPUチップでいくつかの核が使用されたため、2つ以上の核を備えたCPUチップの販売が改善される可能性があります。たとえば、Intelはクラウドコンピューティング研究のための48セントのプロセッサを生産しています。各コアにはX86アーキテクチャがあります。 [ 9 ] [ 十 ]
技術的要因 [ 編集します ]
コンピューターメーカーは、離散CPUを使用して対称マルチプロセッシング設計(SMP)を長い間実装してきたため、複数の核プロセッサアーキテクチャとソフトウェアサポートの実装に関連する問題はよく知られています。
そのほか:
- アーキテクチャを変更せずに実証済みの処理コア設計を使用すると、設計リスクが大幅に減少します。
- 汎用プロセッサの場合、Multinukプロセッサの動機の多くは、運用頻度を増やすことにより、プロセッサのパフォーマンスの向上の大幅な減少から得られます。これは、3つの主な要因によるものです。 [ 11 ]
- 彼 メモリウォール ;プロセッサとメモリの速度の間のギャップの増大。これにより、実際には、メモリの遅延をマスクするためにキャッシュサイズが大きくなります。これは、メモリ帯域幅がパフォーマンスのボトルネックではない限りのみに役立ちます。
- 彼 ILP壁 ;単一のパフォーマンスコアプロセスを占有するために、単一の命令の流れで十分な並列処理を見つけることの困難が増えています。
- 彼 パワーウォール ;運転頻度の各要因が増加すると、指数関数的に増加する(したがって、指数関数的に増加する熱も生成する)エネルギーを消費する傾向があります。この増加は、同じロジックに小さなトレースを使用することにより、プロセッサを「削減」することができます。彼 パワーウォール 製造上の問題、システムの設計、および実装を引き起こします。 記憶と壁 の ILP 。
一般的な使用プロセッサに定期的なパフォーマンスの改善を提供し続けるために、IntelやAMDなどのメーカーは複数の核設計に頼り、一部のアプリケーションやシステムでのより高いパフォーマンスのために製造コストを犠牲にしています。 Multinuk Architecturesが開発されていますが、代替案も開発されています。確立された市場の特に強力な競争相手は、チップ内の周辺機能の最大の統合です。
利点 [ 編集します ]
同じDIEにおける複数のCPU核の近接により、キャッシュ回路は、信号がチップの外を移動する必要がある場合、可能なよりもはるかに高い時計速度で機能することができます。単一のチップでのCPU等価物の組み合わせにより、キャッシュ照会操作のパフォーマンスが大幅に向上します(代替:バス調査)。一言で言えば、これは、異なるCPUの間の兆候がより短い距離を移動するため、したがって、それらの兆候が少ないほど低下することを意味します。これらの高品質の信号により、個々のシグナルが短くなり、頻繁に繰り返す必要はないため、一定期間でより多くのデータを送信できます。
マトリックスがパッケージに物理的に収まると仮定すると、Multinukle CPU設計では、いくつかのチップのSMP設計よりもはるかに少ないスペースが必要です。さらに、ダブルコアプロセッサは、主にチップの外部の信号を高めるために必要なエネルギーが低いため、2つのシングルコアプロセッサよりも少し少ないエネルギーを使用します。さらに、核は、L2キャッシュメモリやフロントバス(FSB)とのインターフェースなどのいくつかの回路を共有しています。利用可能なシリコンマトリックスエリアの競争力のある技術に関しては、Multinuk設計は、CPU核ライブラリの実証済みの設計を使用し、新しいより幅の広い核設計を考案するよりも低リスクエラーリスクのある製品を生産することができます。さらに、より多くのキャッシュを追加すると、収量が減少します。
Multinukoチップは、エネルギーが少ないほど高いパフォーマンスを可能にします。これは、バッテリーで動作するモバイルデバイスの重要な要素になる可能性があります。 Multinuk CPUの各核は一般にエネルギー効率が高いため、チップは単一の大きなモノリシック核を持つよりも効率的になります。これにより、エネルギーが少なくなると、より高いパフォーマンスが可能になります。ただし、これの課題は、並列コードを書き込む追加の過負荷です。 [ 12番目 ]
短所 [ 編集します ]
Multinukプロセッサが提供するコンピューターリソースの使用を最大化するには、オペレーティングシステム(SO)と既存のアプリケーションソフトウェアの両方で調整が必要です。さらに、アプリケーションのパフォーマンスを向上させるMultinukプロセッサの能力は、アプリケーション内のいくつかのサブプロセスの使用に依存します。
Multinukチップを統合すると、チップの生産量が減少する可能性があります。また、より低い密度の単一の核の設計よりも熱的に投与することが困難です。 Intelは、単一のマトリックスに2つのデュアル2つの2つを統一キャッシュと組み合わせることにより、4つのデュアル2つのデザインを作成することにより、この最初の問題を部分的に打ち消しました。したがって、単一のマトリックスで4つのコアを生成するのではなく、2つのダブルコアマトリックスを使用できます。単一のダイで、4つのコアCPUを生成するための4つの作業が必要です。建築の観点からは、最終的には、単一のCPU設計が複数の処理核よりもシリコン表面積をよりよく利用できるため、このアーキテクチャへの開発のコミットメントは陳腐化のリスクにつながる可能性があります。最後に、システムパフォーマンスの制限は唯一の制限ではありません。システムの同じシステムとメモリの帯域幅を共有する2つの処理核は、現実世界のパフォーマンスの利点を制限します。 2009年の報告書では、Jun博士または単一の核が記憶帯域幅が限られていることに近い場合、2つの核に移動すると30%から70%への改善が得られることを示しました。メモリ帯域幅が問題でない場合、90%の改善が予想されます。しかし、Amdahlの法律はこの声明を疑います。 [ 13 ] CPU間の通信が制限要因である場合、2つのCPUを使用して単一の核でより速く実行されるアプリケーションが可能であり、100%以上の改善としてカウントされます。
トレンド [ 編集します ]
数百または数千の核を持つプロセッサが理論的に可能になるため、プロセッサの開発の傾向は、ますます多くの核に向かっています。 [ 14 ] さらに、複数のサブプロセス、チップメモリ、特別な目的の「不均一」(非対称」(非対称)コアと組み合わされたMultinukチップは、特にマルチメディア、認識、ネットワークアプリケーションの処理において、より大きなパフォーマンスと効率の向上を約束します。たとえば、Big.little核には、高性能コア(「Big」と呼ばれる)と低消費核(「Little」と呼ばれる)が含まれます。また、高度な微細または超微細な穀物エネルギー管理と動的電圧と周波数スケーリング(つまり、ラップトップとポータブルマルチメディアプレーヤー)を使用したワット性能に焦点を当てたエネルギー効率の改善に向かう傾向があります。
多くの核のために最初から設計されたチップ(単一コアデザインから進化する代わりに)は、多くの核のデザインと呼ばれることもあり、定性的な違いを強調しています。
建築 [ 編集します ]
Multinuk Architectureの核の組成とバランスは、非常に多様性を示しています。一部のアーキテクチャは、一貫して繰り返されるコアデザイン(「均質」)を使用しますが、他のアーキテクチャは異なる核の組み合わせを使用し、それぞれが異なる「不均一な」関数に最適化されています。
いくつかの核が実装され、開発者のプログラミングスキルと、デバイスの前でのアプリケーションとインタラクティブ性に関する消費者の期待の両方を大幅に統合する方法。 [ 15 ] オクタコアとして発表されたデバイスは、それが次として発表された場合にのみ独立した核を持つことになります 真のオクタコア 、または同様のスタイル、単に2つの4コアセットではなく、それぞれ固定された時計速度があります。 [ 16 ] [ 17 ]
Rick Merrittの「CPUデザイナーが将来のMultinukを議論する」という記事、EE Times 2008、 [ 18 ] これらのコメントを含めます:
チャック・ムーア[。 ..]は、さまざまな特別な核を使用して、高レベルのアプリケーションプログラミングインターフェイスによってプログラムされたモジュラーソフトウェアを実行するために、コンピューターが携帯電話である必要があることを提案しました。[…]ルネサスのシニアチーフエンジニアである西川島は、一般的に同意しました。彼は、コンサートで働く多くの特別な核の携帯電話の使用は、複数の核の将来の設計のための良いモデルであると示唆しました。
[…]スタートアップティレラの創設者兼エグゼクティブディレクターであるアナントアガルワルは、反対の視点を取りました。彼は、単純なソフトウェアモデルを維持するために、マルチコアチップは一般的な目的センターの均一なコレクションでなければならないと述べました。
ソフトウェア効果 [ 編集します ]
Antivirusアプリケーションの古いバージョンは、スキャンプロセスの新しいサブプロセスを作成できますが、GUIサブプロセスはユーザーコマンドを期待します(たとえば、スキャンをキャンセルします)。そのような場合、唯一のサブプロセスがすべての重い作業を行い、いくつかの核で均一に機能することができないため、Multinukアーキテクチャはアプリケーション自体にとってほとんど利点がありません。真にマルチプロセスコードプログラミングには、サブプロセスの複雑な調整が必要になることが多く、サブプロセス間の共有データの処理に織り込まれているため、微妙なエラーを簡単に導入し、見つけるのが困難です(サブプロセスの安全性を参照)。したがって、このコードは、破損したときに単一のサブプロセスのコードよりも精製するのがはるかに困難です。コンピューターハードウェアの最大使用に対する消費者の需要の相対的な希少性のために、消費者レベルでアプリケーションを書き込む動機の欠如が認識されています。さらに、ビデオコーデックで使用されるエントロピーコーディングアルゴリズムのデコードなどのシリアルタスクは、生成された各結果を使用してエントロピーデコードアルゴリズムの次の結果を作成するのに役立つため、並行することは不可能です。
プロセッサクロック速度の大幅な追加の増加をもたらす深刻な熱およびエネルギー消費の問題に由来するMullinukチップの設計に重点が向いていることを考えると、これらの新しいチップを利用するためにソフトウェアをマルチプロセスにすることができる範囲は、将来のコンピューターのパフォーマンスにおける最大の個人制限です。開発者が複数の核から提供されるリソースを最大限に活用するためにソフトウェアを設計できない場合、最終的に卓越したパフォーマンスルーフに到達します。
テレコミュニケーション市場は、データルートとコントロールプレーン用のこれらのマルチヌクレイプロセッサの非常に急速な採用があったため、データロードパッケージの新しい処理設計を並行して必要とした最初の市場の1つでした。これらのMPUは交換します [ 19 ] マイクロコードまたは独自のPicocodeに基づいた従来のネットワークプロセッサに。
並列プログラミング手法は、いくつかの核から直接恩恵を受けることができます。 Cilk Plus、OpenMP、OpenHMPP、FastFlow、Skandium、MPI、Erlangなどの既存の並列プログラミングモデルは、Multinukプラットフォームで使用できます。 Intelは、TBBと呼ばれるC ++の並列性のための新しい抽象化を導入しました。その他の研究には、Codeplay Sieve System、Cray’s Chapel、Sun’s Fortress、IBMのX10が含まれます。
Multinuko処理は、最新の計算ソフトウェアの開発能力にも影響を与えています。新しい言語でプログラムする開発者は、最新の言語がマルチクルコ機能と互換性がないことを発見できます。これには、C#などの最新言語よりも速く数学的計算を実行するCやFortranなどの言語で記述されたコードにアクセスするために、数値ライブラリを使用する必要があります。 IntelのMKLとAMDのACMLは、これらの母国語で書かれており、Multinuk処理を活用しています。特に異なるパフォーマンス特性がある場合、プロセッサ間のアプリケーションのワークロードのバランスは問題になる可能性があります。この問題に対処するためのさまざまな概念モデルがあります。たとえば、調整言語とプログラムの構築ブロック(プログラミングライブラリまたは高次関数)を使用しています。各ブロックには、プロセッサの種類ごとに異なるネイティブ実装があります。ユーザーはこれらの抽象化を使用してプログラムするだけで、インテリジェントコンパイラがコンテキストに応じて最適な実装を選択します。 [ 20 ]
同意管理は、並列アプリケーションの開発において中心的な役割を獲得します。並列アプリケーションの設計における基本的な手順は次のとおりです。
- 分割
- 設計のパーティションの段階は、並行して実行の機会を提示することを目的としています。したがって、注意は、多くの小さなタスクを定義して、問題の詳細な分解と呼ばれるものを生成することに焦点を当てています。
- コミュニケーション
- パーティションによって生成されたタスクは、同時に実行されることを目的としていますが、一般に、独立して実行することはできません。タスクで実行される計算には、通常、別のタスクに関連付けられたデータが必要です。次に、計算を継続できるように、タスク間でデータを転送する必要があります。この情報フローは、設計の通信フェーズで指定されています。
- 凝集
- 第3段階では、開発は要約からコンクリートに移行します。開発者は、ある種の並列コンピューターで効率的に実行されるアルゴリズムを取得するために、パーティションおよび通信フェーズで行われた決定を確認します。特に、開発者は、パーティション化段階で識別されたタスクを組み合わせて組み合わせて、それぞれが大きいサイズのタスクの数が少ないかを検討します。また、データと計算を複製する価値があるかどうかを決定します。
- 地図作成
- 並列アルゴリズムの設計の4番目と最後の段階で、開発者は各タスクが実行される場所を指定します。このマッピングの問題は、自動タスクプログラミングを提供するモノプロセッサや共有メモリコンピューターでは発生しません。
一方、サーバー側では、多くのユーザーが同時にサイトに接続し、独立した実行スレッドを持つことができるため、Multinukプロセッサは理想的です。これにより、Webサーバーとアプリケーションサーバーがパフォーマンスを向上させることができます。
ライセンス [ 編集します ]
サプライヤーは、いくつかの「プロセッサ」ソフトウェアのライセンスを取得できます。 「プロセッサ」は単一の核または核の組み合わせで構成できるため、これは曖昧さを生成できます。
統合アプリケーション [ 編集します ]

統合コンピューティングは、「従来の」PCのそれ以外のプロセッサテクノロジーの分野で動作します。ここにも同じ技術的衝動がここにも当てはまります。実際、多くの場合、アプリケーションは、タスクを異なるプロセッサ間で簡単に分割できる場合、「自然に」Multinukテクノロジーに適応します。
さらに、組み込まれたソフトウェアは一般に特定のハードウェアバージョン用に開発されているため、ソフトウェアの移植性の問題、継承コード、または独立した開発者のサポートがビジネスやPCコンピューターサイエンスの場合よりも重要ではありません。その結果、開発者が新しいテクノロジーを採用することが容易であり、その結果、より多様なアーキテクチャとMultinuk加工サプライヤーがあります。
ネットワークプロセッサ [ 編集します ]
2010年には、Freescale、Cavium Networks、Wintegra、Broadcomなどの企業が8つのプロセッサを備えたすべての製造製品など、Multinukoプロセッサが主要な現在になりました。システム開発者にとって、重要な課題は、対称マルチプロセッシング(SMP)のオペレーティングシステムに固有のパフォーマンスの制限にもかかわらず、これらのデバイスのすべての核を活用してシステムレベルで最大のネットワークパフォーマンスを実現する方法です。 6Windなどの企業は、ネットワークデータプレーンがネットワークオペレーティングシステムの外側の高速ルート環境で実行されるように設計されたポータブルパッケージ処理ソフトウェアを提供しています。 [ 23 ]
デジタル信号処理 [ 編集します ]
デジタル信号処理では、同じ傾向が適用されます。テキサスインスツルメンツには、3つのコアのTMS320C6488と4つのCMS320C5441があり、4つのCurningのMSC8144と6つのCorneoのMSC8156が無料です(両方とも8センターの後継者に取り組んでいると宣言しました)。最新のチケットには、Storm-1ファミリーが含まれます Stream Processors、Inc チップごとに40および80 ALUの一般的な目的があり、すべてがSIMDとしてプログラム可能であり、300個のプロセッサを1回のDIEに備えたPicoChipエンジンは、通信アプリケーションに焦点を当てています。
不均一なシステム [ 編集します ]
システムが複数の種類のプロセッサまたは核を使用する不均一なコンピューティングでは、Xilinx Zynq Ultrascale+ MPSOCには4コアARM皮質A53と2コア皮質-R5 ARMがあります。 OpenAmpなどのソフトウェアソリューションは、プロセッサ間の通信を支援するために使用されます。
モバイルデバイスはARM Big.little Architectureを使用できます。
ハードウェアの例 [ 編集します ]
商業 [ 編集します ]
- Adaptva Epiphanyは、16コアバージョンのみが市販されていますが、チップ内の最大4096プロセッサを可能にする多くの核のプロセッサアーキテクチャです。
- aeroflex gaisler leon3、断層耐性バージョンにも存在するMultinuk Spart。
- Ageia Physx、Multinuk Physics Processing Unit。
- アンブリックAM2045、336コアの非常に並列プロセッサマトリックス(MPPA)
- AMD
- Serie A、2、3、4の核の加速プロセッサユニット(APU)。
- Athlon 64 FXおよびAthlon 64 X2 Desktopプロセッサと2つの核。
- Athlon IIデスクトッププロセッサ、デュアル、トリプル、クアッドコア。
- FXシリーズデスクトッププロセッサ、4、6、8核。
- 1、2、4、6、8、12、および16のセンターのワークステーションのOpteronプロセッサ。
- フェノムプロセッサ、2、3、4個の核。
- Phenom II、ダブル、トリプル、四重、6つのコアデスクトッププロセッサ。
- 基本的なプロセッサは、1つ、2つ、4つの核を播種します。 [ 24 ]
- Turionラップトッププロセッサ、1つと2つの核。
- Ryzen、統合されたプラットフォームプロセッサ、2、4、6、8、16、24、32、および64の2つのモバイルおよびデスクトップ。
- EPYC、4、8、12、16、24、32、64のサーバー、および統合プロセッサ。
- Radeon y Firestream GPU/GPGPU。
- アナログデバイスBlackfin BF561、対称デュアルコアプロセッサ
- ARM MPCOREは、ARM11 MPCOREおよびARM Cortex-A9 MPCOREプロセッサ核用の完全に合成可能なMultinukコンテナで、統合アプリケーションと高性能エンターテイメント用に設計されています。
- Assocs modemx、最大128の核、ワイヤレスアプリケーション。
- Azul Systems
- 2005年に発売された24コアプロセッサであるVega 1。
- 2006年に発売された48コアプロセッサであるVega 2。
- 2008年に発売された54コアプロセッサであるVega 3。
- Broadcom Sibyte SB1250、SB1255、SB1455; BCM 2836 FOR -NUCLEI(RaspberryPi2用に設計)
- ケイデンスデザインシステムTensilica Xtensa LX6、Espressif SystemsのESP32でダブルコア構成で利用可能
- ClearSpeed
- CSX700、192 Nucleiのプロセッサ、2008年に発売されました(32/64ビットのフローティングcom睡、Integer ALU)。
- Cradle Technologies CT3400 Y CT3600、Ambos DSPMultinúcleo。
- Cavium Networks Octeon、32コアのMPS MIPS。
- プロセッサ コヒーレントログ HX3100 、100コアDSP/GPPプロセッサ。
- フリースケール半導体QORIQシリーズプロセッサ、最大8個の核、Power ISA MPU。
- Hewlett-Packard PA-8800およびPA-8900、デュアル上昇PA-RISCプロセッサ。
- IBM
- Double -Core PowerPCプロセッサであるPower4は、2001年に発売されました。
- 2004年に発売されたダブルコアPowerPCプロセッサであるPower5。
- 2007年に発売されたダブルコアPowerPCプロセッサであるPower6。
- 4.6.8コアのPowerPCプロセッサであるPower7は、2010年に発売されました。
- 12コアPowerPCプロセッサであるPower8は、2013年に発売されました。
- 12または24の核のPowerPCプロセッサであるPower9が2017年に発売されました。
- 2021年に発売された15または30コアのPowerPCプロセッサであるPower10。
- Apple Power Mac G5で使用されるダブルコアPowerPCプロセッサであるPowerPC 970 MP。
- Xenon、Microsoft Xbox 360ゲームコンソールでSMT容量を使用した3コアPowerPCマイクロプロセッサ。
- 2008年に発売された4コアZ/アーキテクチャプロセッサであるZ10。
- 4コアZ/アーキテクチャプロセッサであるZ196は、2010年に発売されました。
- 6コアZ/アーキテクチャプロセッサであるZEC12は、2012年に発売されました。
- Z13、8コアZ/アーキテクチャプロセッサが2015年に発売されました。
- 2017年に発売された10コアZ/アーキテクチャプロセッサであるZ14。
- 2019年に発売された12個の核のZ/アーキテクチャプロセッサであるZ15。
- 武器、Procesador Z / Architecture de Ochonúcleos、Lanzado en 2021。
- infineon
- インテル
- 1つのコア、2つのコア、4つのコア、8、12、および16の原子プロセッサ、ネットブック、ネットトップ、統合アプリケーション、モバイルインターネットデバイス(MID)のための核。 [ 25 ]
- Atom SoC(チップ中のシステム)、単一コアプロセッサ、2つの核、およびスマートフォンとタブレット用の4つの核。 [ 26 ]
- Celeron、エントリー市場の経済/レベルのための最初のデュアルコアプロセッサ(および後の4コア)。 [ 27 ] [ 28 ]
- コアデュオ、ダブルコアプロセッサ。 [ 29 ]
- コア2デュオ、ダブルコアプロセッサ。 [ 30 ]
- コア2クアッド、マルチチップモジュールに詰め込まれた2つのデュアルダンプ。 [ 最初に30 ]
- Core i3、Core i5、Core i7、Core i9、2、4、6、8、12、14、16、18の核のプロセッサのファミリー、Core 2 DuoとCore 2 Quadの後継者。 [ 32 ]
- イタニウムプロセッサ、1つのヌクレウス、2コア、4つのヌクレイ。 [ 33 ]
- 基本市場のペンティウムプロセッサ、1、2、4の核。 [ 34 ]
- Teraflops Research Chip(Polaris)は、3.16 GHzのプロセッサプロトタイプ80コアであり、当初は2011年に発売されると宣言しました。 [ 35 ]
- Xeon double、Quadruple、6、8、12、14、15、18、20、22、24、28、32、48 – 、および56コアプロセッサ。 [ 36 ] [ 37 ] [ 38 ] [ 39 ] [ 40 ] [ 41 ]
- 57、60、61、64、68、72コアのXeon Phiプロセッサ。 [ 42 ] [ 43 ]
- Intellasys
- Seaforth 40C18、40コアプロセッサ。 [ 44 ]
- Seaforth24、チャールズH.ムーアが設計した24コアプロセッサ。
- カレイ
- MPPA-256、256 Nuclei Processor、2012年に発売された(256の使用可能なVliw Nuclei、Network-on-chip(NOC)、FPUは32/64ビットのIEEE 754と互換性があります)
- Microsistemas netlogic
- XLP、4線MIPS64プロセッサ、32コア。
- XLR、4ワイヤ、8コアMIPS64プロセッサ。
- XLS、4線、8コアMIPS64プロセッサ。
- nvidia
- RTX 3090(10496NúcleosCuda、NúcleosGPGPU; [ 3 ] さらに、他のより専門的な核)。
- 視差プロペラP8x32、8コアマイクロコントローラー。
- DSPおよびワイヤレスデバイスによるPicochip PC200 200〜300シリーズ。
- 複数のHALは、16から256の核、共有メモリL1、ハードウェア同期プロセッサと密接に結びついています。
- Rapport Kilocore KC256、8ビットPowerPCおよび256 “処理要素を備えた257コアのマイクロコントローラー。
- sicortex「sicortexノード」には、単一のチップに6つのMIPS64核があります。
- https://en.wikipedia.org/wiki/sifive “rel =” mw:extlink “title =” sifive “class =” cx-link “linkid =” 513 “> sifive
- Sony / IBM / Toshiba Cell Processor、一般的な使用のためのPowerPC核を備えた9コアプロセッサと、Sony PlayStation 3で使用されるベクトル操作に特化した8つのSPU(Synergistic Processing Unit)が最適化されています。
- サンマイクロシステム
- Majc 5200、Nucleus Vliwプロセッサ。
- UltrasParc IVおよびUltrasParc IV+、デュアルコアプロセッサ。
- UltrasParc T1、8コアおよび32ワイヤープロセッサ。
- UltrasParc T2、8コアプロセッサと64の同時サブプロセス。
- UltrasParc T3、16のコアと128の同時サブプロセスのプロセッサ。
- SPPARC T4、8コアプロセッサと64の同時サブプロセス。
- SPPARC T5、16のコアと128の同時サブプロセスを備えたプロセッサ。
- サンウェイ
- テキサスの楽器
- TMS320C80 MVP、5階建てのマルチメディアビデオプロセッサ。
- TMS320TMS320C66、2,4,8核DSP。
- ティレラ
- Tile64、64コア32ビットプロセッサ。
- タイル-GX、72コア、64ビットプロセッサ。
- XMOSソフトウェアが定義されたシリコンクアッドコアXS1-G4。
無料 [ 編集します ]
アカデミック [ 編集します ]
- MIT、プロセッサ 生 16コアの
- カリフォルニア大学、デイビス、単純なプロセッサの非同期マトリックス(ASAP)
- 36核610MHzできるだけ早く
- AP2としての167 1.2GHz核
- ワシントン大学プロセッサ Wavescalar
- テキサス大学、オースティン、旅行プロセッサ
- エプマプロセッサ、スウェーデン、リンセーピ大学
- UC Davis、キロコア、32 nmのIBMプロセスで1.78 GHzの1000コアプロセッサ。 [ 45 ]
参照ポイント [ 編集します ]
Multinukプロセッサの研究開発は、多くのオプションを比較することが多く、これらの評価を支援するために基準点が開発されています。既存の参照ポイントには、異種システム用のSplash-2、Parsec、およびCosmicが含まれます。 [ 46 ]
参照してください [ 編集します ]
参照 [ 編集します ]
- ↑ ラウズ、マーガレット(2007年3月27日)。 «定義:マルチコアプロセッサ» 。 TechTarget。から提出 オリジナル 2010年8月5日 。 2013年3月6日に相談しました 。
- ↑ シャウアー、ブライアン。 «マルチコアプロセッサ – 必要性» 。から提出 オリジナル 2011年11月25日。
- ↑ a b スミス、ライアン。 «nvidiaはGeForce RTX 30シリーズを発表します:RTX 3080&RTX 3090から始まるゲームのAmpere» 。 www.anandtech.com 。 2023年2月4日に取得 。
- ↑ «Sunway Taihulight -Sunway MPP、Sunway SW26010 260C 1.45GHz、Sunway | Top500» 。 www.top500.org 。 2020年9月15日に取得 。
- ↑ スレマン、エイター(2011年5月20日)。 «並列プログラミングをハードにするものは何ですか?» 。未来派。から提出 オリジナル 2011年5月29日 。 2013年3月6日に相談しました 。
- ↑ デュラン、A(2011)。 «OMPSS:不均一なマルチコアアーキテクチャをプログラミングするための提案»。 並列処理文字 21 (2):173-193。 doi: 10.1142/s0129626411000151 。
- ↑ スコア、デビッド(2017年11月)。 «2,048コアのページ-SC2はGreen500レコードを設定します» 。ウィキチップ。
- ↑ Vajda、András(10 de Junio de 2011)。 多くのコアチップのプログラミング 。スプリンガー。 p。 3。 ISBN 978-1-4419-9739-5 。
- ↑ シュアウト、ライアン(2009年12月2日)。 «Intelは48コアx86プロセッサをシングルチップクラウドコンピューターとして表示します» 。から提出 オリジナル EL 2016年1月5日 。 2015年5月17日に取得 。
- ↑ «Intelは48コアクラウドコンピューティングシリコンチップを発表します» 。 BBC 2009年12月3日 オリジナル 2012年12月6日 。 2013年3月6日に相談しました 。
- ↑ パターソン、デビッドA.「コンピューターアーキテクチャの未来。」 Berkeley EECS Annual Research Symposium(Bears)、米国カリフォルニア州バークレーカレッジの大学。 2006年。
- ↑ スレマン、エイター(2011年5月19日)。 «Q&A:マルチカアはエネルギーを節約しますか?あまり。” 。から提出 オリジナル 2012年12月16日 。 2013年3月6日に相談しました 。
- ↑ NI、6月。 «医療画像のためのマルチコアコンピューティングのテクノロジーを有効にする» 。から提出 オリジナル 2010年7月5日 。 2013年2月17日に取得 。
- ↑ クラーク、ジャック。 «Intel:1,000コアチップが実行可能な理由» 。 zdnet 。から提出 オリジナル 2015年8月6日 。 2015年8月6日に取得 。
- ↑ クディカラ、チャクリ(2016年8月27日)。 «オクタコアの携帯電話に関するこれらの5つの神話は実際に真実です» 。 ギズボット 。
- ↑ «MediateckがMT6592 True Octa-Coreモバイルプラットフォームを発売します» 。 MediaTek 2013年11月20日。
- ↑ «オクタコアプロセッサとは» 。サムスン。 «Galaxyスマートフォンは、オクタコア(2.3GHz Quad + 1.6GHz Quad)またはクアッドコア(2.15GHz + 1.6GHzデュアル)プロセッサで実行されます»。
- ↑ メリット、リック(2008年2月6日)。 «CPUデザイナーがマルチコアの未来を議論する» 。 EEタイム。から提出 オリジナル 2012年11月14日 。 2013年3月6日に相談しました 。
- ↑ «マルチコアパケット処理フォーラム» 。から提出 オリジナル 2009年12月21日。
- ↑ ジョン・ダリントン; Moustafa Ghanem; Yike Guo; (1996)への翼。 «不均一な並列コンピューティングのガイド付きリソース組織»。 Journal of High Performance Computing 4 (1):13-23。
- ↑ ブライト、ピーター(2015年12月4日)。 «Windows Server 2016コアごとに移動し、ソケットごとではなくライセンス» 。 Ars Technica 。コンデナスト。から提出 オリジナル 2015年12月4日 。 2015年12月5日に相談しました 。
- ↑ 比較: «Oracle Technology製品のライセンス» 。 OMT-CO運用管理技術コンサルティングGMBH。 Archivado Desde オリジナル 2014年3月21日 。 2014年3月4日に相談しました 。
- ↑ «仮想サービスルーター| VPE | vsecgw | VCSR | vcgnat» 。 6ウィンド (アメリカ英語で) 。 2023年2月4日に取得 。
- ↑ «sempron™3850 apu with radeon™R3シリーズ| amd» 。 AMD 。から提出 オリジナル 2019年5月4日 。 2019年5月5日に取得 。
- ↑ «Intel®Atom™プロセッサCシリーズ製品仕様» 。 ark.intel.com (英語で) 。 2019年5月4日に取得 。
- ↑ «Intel®Atom™プロセッサZシリーズ製品仕様» 。 ark.intel.com (英語で) 。 2019年5月4日に取得 。
- ↑ «Intelはデュアルコアセレロンプロセッサを準備します» 。 2007年10月11日 オリジナル 2007年11月4日 。 2007年11月12日に相談しました 。
- ↑ «Intel®Celeron®プロセッサJシリーズ製品仕様» 。 ark.intel.com (英語で) 。 2019年5月4日に取得 。
- ↑ «以前はヨナ» 。 ark.intel.com 。 2019年5月4日に取得 。
- ↑ «以前の製品» 。 ark.intel.com 。 2019年5月4日に取得 。
- ↑ «以前のケントフィールド» 。 ark.intel.com 。 2019年5月4日に取得 。
- ↑ «Intel®Core™Xシリーズプロセッサ製品仕様» 。 ark.intel.com (英語で) 。 2019年5月4日に取得 。
- ↑ «Intel®Itanium®プロセッサ製品仕様» 。 ark.intel.com (英語で) 。 2019年5月4日に取得 。
- ↑ «Intel®Pentium®プロセッサDシリーズ製品仕様» 。 ark.intel.com (英語で) 。 2019年5月4日に取得 。
- ↑ ザザイアン、マイク(2006年9月26日)。 «Intel:2011年までに80コア» 。から提出 オリジナル 2006年11月9日 。 2006年9月28日に取得 。
- ↑ Kowaliski、Cyril(2014年2月18日)。 «Intelが15コアXeon E7 V2プロセッサをリリースします» 。から提出 オリジナル 2014年10月11日。
- ↑ «Intel XeonプロセッサE7 V3ファミリ» 。インテルから提出 オリジナル 2015年7月7日。
- ↑ «Intel XeonプロセッサE7 V2ファミリ» 。インテルから提出 オリジナル 2015年7月7日。
- ↑ «Intel XeonプロセッサE3 V2ファミリ» 。インテルから提出 オリジナル 2015年7月7日。
- ↑ «Intelは、最大56コアと112のスレッドでXeon Platinum CPUを披露します» 。 TechSpot (アメリカ英語で) 。 2019年5月4日に取得 。
- ↑ PDF、ダウンロード。 «第2世代intel®xeon®スケーラブルプロセッサブリーフ» 。 インテル (英語で) 。 2019年5月4日に取得 。
- ↑ «Intel®XeonPhi™X100製品ファミリ製品仕様» 。 ark.intel.com (英語で) 。 2019年5月4日に取得 。
- ↑ «Intel®XeonPhi™72×5プロセッサファミリ製品仕様» 。 ark.intel.com (英語で) 。 2019年5月4日に取得 。
- ↑ コール、バーナード(2008年9月24日)。 «40コアプロセッサが発表されたフォースベースのIDEツールを備えた» 。
- ↑ チャコス、ブラッド(2016年6月20日)。 «キロコアに会い、1,000コアプロセッサが非常に効率的で、AAバッテリーで実行できます» 。 PCの世界 。から提出 オリジナル 2016年6月23日。
- ↑ «宇宙の異質なマルチプロセッサベンチマークスイート» 。から提出 オリジナル 2015年7月3日。
その他の測定値 [ 編集します ]
- 。第17回並列および分散処理技術とアプリケーションに関する国際会議(PDPTA-11)。 2011年7月。551-557ページ。
- 。 20回目のIEEE国際会議に関する高性能コンピューターアーキテクチャ(HPCA-14)ワークショップ。 2014年2月。 doi: 10.13140/rg.2.1.3051.9207 。
外部リンク [ 編集します ]
Recent Comments